Este tópico permite que os membros do Grupo de IA da UnB (Brasília) estudem coletivamente (em reuniões presenciais e on-line) a lição 2 (parte 1) do curso fastai, mas de um jeito aberto para ajudar também pelas questões, respostas e pelos recursos publicados todos os leitores em português interessados em DL.
[ 26:49 ] Training a model (como escolher o LR com learn.recorder.plot())
[ 29:38 ] Interpretation (compreendendo as previsões com maior loss (incorretas, mas o modelo está confiante ou aquelas em que o modelo não está confiante)) and ImageCleaner() (um aplicativo dentro do Jupyter notebook para apagar imagens mal rotuladas, sem ligação com a natureza do modelo, imagens duplicadas ou imagens com vieses)
[ 37:36 ] Putting your model in production (use o CPU for inference)
Guidelines for assigning num_workers to DataLoader (“num_workers is the number of CPUs to use”, “num_workers equal 0 means that it’s the main process that will do the data loading when needed, num_workers equal 1 is the same as any n, but you’ll only have a single worker, so it might be slow”).
ipywidgets (creation of aplications inside a Jupyter Notebook)
Após treinar o classificador, usando a função ImageCleaner() do mesmo notebook para apagar imagens mal rotuladas, sem ligação com a natureza do modelo, imagens duplicadas ou imagens com vieses.
Criando um aplicativo Web desse classificador (veja o tutorial).
Há algumas diferenças entre o código do video da lição 2 sobre:
Interpretation [29:38]: como apagar imagens mal rotuladas, sem ligação com a natureza do modelo, imagens duplicadas ou imagens com vieses (função ImageCleaner() e não FileDeleter())
Putting your model in production [37:36]: como obter uma previsão a partir de uma imagem (não precisa de criar um databunch específico, só usando learn.predict())
[ EDIT 31/10/2019 ]: havia problemas de atualização no tutorial publicado neste post. Por isso, eu publiquei meu proprio post (muito, muito) inspirado do tutorial do @weltonrodrigo (obrigado a ele).
Como criar um Web app tipo classificador usando um modelo fastai e colocá-lo no Heroku?
Para baixar um dataset de uma competição Kaggle, a gente precisa cadastrar-se no site, aceitar as regras da competição e usar a API Kaggle. No início deste notebook lição3-planeta.ipynb, há todas as informações e códigos necessários por isso. Também, o Jeremy explicou como fazer isso na versão de 2018 do curso (video).
Uma outra opção para baixar um dataset do kaggle ou de qualquer site é usar CurlWget (Chrome extension):
Eu esto recebendo esse erro no fim da criação do aplicativo. Já fiz as modificações que o programa sugere(em outras rodadas) e já usei outros templates de web app que achei online. Nenhum funcionou. Alguém sabe como resolve esse problema?
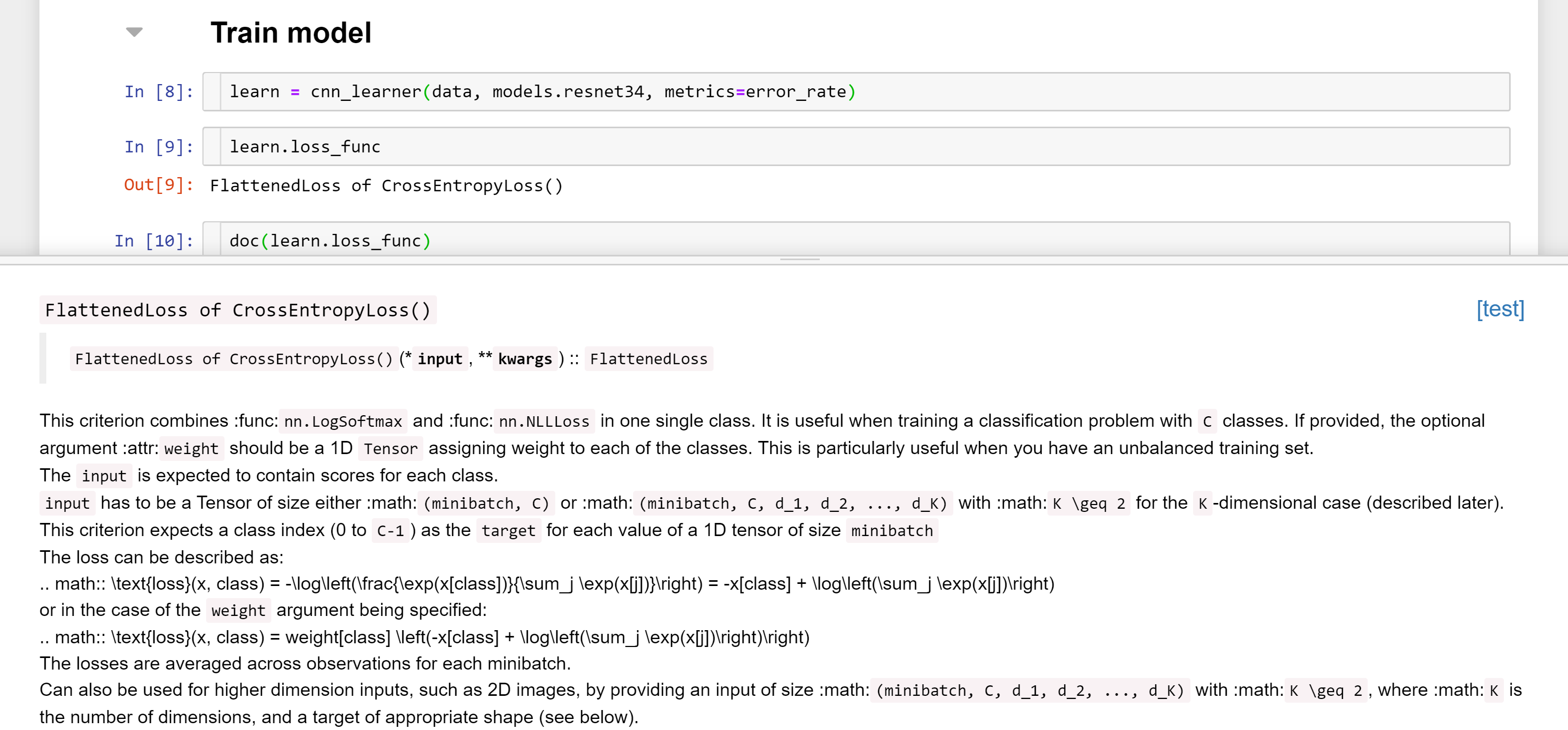
Um objeto learner é criado pela função cnn_learner() que associa uma função de erro predefinida. Pode acessar essa função de erro por seu atributo learn.loss_func (aqui, FlattenedLoss of CrossEntropyLoss()).
Para obter mais informações sobre essa função de erro, roda doc(learn.loss_func) como na imagem seguinte:
Pode definir new_loss_func seja simplesmente como uma função usando tensores (previsões e targets) como argumentos, seja uma instancia de uma classe de função de erro. Em 2 cases, pode usar funções/classes do fastai, do pytorch até pode criá-las.
Com dados despropocionais, pode usar por exemplo F.CrossEntropyLoss(weight=tensor_of_weight_for_each_class))
Bom dia!
Vou colocar essa dúvida em três partes porque só posso fazer upload de uma imagem por post e são muitos prints…
[1/3]
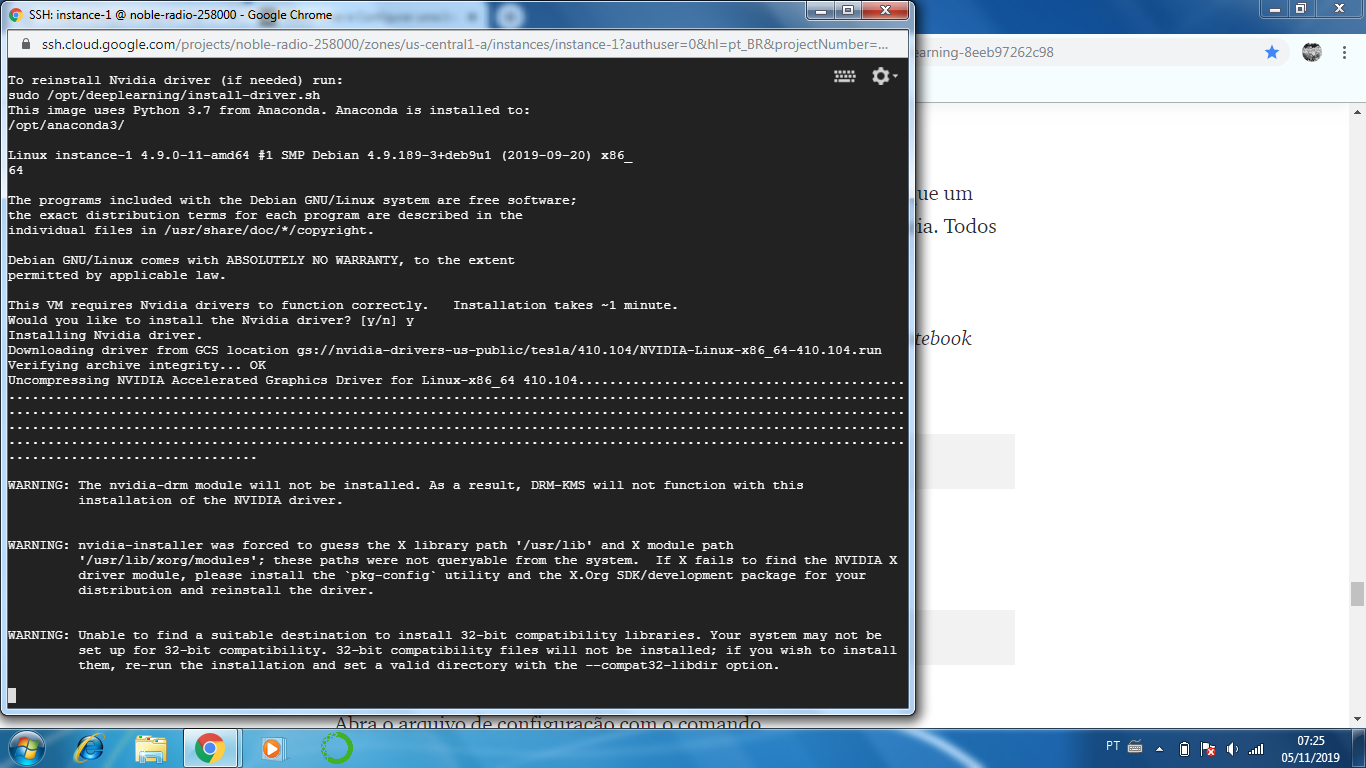
Estou tendo dificuldades para colocar o diretório quando vou configurar o jupyter notebook na minha instância do google cloud. Antes de tudo, aconteceu um erro na instalação do driver da NVIDIA. Tirei um print disso porque não sabia se tinha ou não relação.
Então, tem uma coisa que tem que ficar bem claro: quanto você acessa uma instância do GCP, ela não tem ligação nenhuma com seu computador. Uma instância do GCP é literalmente um outro computador então não faz sentido você colocar um caminho da sua máquina local.
Além disso, a instância vem com um sistema Linux (o debian) instalado, então você tem que especificar os diretórios de Linux dentro da instância.
Você pode fazer uploads e downloads para a sua instância apertando na engrenagem no canto superior direito da tela (lembrando que você não deve fazer upload de arquivos grandes, já que vai demorar muito). Para colocar seu dataset na instância você deve baixá-lo diretamente nela (vou fazer um post no medium explicando como fazê-lo).