Hi, I have made a healthy vs junk food detector app.
https://healthy-or-not.herokuapp.com/
I am able to get between 85-90% accuracy even though the data which I downloaded off google is quite noisy.
One difference between this and other classification tasks, for e.g. different dog breeds, is that even though two categories can look same, the output is singular, i.e. it can be this or that. Never a mix of the two. When it comes to food, that boundary can be blurred as it can be a bit of both.
I started off with ~500 of each category using query like “health food dishes -junk” and “unhealthy food dishes -healthy”. With some little cleanup I got around 90% accuracy. However it had a limited view of food items and mostly consisted of your regular junk food like burgers, fries etc on one hand and salads on the other. So next I consciously picked 4 different cuisines, namely, american, italian, indian and chinese and download healthy and junk food images for each of them. Next up I added some sweets in the junk food category and greens in the healthy category. Even with that I’m able to keep the accuracy between 85-90%, which to me is quite good.
I was worried if the model was too biased with the green color, so I picked out couple of green junk food. First was this avacado burger and to my surprise it classified it correctly. Perhaps it is more biased towards burgers  Next I gave a green cupcake, and it failed to identify it correctly. I noticed that in my training data, I did not have images of cup cakes. So it’s just a matter of adding the right set of data and the model will somehow magically extend.
Next I gave a green cupcake, and it failed to identify it correctly. I noticed that in my training data, I did not have images of cup cakes. So it’s just a matter of adding the right set of data and the model will somehow magically extend.
Here’s the confusion matrix with 3500 odd healthy food images and 2400 junk food images:
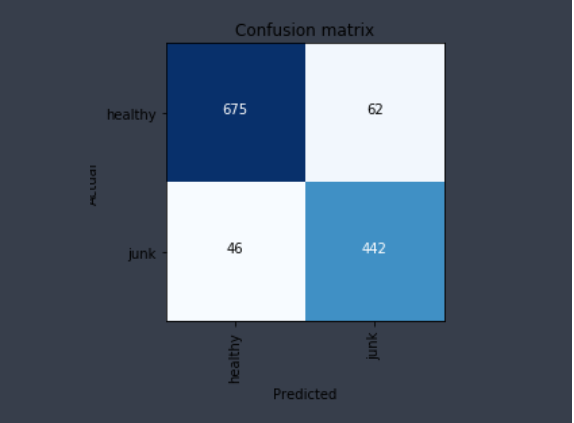
And here are some of the top losses:

While some of them may be unclear even to us whether it is healthy or junk, few others are definitely mis-classified.
For e.g. I have labeled few pop-corn images as healthy and this one I left it as junk since I think it is caramelized.
The 3 in middle column are definitely mis-classified.
I have taken @simonw 's code and enhanced it to deploy on Heroku. Here are a few screenshots:
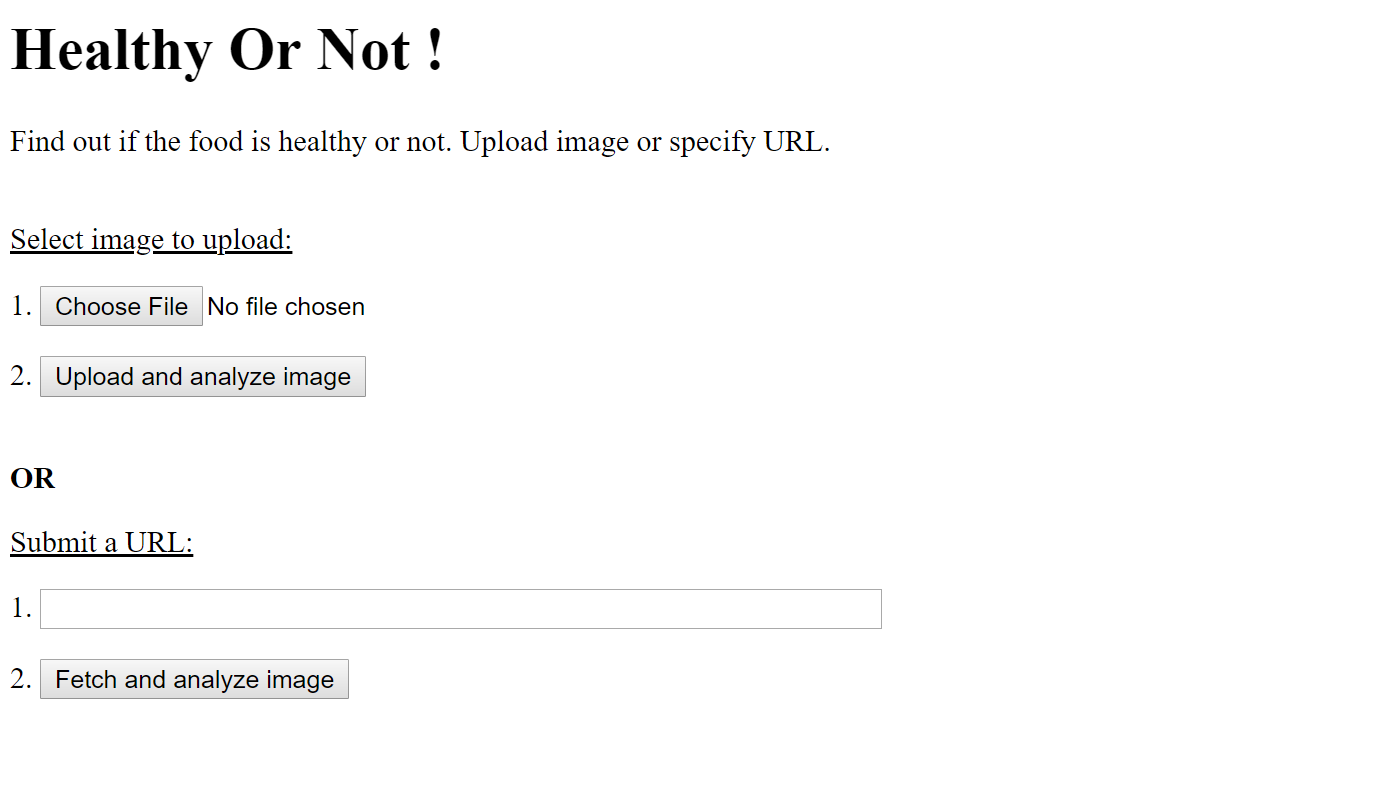


{kind=link}
I have put all the necessary code to deploy it to Heroku in my github repo along with a detailed write-up so I hope it helps some of you to deploy your own app.
Lastly a big thanks to Jeremy & Rachel along with other folks who made this course what it is today. I had done the first few chapters of v2 course and I can say v3 is really awesome and this thread is testimony to that. Cheers.