Show us what you’ve created with what you learned in fast.ai! It could be a blog post, a jupyter notebook, a picture, a github repo, a web app, or anything else.
If you want to have folks on the forum look at a draft and give feedback without sharing it more widely, just mention that in your post
You can also just use a reply to this topic to describe what you did - preferably pasting in a picture or two!
I put together a Kaggle competition starter pack for a competition that is currently under way - Quick, Draw! There are still six more weeks before it finishes so that is plenty of time to play around.
The competition has a lot of good things going for it. First of all, there do not seem to be any issues with the data. It is also one of the unusual competitions where you can let your imagination run wild - many, many different models can be useful here, potentially including RNNs. Given the submission format it should also be really easy to come up with some interesting way to ensemble the data - might be a fun thing to work on in a group.
If you have any starter code or competition related questions - please go to the thread on Kaggle forums and let’s please discuss it there. This way others who might have a similar question could also benefit. Same goes for sharing code - if there is any competition related code you would like to share, please do it in the open - sharing privately is against competition rules.
Enjoy and beware - these competitions can be addictive
PS. I have not made any references to class materials as to not share links before MOOC launch. The training notebook is based line for line on the lesson 1 lecture nb. Hope Jeremy will forgive me for the lack of proper attribution this time around.
Thanks for mentioning that! I think it would be nice to say “this code is based on code from a fast.ai MOOC that will be publicly available in Jan 2019” or something.
While watching lesson 1 of the new course I was wondering where to get a big forest/nature related dataset to build an image classifier on, as this is the domain I am coming from.
I finally found the ImageCLEF Plant Identification Challenge 2013 which provides a already labeld training dataset containing images of 250 plant species on 10485 images (25GB). Most of the images are showing leafs but there also images of flowers, fruit, stem & the entire plant.
For the classifier I used the images with a uniform background (category=SheetAsBAckground) which only contain leaves: 4921 samples and 124 classes.
I started with training a pretrained resnet34 and already got the error rate down to ~3% after 17 epochs. Interestingly fine tuning didn´t help to improve accuracy/loss drastically.
What to do next:
Train network for category=NaturalBackground
Maybe exclude classes with samples < 10?
Below you can find a GIST of the notebook I used. I am looking forward to your feedback on what I can improve or what else could be done with this dataset
Note that Quick Draw competition goes in two versions: (1) simplified and (2) raw. And the later one includes approx. 66GB of data. So in case if you’re downloading the data, you’d better specify which version of the dataset you’re going to use:
I’ve made a notebook to classify food pictures from the food-101 dataset. Here’s the notebook in nbviewer, and here’s the repo if you want to see the other experiments I’ve been running. I built a French language model using v1, and also have another experiment with food-101.
I’ll do a broader write up on my blog as I progress - but my first attempt at differentiating downloaded images from Google (thanks @lindyrock for the tip) of American football, soccer, rugby, Australian rules football, ice hockey, field hockey, lacrosse, baseball, cricket, boxing, wrestling and athletics gave some fun results. A few hundred images of each, ResNet34 and just 4 cycles gave me 20% error rate. Initial observations - my data isn’t that clean - some search results weren’t what I was looking for (soccer/football - ice and field hockey) - so reviewing and cleaning datasets will help. Confusion matrix much as expected -
I wrote a fun little notebook to create an image classifier just with specifying keywords. It’s using the google image search to find images for those keywords and trains a classifier on those images:
 It could be a blog post, a jupyter notebook, a picture, a github repo, a web app, or anything else.
It could be a blog post, a jupyter notebook, a picture, a github repo, a web app, or anything else.

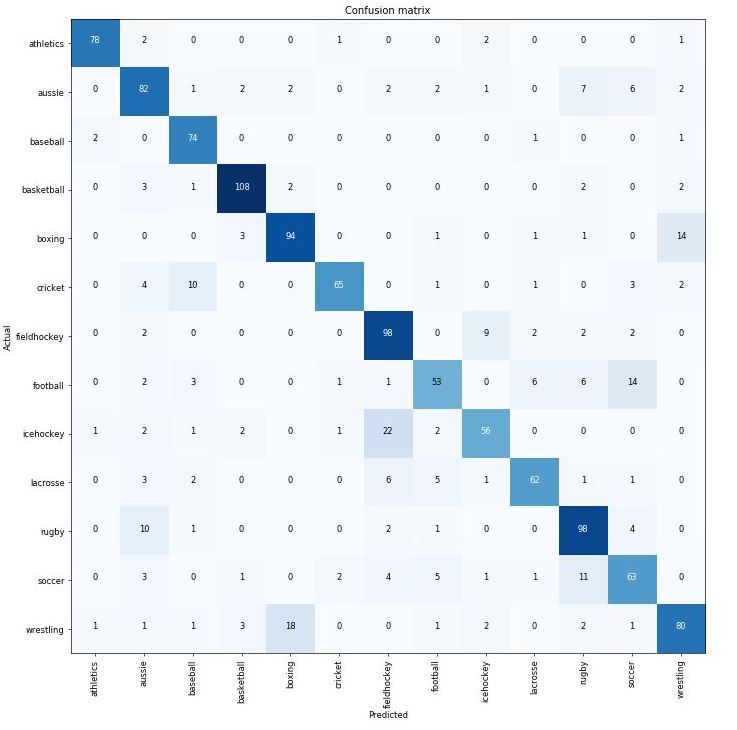

 ). Thanks!
). Thanks!