btw, do you know of any shorter method?
You can certainly make it shorter and nicer in terms of coding, but I think opening it is necessary!
1 Like
Edit : Just realised that this is the ‘Share Your Work’ thread.  Let’s discuss elsewhere :
Let’s discuss elsewhere :
2 Likes
Note that the sample we used in lesson 1 is only "3"s and "7"s.
5 Likes
To get started I’ve created a small dataset with indoor and outdoor images from a dutch real estate website. Only one wrongly image, top-left-corner (interp.plot_top_losses). Can’t wait to learn on what grounds the network makes it’s decisions.
Buiten = outside, binnen = inside

29 Likes
Cool stuff! Coincidentally I have started on the feature interpretation.
By applying PCA to the last layer before the predictions I get some really cool features, I interpreted the top two features as ‘naked/hairy’ and ‘dog/cat’. Now I can find the hairiest dogs, and the most naked cats:


I’ve shared my notebook here (only accessible by url).
Next I’ll train a linear classifier on these features to learn what features matter most for what breed.
Tips on how to improve the code are welcome by the way. Once I have a better grasp on the library I’ll rewrite this into a proper blog post 
68 Likes
Wow, great work! - Maybe you can explain your PCA setup in more detail?
1 Like
Talking about Quick Draw (or any other Kaggle competitions), it could be useful to check kernels:
Usually, you can find various scripts, notebooks, etc.
2 Likes
Great work! I love the results you found!
I think there are a few bits you can refactor, like:
- fastai_v1 has a version of save features, and easier way to add hooks. Check out the hook_output, will give you the output of the layer you pass (you’ll just have to append them together). Once you’ve called the model on your input (see below), you’ll find the features in
hook.stored. - You can just call
Image.predictinstead of copying the code of_predict. It will get the image through the model and call the hooks to give you the activations.
8 Likes
Nice! You can probably just use our existing callback for saving activations - or at least simplify your code using our HooksCallback:
http://docs.fast.ai/callbacks.hooks.html
Untested, but something like:
class StoreHook(HookCallback):
def on_train_begin(self, **kwargs):
super().on_train_begin(**kwargs)
self.acts = []
def hook(self, m, i, o): return o
def on_batch_end(self, train, **kwargs): self.acts.append(self.hooks.stored)
You can pass a list of modules to the ctor to hook whatever layers you like.
18 Likes

With some image curation and resnet50 I’m close to 90% with my sports classifier. Mainly errors are boxing/wrestling - but I do see quite a few asymmetric errors - for example rugby gets recognized as soccer but rarely the other way around. Is this just my due to some very specific patterns defining rugby - and people running around a field is more probably something else? My favourite is the basketball classified as wrestling - a tricky one.

Edited - thanks @Taka - I hadn’t looked close enough! More image curation…
2 Likes
The one to the top right corner though 
Edit : Sadly, the image has now been removed 
1 Like
Removed the offensive image and re-ran my model - sorry @Taka and thanks for picking this up!
1 Like
Wow… didn’t know we can use PCA like this. Very cool way to classify data.
I created a model to classify a dataset of pasta images (± 3500 images of 5 types of pasta) that I downloaded from Google Images using the firefox extension someone else posted on here.
https://nbviewer.jupyter.org/gist/bvandepoel/1f1fe859cb02baf27ef7ba286e222780
It works pretty well, but struggles a bit with spaghetti vs linguine (which makes sense  ) Also, Resnet50 turns out quite a bit better than Resnet34 (13% vs 21% error).
) Also, Resnet50 turns out quite a bit better than Resnet34 (13% vs 21% error).
4 Likes
THNX @radek, looking at your code I’ve figure out how to make TTA predictions with v1 ![]()
preds = learn.TTA(is_test=True)[0]
For an old kaggle competition:
Using almost everywhere only default values from lesson 1 i’ve got very good results on validation set (error_rate=0.030588):
Late submitting my predictions I’ve got a private score of 0.359 about 240/1440.
I’ll cleanup and share my nbk asap!
12 Likes
I thought of trying out something simple, to get used to the new fastai library. So, I built a model on the DHCD dataset (https://archive.ics.uci.edu/ml/datasets/Devanagari+Handwritten+Character+Dataset).
It’s a dataset similar to MNIST, but for Devanagari(देवनागरी) characters instead.
The dataset is not as well known and/or used, so was fun to try it out, and got pretty good results (error rate : 1.49% | accuracy : 98.51%) for less than an hour of tinkering.
Also, these top losses seem legit to me 

29 Likes
Hi All,
I put together a medium blog post, It’s a Draft now, and haven’t publish it, I want to run it through all of you, to know your opinion, feedback, issues with article, issues with accuracy metrics, grammar, typo mistake, anything which comes to your mind.
I am planning to publish this by Saturday Eastern Time US. So any feedback till then is totally appreciated.
Huge Thanks to @jeremy for making this highly valuable education free for everyone, compare to many other institution, I attended in past for ML and DL.
3 Likes
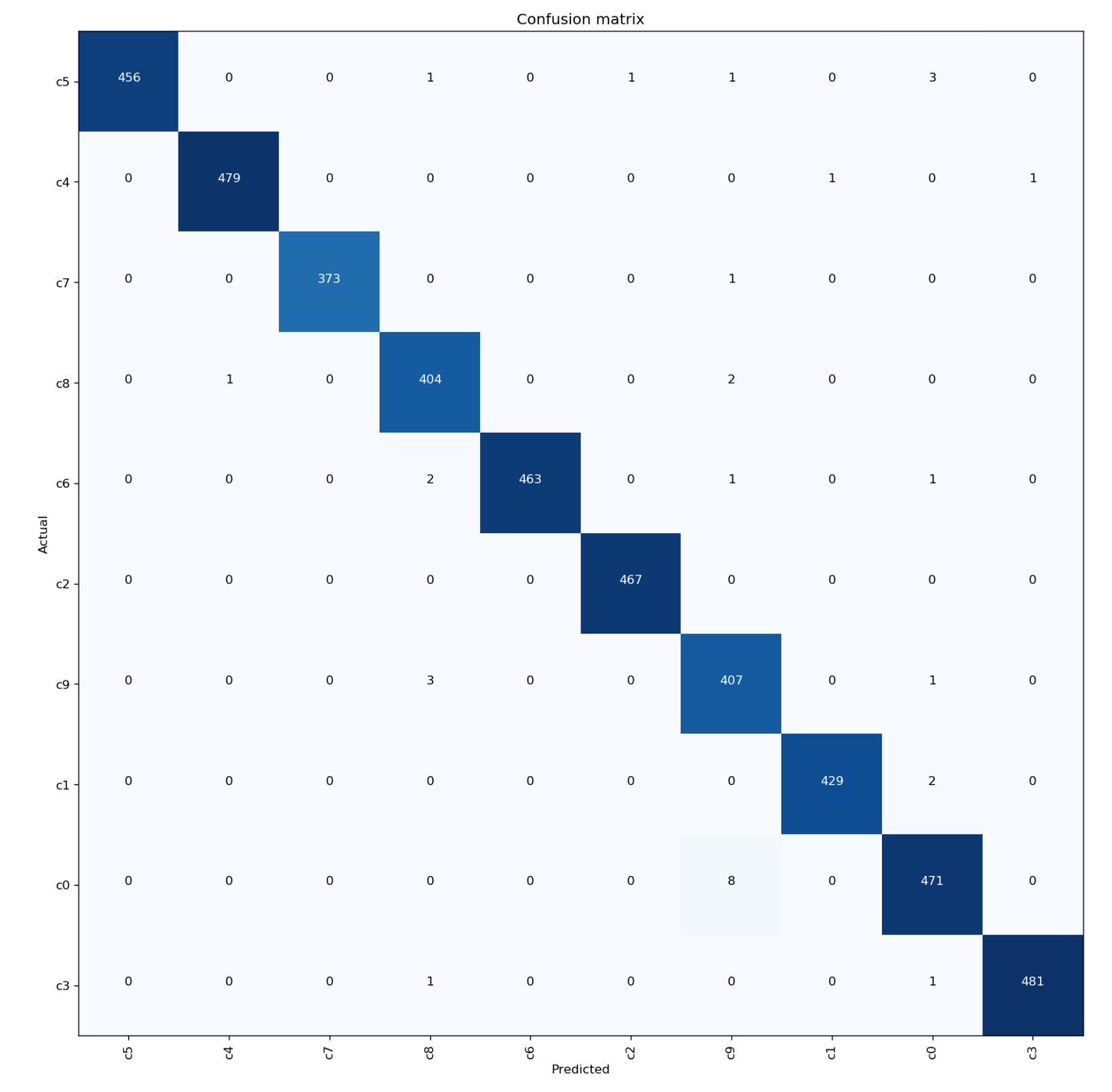
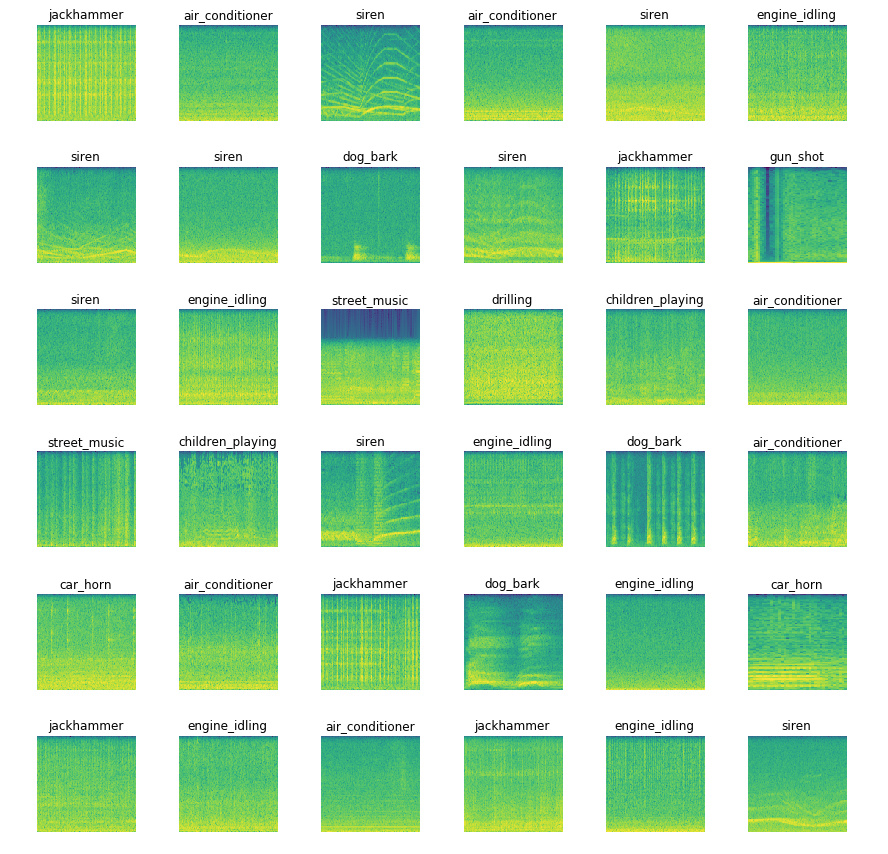
Hi Community!
I’m seeing promising results on a 10 class audio classification task.
I am getting 76.3% accuracy with fastai and basically no effort, so that’s really cool! However, according to the publications listed on the dataset’s website, the top accuracy is 79%.
My goal is to surpass that by next weeks class, so I’m asking you guys for suggestions on what the most fruitful avenue might be:
- tune hyperparameters
- add audio specific data augmentation (obviously the common transformations don’t help with spectrograms)
- create better spectrograms which could be easier to classify
Here is my notebook.
thanks @jeremy for making this course so fun!
67 Likes