Hi all, really excited to see all the cool stuff people have been working on. Thanks again Jeremy, Rachel, and the rest of the community here - I’m looking forward to learning from all of you during this journey
On the heels of week 1’s lesson, I decided to take a stab at my own image classification exploration between 4 different kinds of french fries (waffle, curly, shoestring, and tater tots). I wrote about it in a medium blog post (in addition to a little intro about my general excitement for fast.ai). Feel free to look through it if you’re interested!
I’m not sure it’s not picking up some individual satellite characteristics rather than the urban specifics of each country but I’m curious to investigate this some more over the coming weeks.
Repo is here but the notebook is essentially a copy paste of the lesson’s code. Scraper is in there too (sorry it’s in Go but happy to share the binary)
This is a continuing project that I will be working on, but part one was just an analysis of an American Football college team taking the ball at the 25 yard line or trying to gain more yards. This is something that I wouldn’t have been able to accomplish without the help of fastai. Some of the future work I plan on doing with this data is more deep learning related where as this was more analytical. My next thing I want to do is build a model that predicts the outcome of a play so I think that will be more interesting from a technical perspective but this is my first blog post that I actually published (I’ve had some drafts, but nothing that felt polished enough to publish).
That’s an awesome idea for data collection. That could help get a good data sample together to train on before doing transfer learning onto your real images. I think that would be a useful tool. Maybe it could be a stand alone class though that is used to get a decent number of images and put them into a train/valid folder. You could maybe even have it display the image and let you y/n each image before it gets saved so you don’t get any false positives.
Very interesting. I’d suggest focusing on one fold first, make that as good as you can, then do the full CV at the end.
Because this is so different to imagenet, the pre-unfreezing step doesn’t get you very far. As you see, after just one epoch the accuracy stops improving. Therefore, just do one epoch before unfreezing. Then try lr_finder. Then run as many epochs as you can before error starts getting worse.
Hello everyone, I wanted to know that how resnet34 model would be able to differentiate between a person playing two musical instruments guitar and sitar. Both of these instruments look quite similar so I thought why not to build a model that would classify them.
I used 100 examples for each class i.e. for sitar and guitar.
Using resnet34 model I got an accuracy of 94%. Here are some of my prediction:
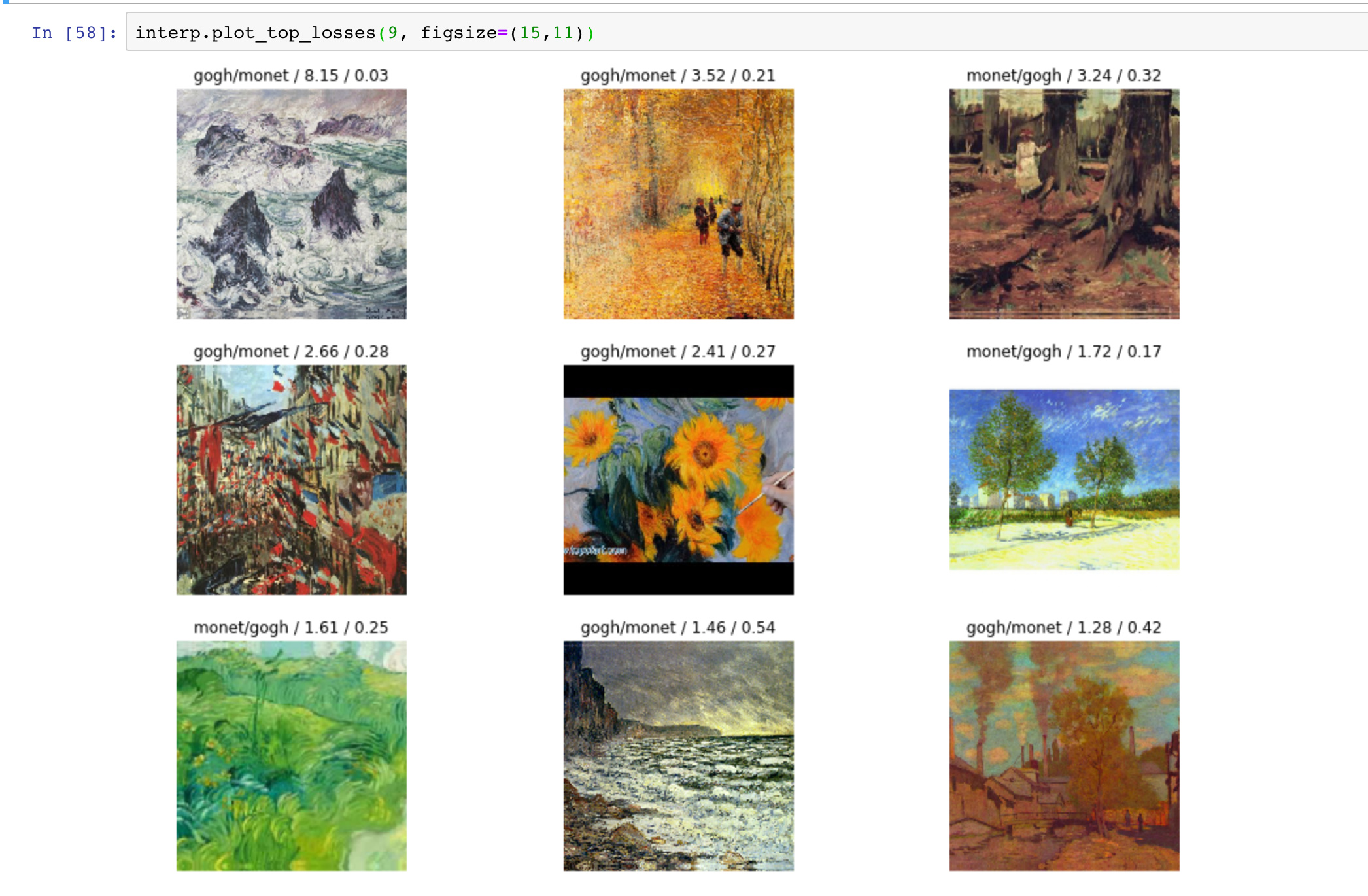
For my project I wanted to check if the resnet model can generalize to the style of an artist. So I downloaded artworks of Van Gogh and Monet and using resnet 50 in under 10 epochs trained it to 94% accuracy.
I thought that because all the images are different, it would be harder for the network to pick the style (i.e. generalize), but it turns out this is not true at all.
Very interesting work!
I have a query, the plots indicate for a particular class (the weights plot of the model)… that’s fine but why are they having lot of common things also in them?
Like few are detecting edges, contours and then the dog as a whole, even the background as if there’s an emboss of dog in the surrounding and few are black or
hard to see what theyare doing actually?(the black ones)
Intriguing ! How about trying normalizing with a subset of your train data than with imagenet stats?
You should also definitely augment.
Let me know if you’ve tried
Also, +1 on fine tuning max 1-fold first.
FYI the link shared:https://.weebly.com/urbansound8k.html is broken
@etown we are working on a similar lines i.e. basically representing audio thru image and doing classification. really good to have someone thinking on similar lines…we are working on data from this kaggle competition. Will share the results shortly. if u have any more learning pls do let us know
Can human recognize all full MNIST data set images or is there some strange numbers? Like why no one have ever got 100% accuracy when our models can predict nearly perfectly something much more complicated.
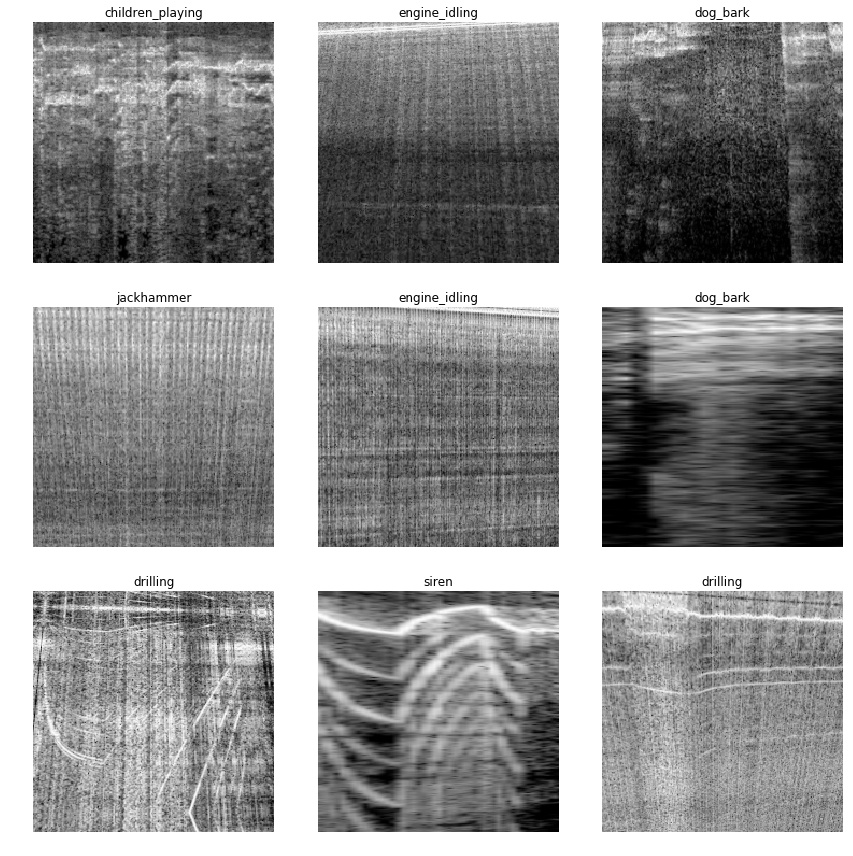
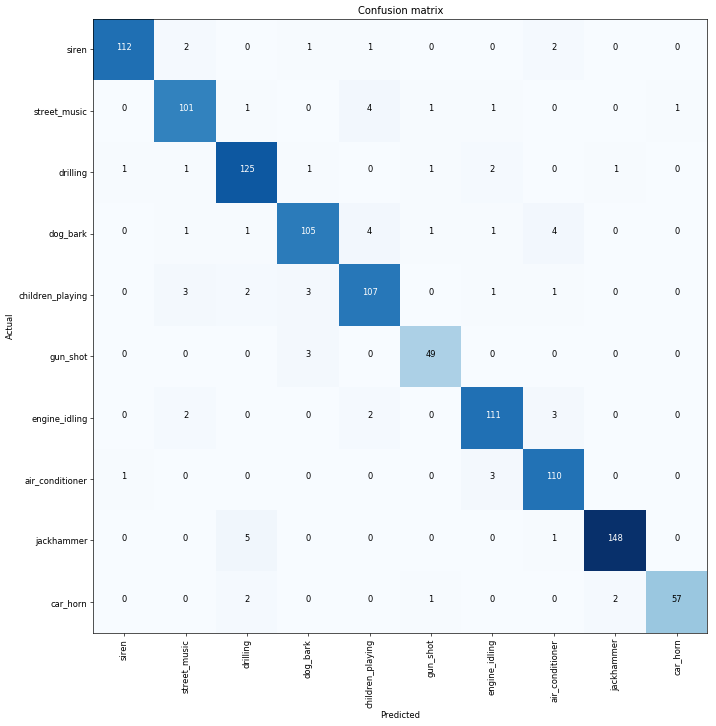
Downloaded the Urban Sounds database a while ago (trainingset with 5425 sounds in 10 classes (drilling, jackhammer, dog barking etc.) Converted de soundfiles (wav) into spectrograms (pictures repsesenting the sound) using the librosa package (Python).