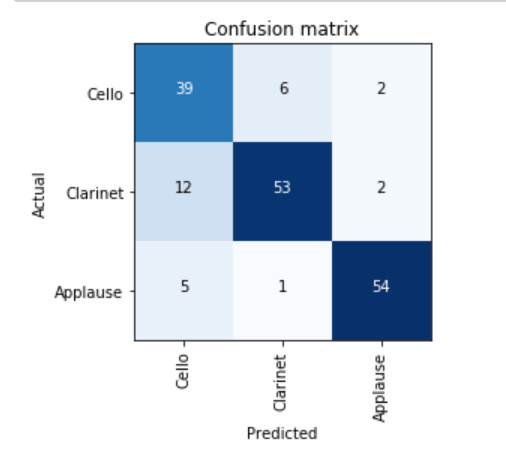
My image dataset now has 9 field sports - and I am into the low 90’s with resnet50 and a little fine tuning (as per lesson 1). The confusions makes sense - not sure why some are pretty symmetric (Aussie rules and rugby) and others not (cricket v baseball). To improve the accuracy I’m thinking more data and some image curation. Any other ideas? Differentiating what people are doing is certainly harder than pure identity.
[(‘cricket’, ‘baseball’, 8),
(‘aussie’, ‘rugby’, 7),
(‘rugby’, ‘aussie’, 5),
(‘rugby’, ‘soccer’, 5),
(‘soccer’, ‘rugby’, 5),
(‘athletics’, ‘fieldhockey’, 4),
(‘aussie’, ‘soccer’, 4),
(‘cricket’, ‘aussie’, 3),
(‘lacrosse’, ‘fieldhockey’, 3),
(‘soccer’, ‘cricket’, 3),
(‘athletics’, ‘aussie’, 2),
(‘aussie’, ‘baseball’, 2),
(‘fieldhockey’, ‘soccer’, 2),
(‘football’, ‘cricket’, 2),
(‘football’, ‘lacrosse’, 2),
(‘football’, ‘rugby’, 2),
(‘football’, ‘soccer’, 2),
(‘lacrosse’, ‘athletics’, 2),
(‘lacrosse’, ‘football’, 2),
(‘rugby’, ‘fieldhockey’, 2)]
Convolutional kernels are good at detecting edges. You can play around with the concept here
http://setosa.io/ev/image-kernels/
The dog images in my post come from activations after a ReLU function defined by x = max(0, x). I imagine the entirely black squares were all negative numbers in the previous layer that got zeroed out by the ReLU.
@MagnIeeT and me are working on the audio dataset from kaggle competition and converted them into images using Fourier transform(FFT).
We performed multiple first cut experiments taking top 3, 7 more frequent classes.
We are getting ~84% accuracy on 3 classes.
Few images of top losses(each graph is FFT of audio clip)
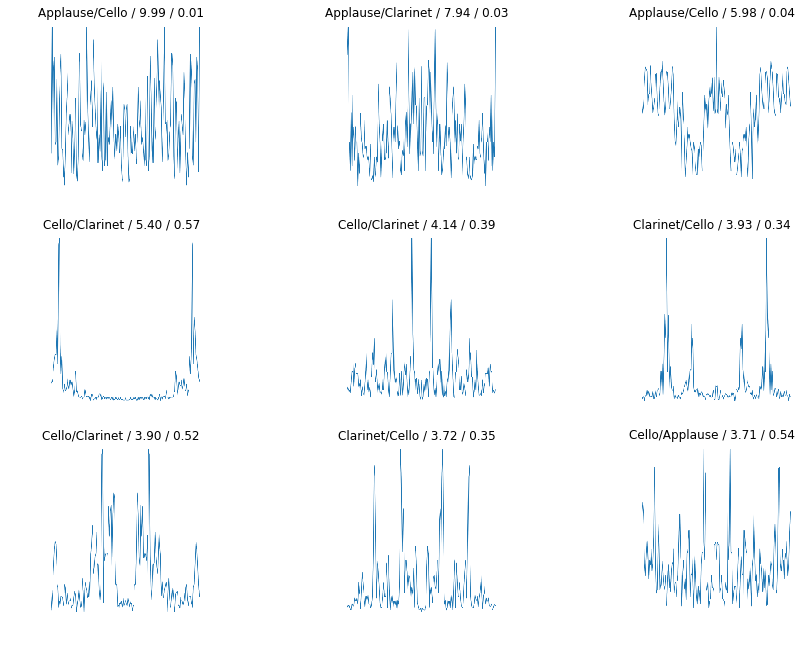
The performance degrades with increasing number of classes
Next steps will be to change how we are doing fourier transform on audio images (the sampling frequency of audio file. Window size we selected was 2 seconds, need to adjust corresponding to notes frequency). Need to test this approach on bigger datasets as our data is currently very small. Also we are planning to use spectrogram as tried by other users.
Google audio dataset is another good source providing 10 sec audio snippets. We initially planned to use but parked it for later as it is more suitable multi label classification
neat. would love to be able to go through the notebook.
@raghavab1992 It’s really interesting work you are doing. Could you please write a blog post about it and I guess if we get to see the notebook it will be really great resource to learn from.
Cool!
Did you use the 10 fold CV As described in the dataset notes? If not, your accuracy is misleading. Take a look at the dataset website. I had similar results, but it’s much more difficult doing the CV and if you don’t you can’t compare it to accuracy in the literature.
Would love to see your nb 
@rameshsingh thanks  would summarize learnings from different experiments we are doing once completed thru a blog. Will share the notebook post some clean up as it is too dirty now for sharing in the forum
would summarize learnings from different experiments we are doing once completed thru a blog. Will share the notebook post some clean up as it is too dirty now for sharing in the forum
With 39 zucchinis and 47 cucumbers …
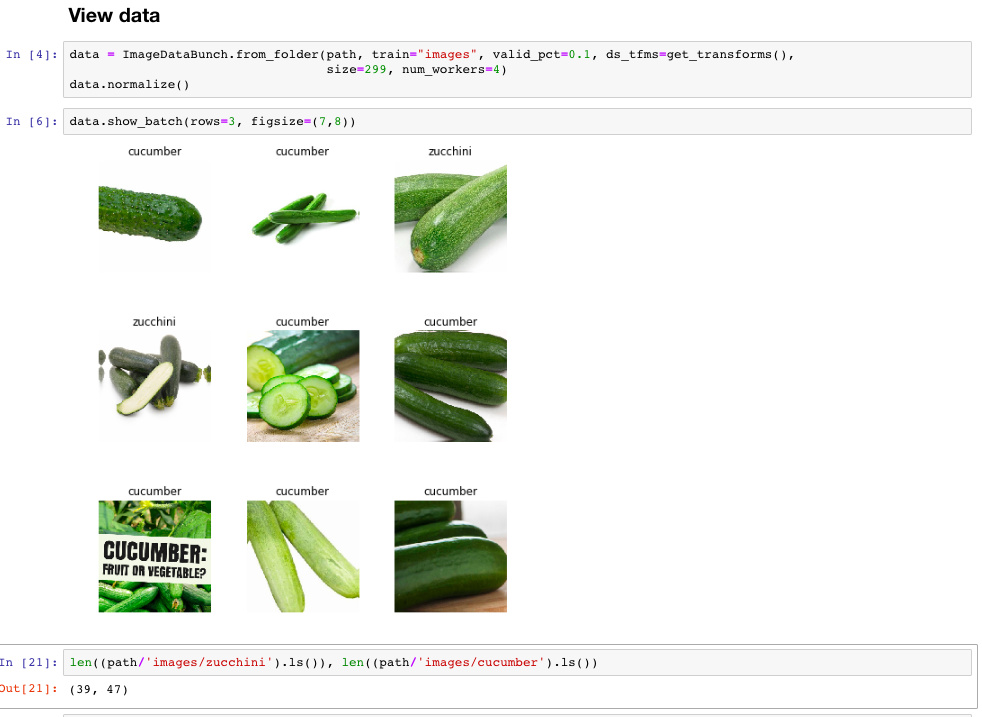
a ResNet50 with input size 299 managed to perfectly distinguish between the two on the validation set (10% of the above numbers) after 2 epochs:
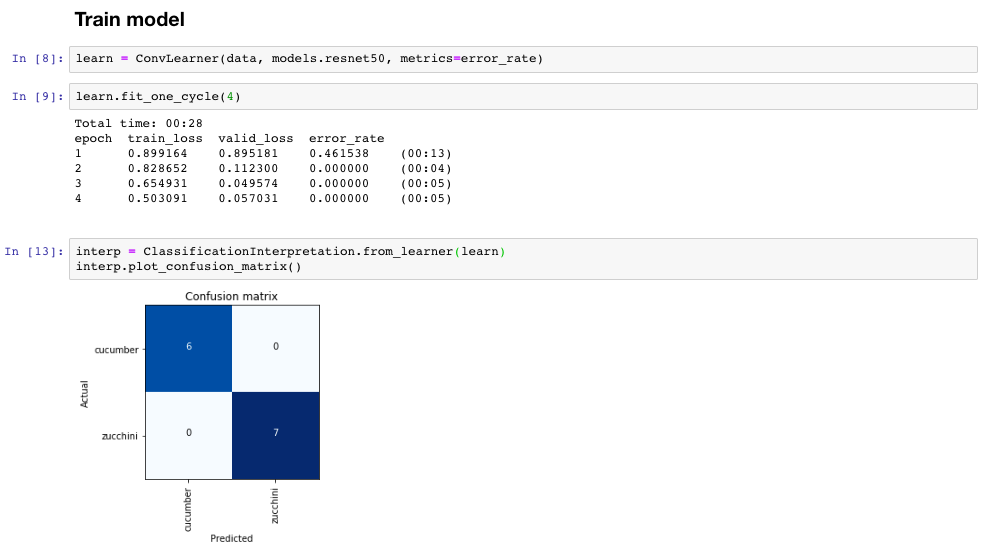
I know we must be careful when interpreting results on a validation set with 13 samples but I had a limited number images and wanted to share the results in any case. The fact that training loss >> validation loss is probably an indication that my validation set is not difficult enough.
I pulled data from Kaggle - https://www.kaggle.com/slothkong/10-monkey-species
10 species of monkeys with about 100 training images for each. I didn’t see any need to do the fine tuning section with this data because how do you get better than pretty much perfect right from the start? Amazing. Gonna find some other data and go again.
Thanks for your reply Ethan. I will look into that.
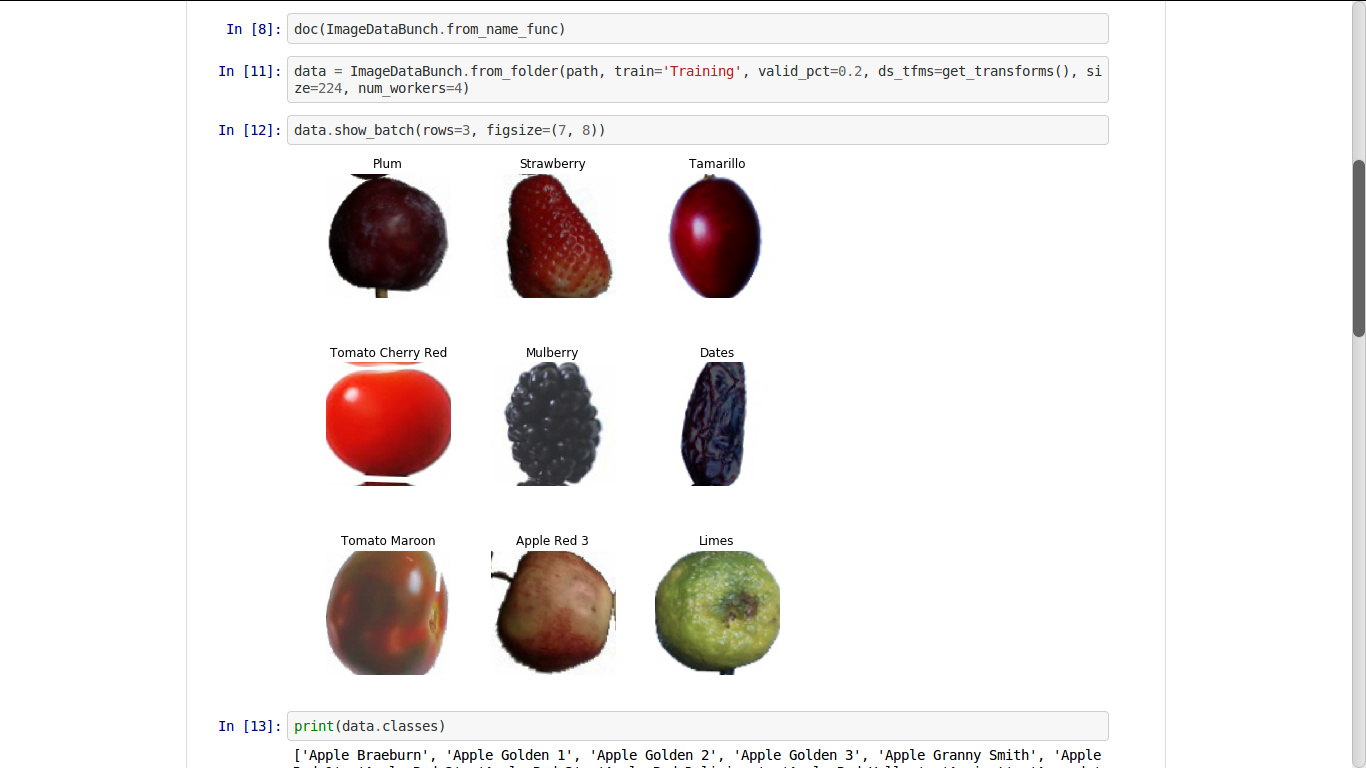
Hello everyone, I found this dataset on kaggle using the google dataset search which is for classifying fruit photos. So I tried my hands and got to 0.5% error rate within 4 epochs. I used resnet34 as the architecture.
Here are the images
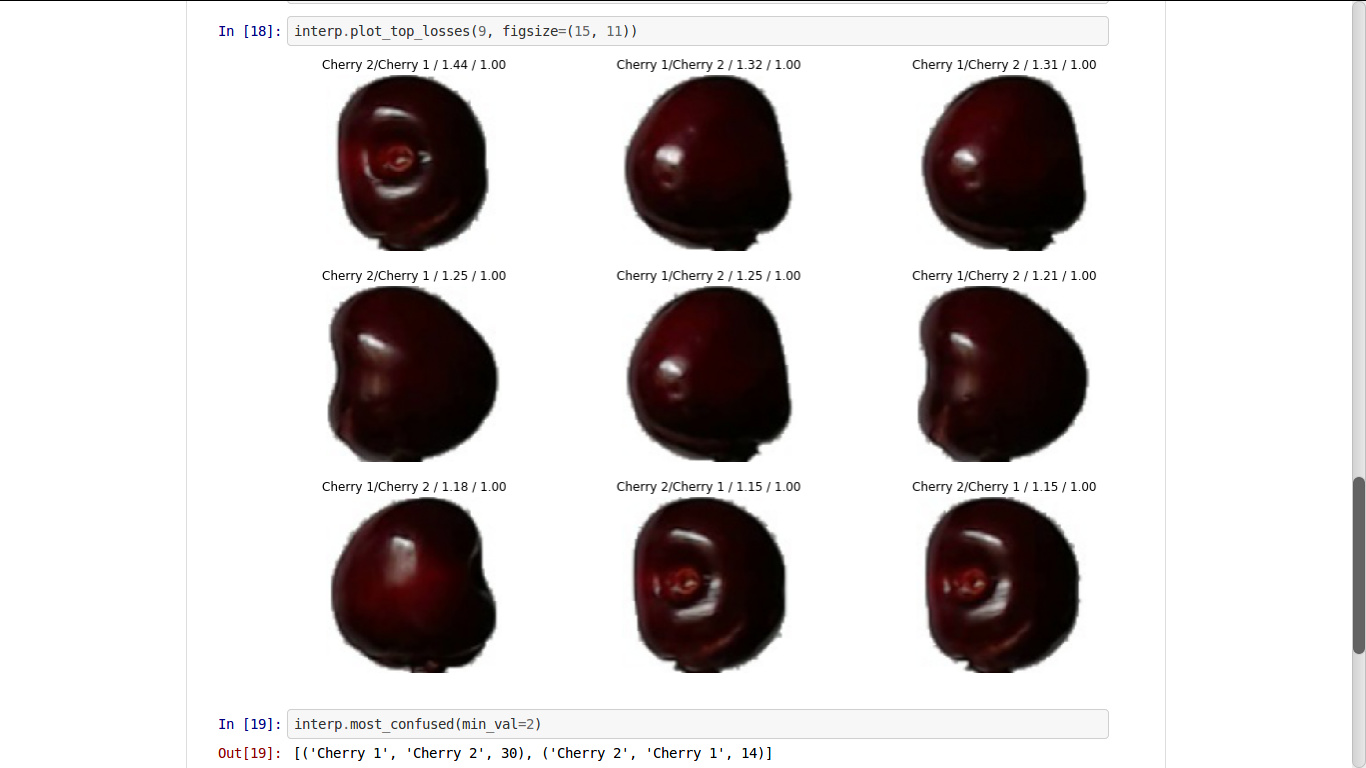
The only things my model is classifying wrong are same things with different labels. 
Hi Radek, how do you approach memory problem with fastai for this competition? fastai learner loads all dataset into memory arrays, and this dataset is too huge to do it.
these are some experiments I did for previous fastai version: Experiments on using Redis as DataSet for fast.ai for huge datasets
Hi Vitaliy - for this competition I load the data directly from HDD.
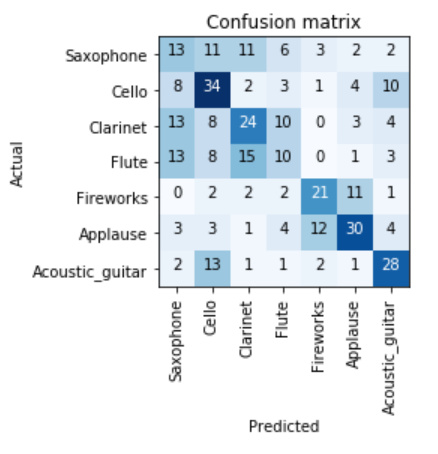
I wanted to represent for the Caribbean programmers. So I built a classifier to classify Trinidad & Tobago Masqueraders versus regular islanders.
Here is a sample of my dataset

Here is a sample of my predictions
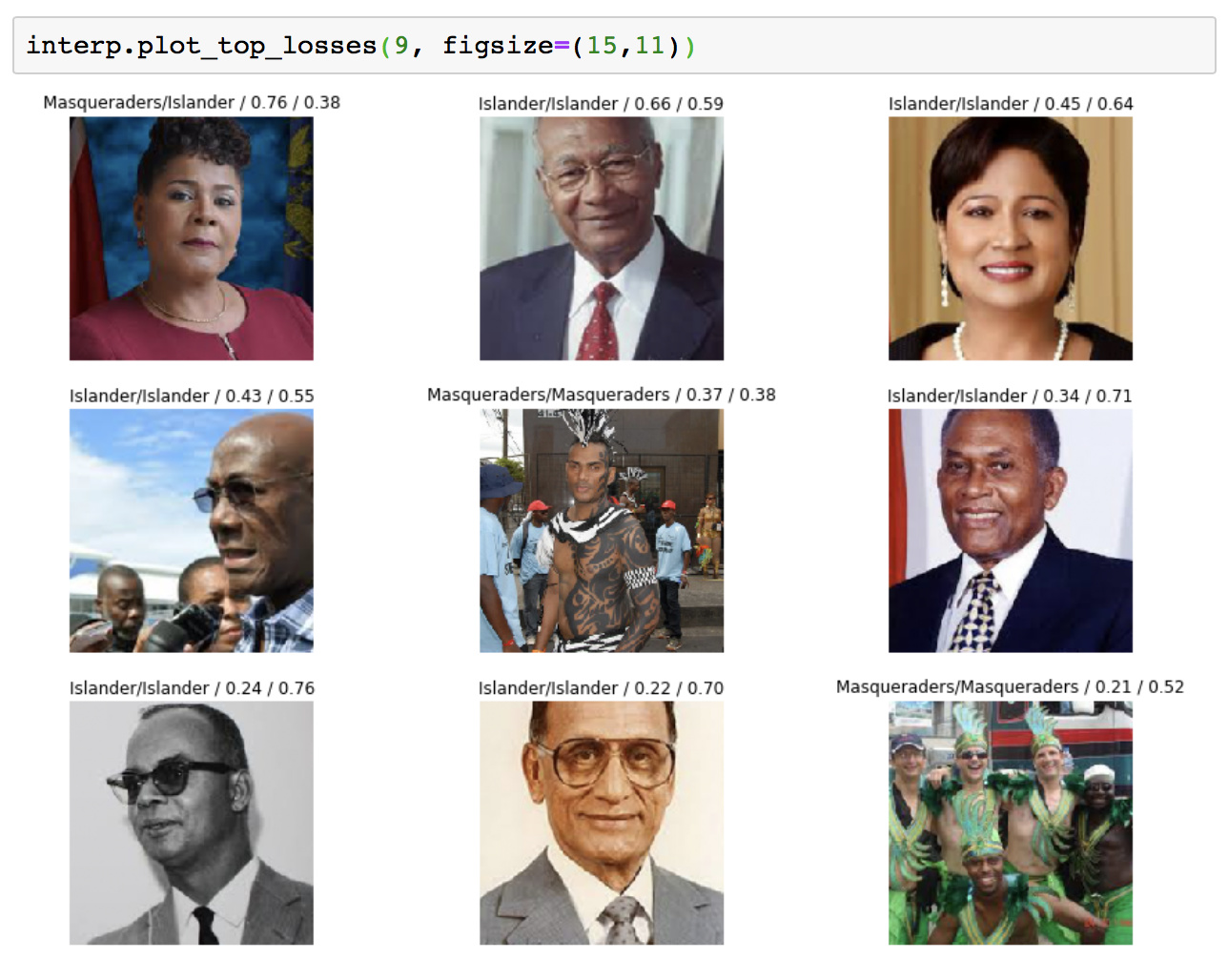
Here is my confusion matrix

Pretty decent results for a very small dataset. Notebook will be forthcoming.
I was thinking that data loader accepts paths and loads tensors on demand, no? Otherwise, it would be impossible to deal with any, even relatively small modern dataset. I remember that I had out-of-memory errors even when trained a dogs breeds classifier.
As I know, PyTorch datasets API doesn’t force you to load everything into memory at once. You only need to define how to retrieve a single instance based on its index.
How? if you take all 50M images you will likely be out of memory on p2/p3.xlarge instance.
I didn’t look into latest fastai, but the fastai from last year loaded all data into ArraysDataset in memory in learner.precomputed call.
I’m not sure where, maybe it was with precompute=True, but in vision, fastai only loads the images a batch at a time when needed for training/validation.
I think in this version of fastai, pre-compute option is removed.
You can also use an s3 bucket to store the data on aws and use a library like boto3 to access the data from the bucket