Small and simple spin off from lesson1
It was one of my last hackhathone task
to do recognition of road signs.
As we can see without big hassle I achieved 98% on very unique data set black and white data three classes
AR-arrow
LD - left diagonal
RD - right diagonal
I loaded data from CSV
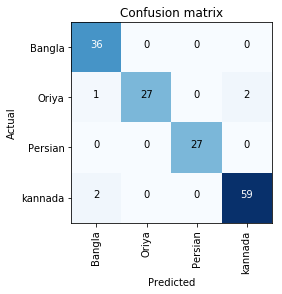
I created a text classifier, which is able to detect language of handwritten document based on images. Dataset contains handwritten text in four languages: Bangla , Kannada, Oriya, Persian.
Here is sample dataset:
I used the lesson 1 notebook. With resnet50, accuracy of classification is ~97%.
I also did a bit of PCA and applied some clustering models on the raw predictions (final output) of the model but not sure how to get the output from other layers. I didn’t know how to use the hook function in fastai neither then I came across your post. Thanks for sharing!
By memory do you mean RAM or the disk? In the code I shared we only use ~1% of the 50 million examples available, I don’t recall now but at resolution 128x128 that is only a couple of GB.
All these files never get loaded into RAM. They are written one by one to disk. And during training they are loaded and transformed on a per batch basis.
v1 exposes many nice ways to work with image files on disk - those are the class methods of ImageDataBunch in vision/data.py starting around line 271.
In v2 of the course I remember Jeremy saying: ‘if you have an option to change the data into a format supported by the tool of your choice, go ahead and do it, it will save you a lot of hassle vs writing your own way of interfacing with the data directly’. There is a way to use all 50 million examples by generating them on the fly without storing anything to disk, but I heeded Jeremy’s advice and took the easy way out
As a side note, I do wonder if even with a big, well tuned model it makes a difference if you train on 50 million examples vs say 2 million with data augmentation Realistically, there must be a lot of redundancy in 50_000_000 / 340 drawings of snowman!
I was able to get the accuracy up to 0.99+ and the single misclassified image is one where the insect is only shown incompletely:
ResNet34: 0.995037
ResNet50: 0.998677
These results also beat the older papers as far as I have found comparable values.
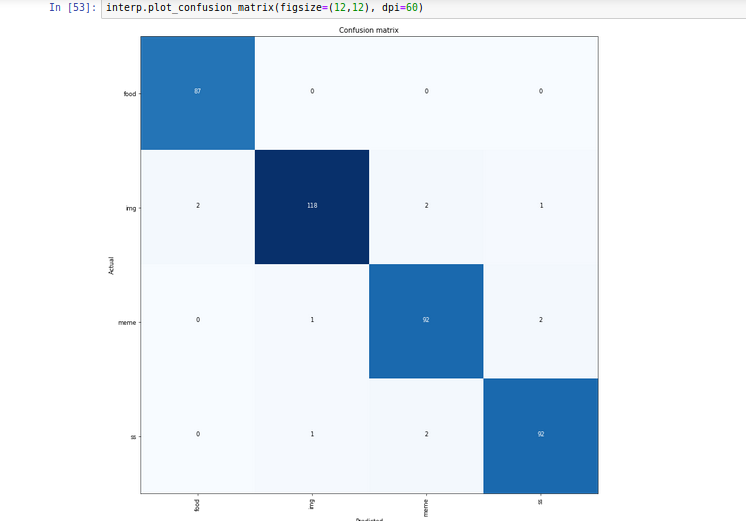
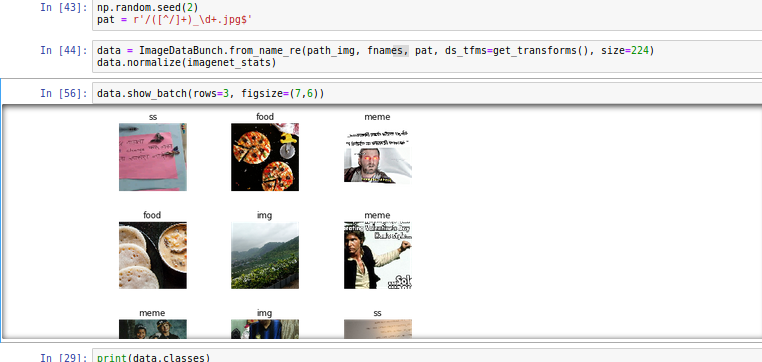
I always have to manually clean up my Whatsapp downloaded images folder because Memes and other images sit in same folder along with camera pics shared by my contatcs.
Hence i trained 34 model with 2000 images without unfreezing, 1000 manually classified images from my own Whatsapp and another 1000 sourced from google search.
I think google photos have similar model built in to remove clutter but it does not detect memes.
I am planning to have bigger dataset and testing set and see how it goes.
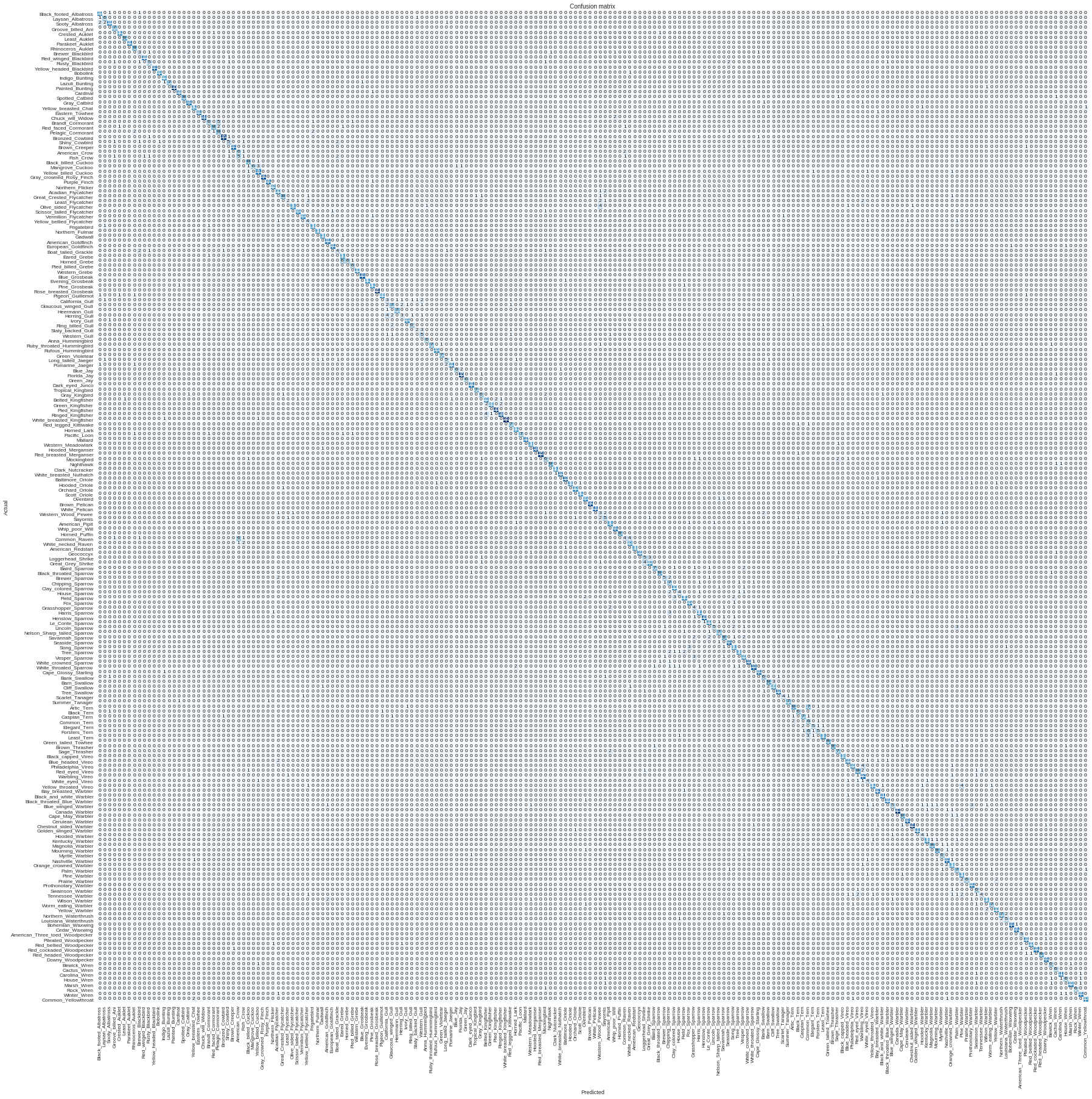
Playing with the Birds dataset from Caltech. It seems going to be challenging, there is 200 bird classes each a dozen pictures. With the simple 4 cycles training of ResNet-34, I got very bad results:
be careful with the CUB dataset, as it says on their website: Warning: Images in this dataset overlap with images in ImageNet. Exercise caution when using networks pretrained with ImageNet (or any network pretrained with images from Flickr) as the test set of CUB may overlap with the training set of the original network.
Potentially you are using images for your valid/test set which were previously in the ImageNet train dataset used for training the weights of the pretrained ResNet.
Nevertheless, I was also playing around with this dataset before and got similar results to the one posted by you.
I guess in this case it would be best(practice) to remove the ImageNet images from the birds dataset or pretrain with other images (and not ImageNet)?
@MicPie I didn’t fully understand the warning when looking at the training cycles results I see big losses. Isn’t this strange? should be almost perfect results if the same pictures were used to train the model.
The thing if we train without ImageNet pretrained NN it will take a long time, but will give it a try.



 Realistically, there must be a lot of redundancy in 50_000_000 / 340 drawings of snowman!
Realistically, there must be a lot of redundancy in 50_000_000 / 340 drawings of snowman!