Edit: See new post below for a working the single image prediction notebook.
After a coding session with @ramon about getting the activations with hooks I hacked together a small notebook (L1-stonefly_activations.ipynb) to visualize the different network layer activations:
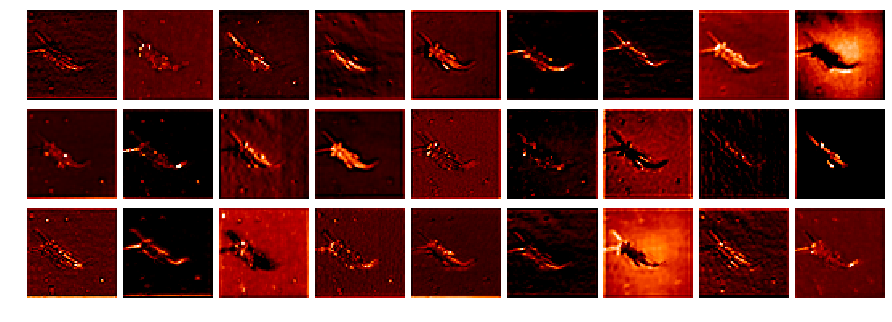
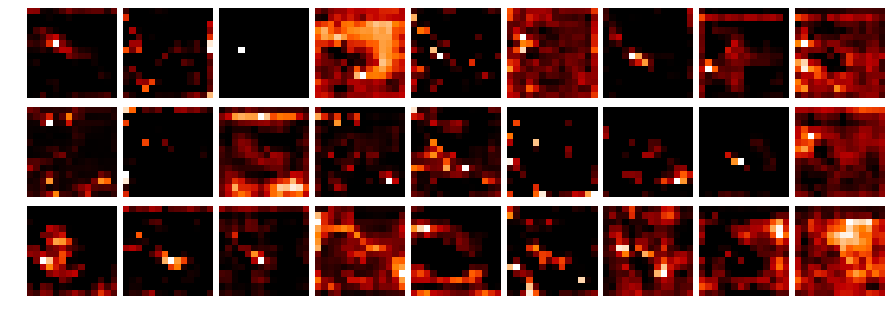
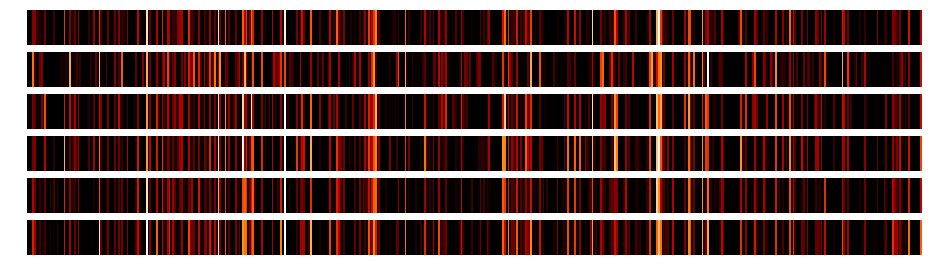
To get the activations I used the following hook function (adapted from Jeremy):
class StoreHook(HookCallback):
def on_train_begin(self, **kwargs):
super().on_train_begin(**kwargs)
self.acts = []
def hook(self, m, i, o): return o
def on_train_end(self, train, **kwargs): self.acts = self.hooks.stored
I am not sure if I used the hook correctly?
The image dimension in the results is strange, as I only have 34 images (the dataset has 3000+)?
I also could not figure out how to get the original image from the data loader to compare them to the activations.
Maybe there is a much easier way to get the activations?
The notebook above is based on my previous post and was inspired by the notebook from @KarlH (thank you, learned a lot!).
Kind regards
Michael