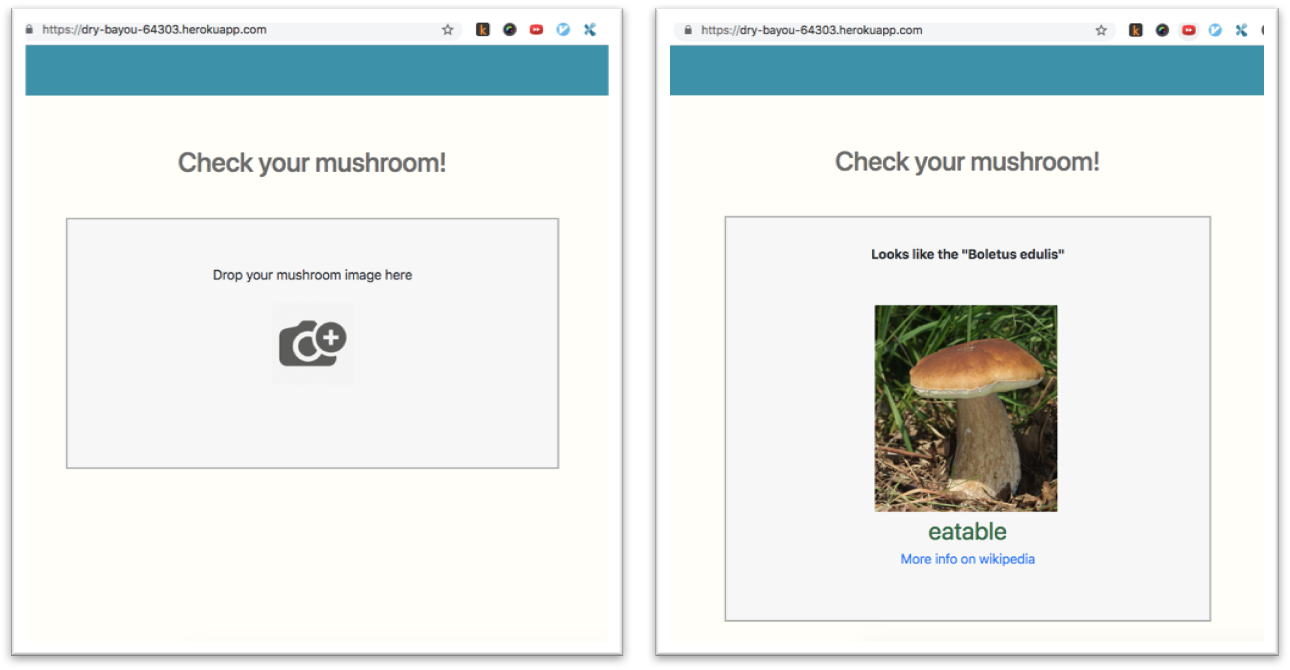
(Still working on improving accuracy and sharing this later on)
Made a mushroom classifier (including +/- 100 type) so you can pick some (eatable) mushrooms in the forest 
I created the web app in Flask and deployed on Heroku - https://dry-bayou-64303.herokuapp.com/