Finally have my deployment up and running…
You can now classify your guitar model online. Well, if it’s a Gibson or Fender, others are coming up…
It’s based on ResNet-50 and achieves an accuracy of ~ 97.1% for the 11 guitar classes I provided.
I’m currently writing up a blog post and will add the link here.
Tools:
Server: Hetzner VPC instance (1 vCPU, 2GB Ram, 20GB SSD)
Deployment: Dokku
App: Flask, Plot.ly, Bulma.io
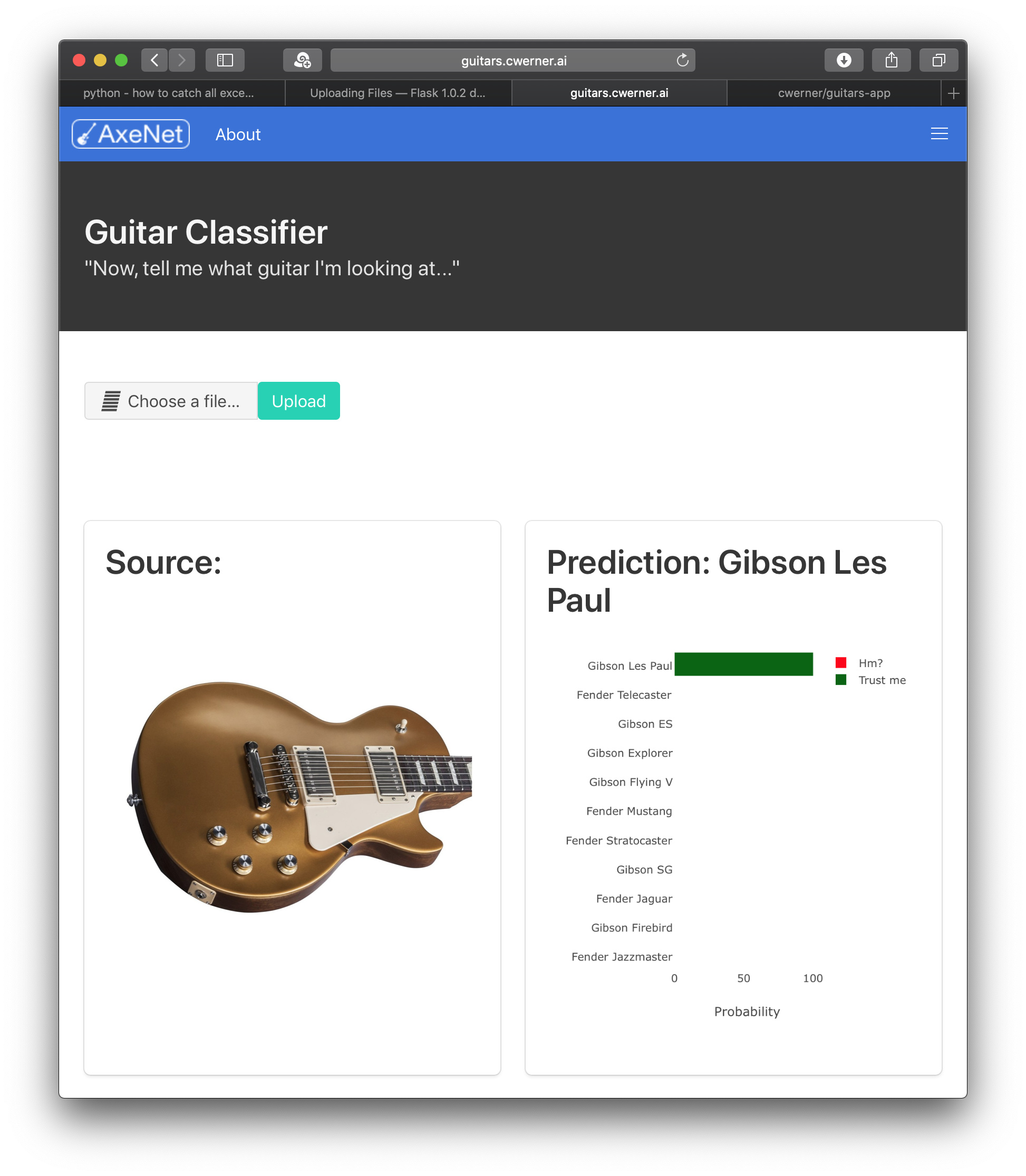
The site lives at: http://guitars.cwerner.ai
The GitHub repo for it is:
NOTE: If you downloaded the code before 2018-11-08: there was a nasty bug in my predict function that is now fixed.