Last few days, I have been working to replicate implementation of winner's solution of taxi trajectory competition using pytorch and fastai (and using their paper, github repo and last year’s fastai course).
Below is the link. (please scroll to the end - ln-72 for discussion issue)
But for that I need to make a custom loss function. Just making a normal function and calling it in fit doesn’t work and throws TypeError: zip argument #71 must support iteration. Then how should I do it?
Although we customized a lot of stuff in ML, course we still used nn.NLLLoss() as loss function and I couldn’t find how to do it in fastai. (sorry if it’s there somewhere and I missed/ forgot it)
Thanks for responding @tensoralex Actually, I was using similar function from rossman nb as reference when it threw the mentioned error.
So, I think this is just the accuracy metric for printing and loss function is defined in StructuredLearner which is called when we use get_learner in rossman nb.
As we see here, it is using F.mse_loss which is inbuilt functional form for mse. I couldn’t find F.myloss() for equirectangular distance (loss I need to use). So, I guess loss function should have forward and backward capability as in F.loss() and we might have to build a class for it. But I found pytorch forums confusing
Now that we have our model all in place we can load anything and create any architecture we want. That leaves us with 2 important components in any pipeline - Loading the data, and the training part. Let’s take a look at the training part. The two most important components of this step are the optimizer and the loss function. The loss function quantifies how far our existing model is from where we want to be, and the optimizer decides how to update parameters such that we can minimize the loss.
Sometimes, we need to define our own loss functions. And here are a few things to know about this -
custom Loss functions are defined using a custom class too. They inherit from torch.nn.Module just like the custom model.
Often, we need to change the dimenions of one of our inputs. This can be done using view() function.
If we want to add a dimension to a tensor, use the unsqueeze() function.
The value finally being returned by a loss function MUST BE a scalar value. Not a vector/tensor.
The value being returned must be a Variable. This is so that it can be used to update the parameters. The best way to do so is to just make sure that both x and y being passed in are Variables. That way any function of the two will also be a Variable.
A Pytorch Variable is just a Pytorch Tensor, but Pytorch is tracking the operations being done on it so that it can backpropagate to get the gradient.
Here I show a custom loss called Regress_Loss which takes as input 2 kinds of input x and y. Then it reshapes x to be similar to y and finally returns the loss by calculating L2 difference between reshaped x and y. This is a standard thing you’ll run across very often in training networks.
Consider x to be shape (5,10) and y to be shape (5,5,10). So, we need to add a dimension to x, then repeat it along the added dimension to match the dimension of y. Then, (x-y) will be the shape (5,5,10). We will have to add over all three dimensions i.e. three torch.sum() to get a scalar.
One question related to this line. My last operation is after softmax layer which multiplies constant vector cluster_lats and cluster_longs (3422x1) to softmax results. So technically it is not having any weights to train. It should be fine, right??
The key thing to remember is that your loss function will receive torch variables as its parameters. So you should be sure to use only operations that are supported on torch variables. You can test it by creating variables yourself and checking it works OK.
Having said that, you should probably try to replicate the winner’s approach with a basic euclidian distance (i.e. rmse) first since it’s nearly identical, and it’s easiest to start simple and gradually make more complex. (I had a chat with @kcturgutlu about processes for replicating winning solutions - so be sure to pick his brain!)
For myloss() to do operations supporting torch variables, I am using nn.Module() class. It should work, right?
`class equiRectLoss(nn.Module):
def __init__(self):
super(equiRectLoss, self).__init__()
def forward(self, a,b):
lat1 = a.fillna(0).apply(lambda x: 0 if type(x) == int else x[1]) * deg2rad
lon1 = a.fillna(0).apply(lambda x: 0 if type(x) == int else x[0]) * deg2rad
lat2 = b.fillna(0).apply(lambda x: 0 if type(x) == int else x[1]) * deg2rad
lon2 = a.fillna(0).apply(lambda x: 0 if type(x) == int else x[0]) * deg2rad
x = (lon2-lon1) * torch.cos((lat1+lat2)/2)
y = (lat2-lat1)
loss = torch.mean((torch.sqrt(x**2 + y**2) * rearth),dim=0)
return loss`
I was reading their paper and they had used equirectangular distance for loss function and kaggle evaluation is also based on the same. That’s why I was trying to make custom loss function. In this particular problem, we have coordinates (latitude and latitude) as output. If we were to use basic Euclidian distance, we would have to customize it so that it calculates distance based on latitude and longitude.
Is there a default function for this that I might not know? Sorry, if it is something obvious and I don’t know about it.
There shouldn’t be a need to do an nn.Module() - just a regular function should be fine. However you seem to be using pandas functions (fillna and apply) in your loss function above - these aren’t for torch variables.
In a small-ish region not too close to the poles, I would expect euclidian distance and equirectangular distance to be nearly the same. So I’d suggest starting with the simpler approach first and make sure that works well, before adding the complexity of a custom loss.
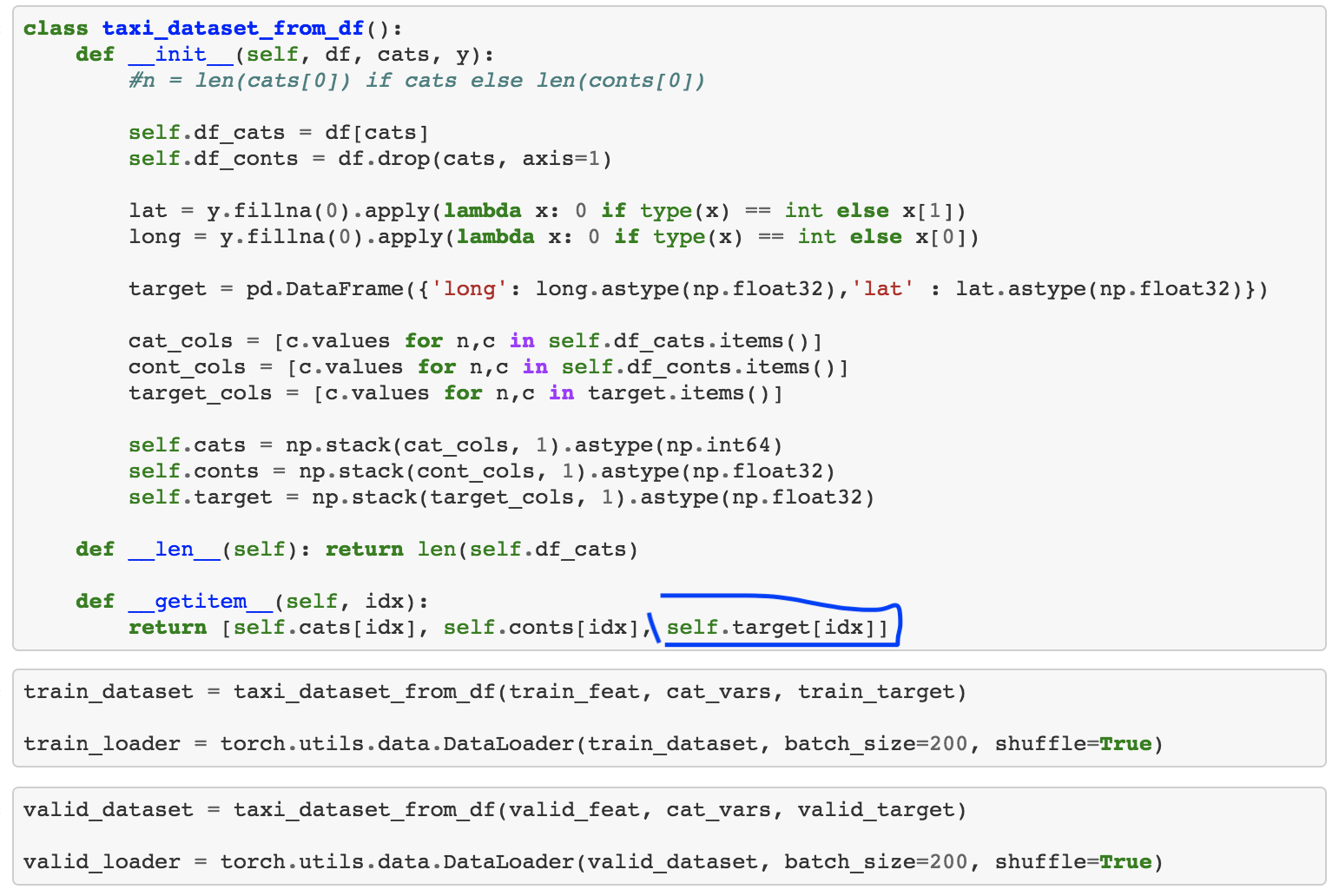
Thanks Jeremy. After banging my head for a few hours, I figured out that the error I faced was due to dataset class. It turned out that I was returning object dtype as output of dataset class, which is not allowed. (floats or ints are allowed)
It threw TypeError: zip argument #58 must support iteration error.
So I updated my code to return 2 stacked columns (not 1 column with list as each element)
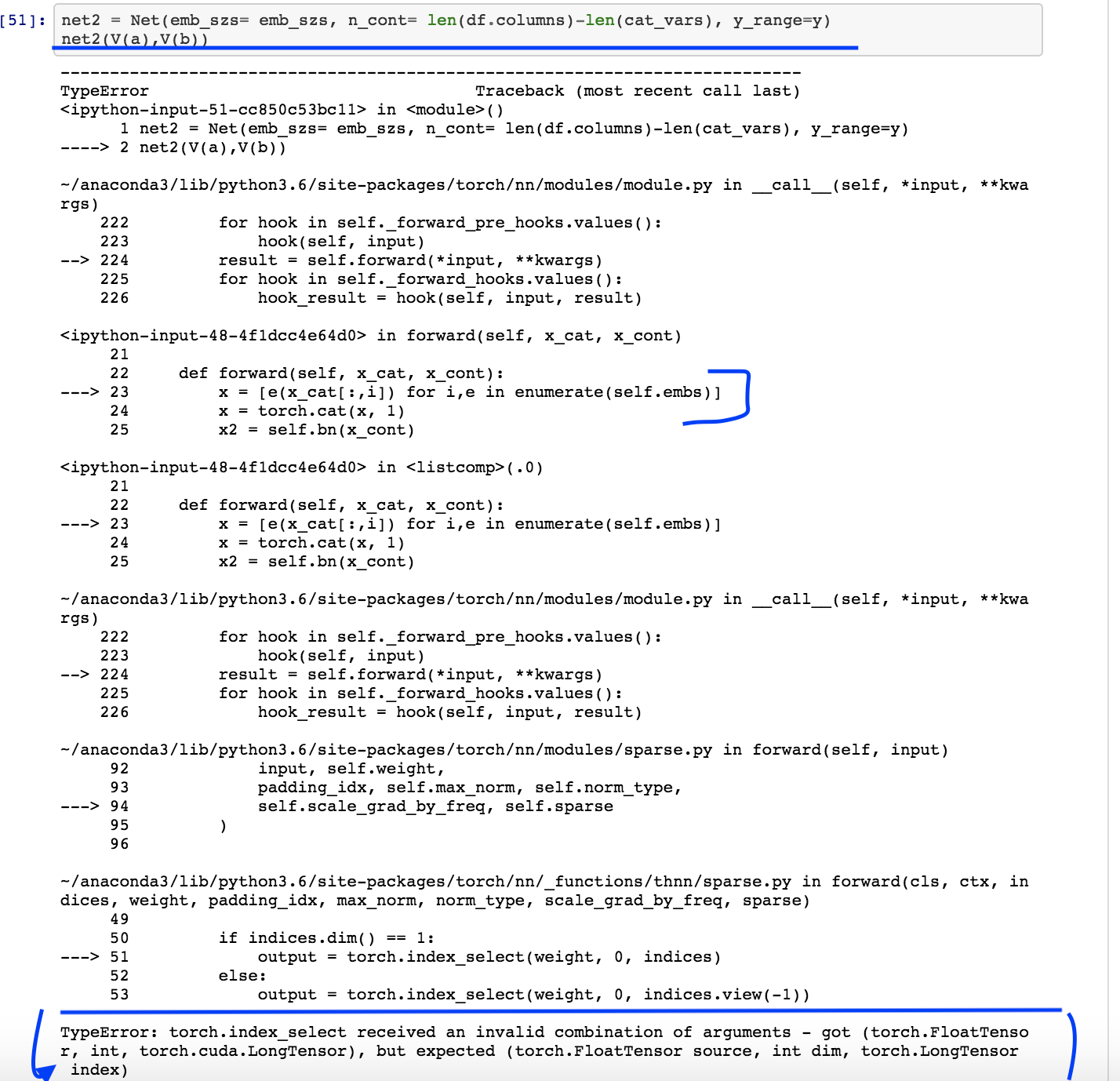
But now I am facing another error which I am trying to resolve (by reading pytorch forums). It seems like it is related to embedding layer but not sure what should I change in code.
We’ve all done it. The trick is to carefully look at the ‘got’ vs ‘expected’ bits of the exception, and note that one type has ‘cuda’ and the other doesn’t.
Since in the notebook we don’t override learner “crit” attribute, so my understanding we are using two loss functions F.mse_loss for training and custom exp_rmspe for accuracy metric and printing outputs.
Is that because exp_rmspe and mse_loss conceptually the same way of calculating the loss?
In general should we use same loss function algorithm for both metrics= and learner.crit=? Or I am missing something.
And to add on to Alex’s question, when I was searching for how to make custom training loss , almost all the posts I stumbled upon were saying that we need to make the loss function using nn.module() class with forward function. (In some cases backward fn also). But you said it is not required and it can be a normal function which just needs to be compatible with tensor related operations. How does that work then?



 )
)