I have been working on American sign language dataset. I have used resnet34 model and I have got an accuracy of 99.97%. I have used opencv for making live prediction of signs made by hand via. webcam. Here are some of the top losses

Here is a video of my ASL-live-predictor:
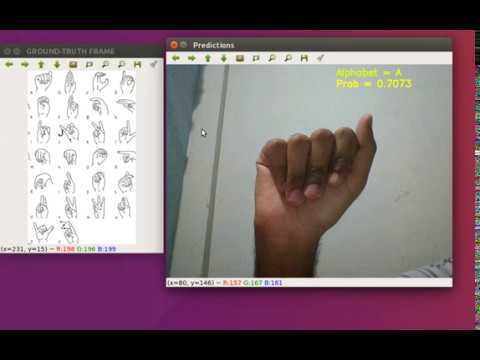
Link to ASL-live-predictor github repository: