This is a place to talk about more advanced or tangential topics related to the Lesson 2 lecture. This will not be monitored during class, but we will read it afterwards.
Feel free to discuss anything you like, as long as it’s at least somewhat related to what’s happening in class.
Q1:
Let us say we have a NN: P1->P2->N.
Here P1, P2 are pre-trained and N is the new layer.
The standard pipeline:
Stage 1: Freeze P1, P2. Find LR using Leslie for N. This is straightforward.
Stage 2: Unfreeze all. Using discriminative LR. When we provide a slice are controlling the LR to apply to N. The LRs for P1 and P2 are some fixed factor of the LR of N?
Q2:
Does it make any sense to use any optimizer other than SGD during LR finding? So if we are using Adam say then the procedure would be “Find LR using SGD and pass the estimated LR to Adam”?
Q: to use resnet architecture but without per-trained weights, i would set pretrained=False. Do i need to unfreeze or is this done automatically? do i need to initialize random weights, etc?
I think when you create a model the initialization is taken care of.
def create_cnn(data:DataBunch, arch:Callable, cut:Union[int,Callable]=None, pretrained:bool=True,
lin_ftrs:Optional[Collection[int]]=None, ps:Floats=0.5,
custom_head:Optional[nn.Module]=None, split_on:Optional[SplitFuncOrIdxList]=None,
classification:bool=True, **kwargs:Any)->None:
"Build convnet style learners."
assert classification, 'Regression CNN not implemented yet, bug us on the forums if you want this!'
meta = cnn_config(arch)
body = create_body(arch(pretrained), ifnone(cut,meta['cut']))
nf = num_features_model(body) * 2
head = custom_head or create_head(nf, data.c, lin_ftrs, ps)
model = nn.Sequential(body, head)
learn = ClassificationLearner(data, model, **kwargs)
learn.split(ifnone(split_on,meta['split']))
if pretrained: learn.freeze()
apply_init(model[1], nn.init.kaiming_normal_)
return learn
If you put pretrained = false then it would not freeze the layers and so there is no need to do it. Similarly, the model is also initialized inherently.
Q: to make model generalize well, even to an extent where ‘test’ images look ‘different’ in some ways that the images that model was trained on. but the ‘test’ images are not available just expected to look ‘different’ in some ways. are the ‘standard’ over fitting techniques good enough or do i need to do something extra? like higher dropout, more aggressive transformations in data augmentation, less cycles/epochs, higher learning rate? to say even to sacrifice the validation score?
So normally in DL, there’s a very vague understanding of what we mean by generalization. Sure there is the fact that we would want the model to be invariant to all kinds of transforms and even some distortions, there are limitations to this. One of the most crucial assumptions when we develop DL models is that the train, val and test set come from the same distribution which simply means the same dataset.
Although what you suggested might make the model more robust to invariance i wonder if it would lead to better generalization.
One other thing to mention is most real world examples are noisy in nature, the thing about datasets we most often don’t see are these datasets have been created through careful curation. So to make it robust to noise as well, adversarial training can be done.
what if we wanted for example take model trained on images from ‘south’ to ‘north’ or from ‘east’ to ‘west’. We could expect some differences in images. But how to train a model that would work on both image sets, but without having access to both image sets. We can only train on say ‘south’ data set but make inference on ‘north’ data set. are there techniques for that?
I have a question for after class regarding the “delete photos from dataset” concept (new widget) introduced:
In which cases does it make sense to do delete images that “don’t belong”?
In which cases is it better to create a new “other” category in order for the network to be able to discern between the actual classes and random bullshit (“none of the above”)?
Especially in “real-world” multiclass settings involving real people you will always get those (people uploading hotdog photos to the cat/dog classifier app etc.)?
I have wondered this e.g. in the google quickdraw dataset. There is no “none” /“other”/“random” category, although clearly a lot of times people just doodle random stuff not belonging to any of the 340/345 categories. Would it not be helpful to distinguish this instead of predicting one of the existing known classes? Or would this hinder the network from learning the actual classes?
Is it better to train only on the correct categories and then have a mechanism that based on very low probabilities across categories will say “none of the above”? (Isn’t this difficult when using softmax, because that will still give you some “winner” category most of the time)
You can while you are still in the same notebook, same session, and have everything initialized anyways.
What this method refers to is if you have trained a model, that “phase” of the project is finished, and now you just want to run that model as part of an app (and most likely not within a notebook). You don’t want to load any training data then or validation data, you just want to reload your trained model and weights and do inference, meaning making preditions using a learned model.
Unfortunately, I couldn’t use untar_data due to an issue. So, I had to come up with a replacement function.
But I’ll try to fix it and do a PR this week.
Data Curation, Deleting images that don’t belong is a part of that. In our case in the download images example what we did was download it from the website and we had no filter to check if the data actually belonged to the classes we wanted.
So when we “deleted” the images which didnt belong we were simply curating the data. Another reason why we delete the images that don’t belong is that ultimately these images in our dataset are assigned to some class, and if we keep them in the dataset, two things happen the network might learn a wrong representation of that class and it might misclassify. Now none of this usually happens since the amount of these examples is very low. But i think its more of “safe than sorry” practice.
I think the call to have an “other” category is more of a choice and not a necessity in the sense that if you are sure that you’ll only input images belonging to the classes you have then it would make little sense to have additional classes. On the flip side not breaking the model when you input images not belonging to the classes is a big reason to have an “other” category.
In the case of the quickdraw dataset, i wonder if doodle’s were actually added. I think the dataset was preprocessed and these outliers were removed before being released. I’m not entirely sure.
Question: I’m excited to deploy a previous model I wrote and create a web app around it after yesterday’s class. I wrote my Data Preparation code in Apache Spark. What is the recommended way to prepare the data during inference for realtime predictions?
Not sure if Spark is the right choice as in inference we wont have huge batches of data but single instances of data points to transform for prediction. But at the same time, If we choose some other data processing engine, I have to re-write data processing code in that language.
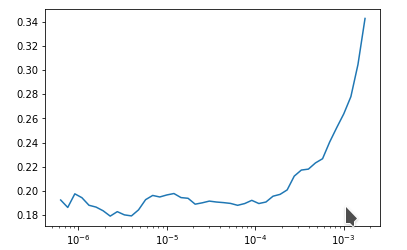
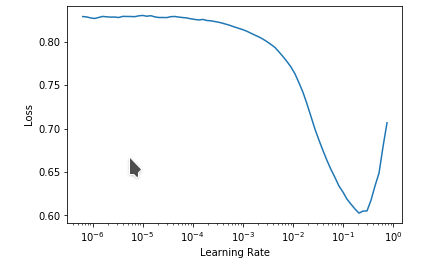
I might be completely wrong here, in Leslie Smith’s paper it was said that the loss reaches the minimum and then shoots up, thus if we follow back from the shoot-up, the minimum loss must be the lowest loss, here for the first figure it is 1e-4 and the most recent bulge is at 1e-5 thus the slice should be slice(1e-5,1e-4) but I don’t know why the nb has it as slice(1e-6,1e-4). If the initial part before overshoot is completely flat it would have been better if we could zoom. but can we do that in a jupyter-nb?
The challenge is that instead of a single 3-channel RGB image, you have 4 grayscale images of the same subcellular structure under different filters (i.e. different chemicals). Each image highlights a different part of the cell, shown below: the protein (green), microtubles (red), nucleus (blue), endoplasmic reticulum (yellow)
The green image is the one that needs to be classified, and the rest are for reference (but surely useful!). It’s a multilabel classification problem with 28 classes (like “Cytosol” and “Plasma membrane” above).
I have 2 questions:
How to load the 4 images together into a single 4-channel image using FastAI’s ImageDataBunch?
How can we do transfer learning using Resnet34, since the backbone expects a 3-channel RGB image, but here there are 4?