I have a question about deployment. Would it be a good idea to use a minimalist python codebase for inference time?
I wonder if I should export the trained fastai network and use pytorch-cpu (without the fastai library) at my web app. I guess the overhead for fast.ai would be minimal but it’d be one less package to install/ worry about…
AFAIK there is no pretrained architecture for 4 channel images currently available. So the easiest thing to make use of fastai is to first generate RGB images and save them to disk. After that you can use the standard approach learned in class. Have a look at the kernels, there are different methods of doing that, incl. the simplest being simply not using the yellow channel or using cv2 to merge/blend the 4 images to generate 3channel images.
The other approach would be to modify an architecture to load in 4 channels in the first layer instead of 3, but then you have to do a lot of stuff manually. There is actually also a kernel using fastai 0.7 showing that.
I think there was nothing discussed here that is not on kaggle already but just as a reminder, questions re ongoing competitions should be asked on kaggle.
Not really looking to discuss any strategy, simply wanted to figure out a good way to load the data and train using FastAI v1. The idea of separately generating RGB images seems like a good starting point. But it would be nice to have the ability to specify custom image loading logic in ImageDataBunch.
I checked out the fastai 0.7 kernel you mentioned. From what I understand, it rewrites some internal classes from scratch. It’s probably going to be a bit harder to do with v1, especially since it’s under active development. But I’ll eventually give it a shot.
Interesting question.
Do we need to clean our data from photos with text or watermarks?
There are nearly half from all photos that include text or watermark.
So what should we do?
Jeremy said training loss being lower than validation loss does not always mean that we are overfitting. Honestly this conflicts what i have learned before. Is this specific to deep learning due to things i don’t know yet?
I always think training loss being lower than validation loss would mean model memorizing specific pixel values that unites a certain structure rather than learning a general structure. Does traditional machine learning algorithms differ from deep learning regarding this?
I think the element if ‘time’ /direction is important, so if train loss is lower than val loss,but both keep going down epoch after epoch, you are not yet overfitting. if train loss is going down, but val loss up, that is definitely overfitting.
So if resnet is not pre-trained then why are we only training the last layer? Because after training the last layer of the model, we then unfreeze the model. Don’t we just have to train the entire model right away if it’s not pre-trained?
Does anyone have experience / code for multiple ‘training-sessions’ with different parameters and getting the results mailed or saved?
I want to do multiple experiments, eg: to see the number of images is impacting the accuracy, so first training with 100, 200, 300 … 1000. Trying different ways of downloading images. Or trying multiple learning rates, sizes etc.
Running automatically through the night and reporting back to me in the morning
There are lots of competitions / benchmarks trying to improve the speed (in combination with accuracy) of machine learning models. Are there also competitions / benchmarks on trying to limit the number of training examples?
I’m impressed by results so far, but I would be more overwhelmed if we could lower the number of training examples. E.g. my 3 year old son only needs to see 2 dinosaurs to get the concept of a dinosaur and recognise them. How can we be inspired by this? Eg give some additional meta info, like text from wikipedia
‘Cats are similar in [anatomy] to the other felids, with a strong flexible body, quick reflexes, sharp teeth and retractable claws adapted to killing small prey.’
Is there any research / benchmarks in this direction?
Hello, I hope this is the right thread to discuss the points below.
Thinking about what jeremy explained during the last lesson I had a few questions/observations to share with all of you.
1 - It seems that computing the most effective “function” means finding the function having the minimum error-rate function calculated towards all the “data-points” we have in our data-sets.
But what happens when we have a 3D (or multidimensional) space?
Is there any other relevant concept we should start considering?
Or we should calculate all possible permutations of errors functions and get their average (e.g. in a 3D-shaped InfoSpace: error function for plan XY, error function for plan XZ, error function for plan YZ)?
2 - Connected to (1), how do we manage multi-label classification in images? I mean…it’s clear to me that classifying an image is getting the value for the “top” argmax index from the computed probabilities. But what’s about having multiple labels within a single image? How do we handle that?
With regards your second question, you might like to check out the planet notebook in the v3 GitHub repo (it looks like that notebook was originally provisionally slated for lesson 2, but hey-ho).
In lesson 2, Jeremy explains that if training loss is lower than the validation loss, it does not necessarily mean overfitting as long as val_accuracy increases (or error rate decreases).
So does that mean I can train my model for as long as accuracy is increasing?
When training the model, my accuracy is increasing, training loss is way lower than validation loss, but validation loss is increasing as well. What does this signify? Am I overfitting? Or am I ok as long as accuracy is increasing?
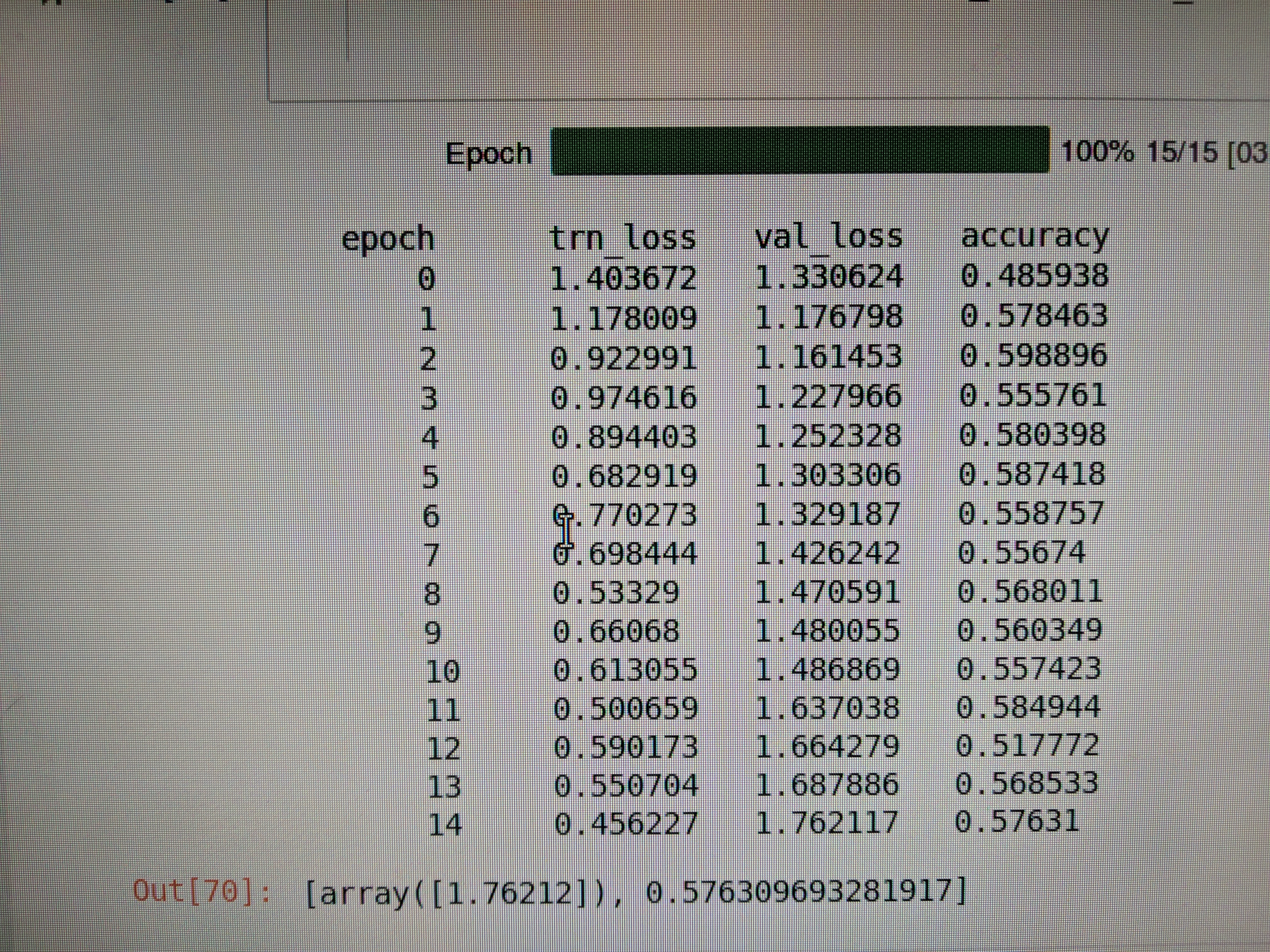
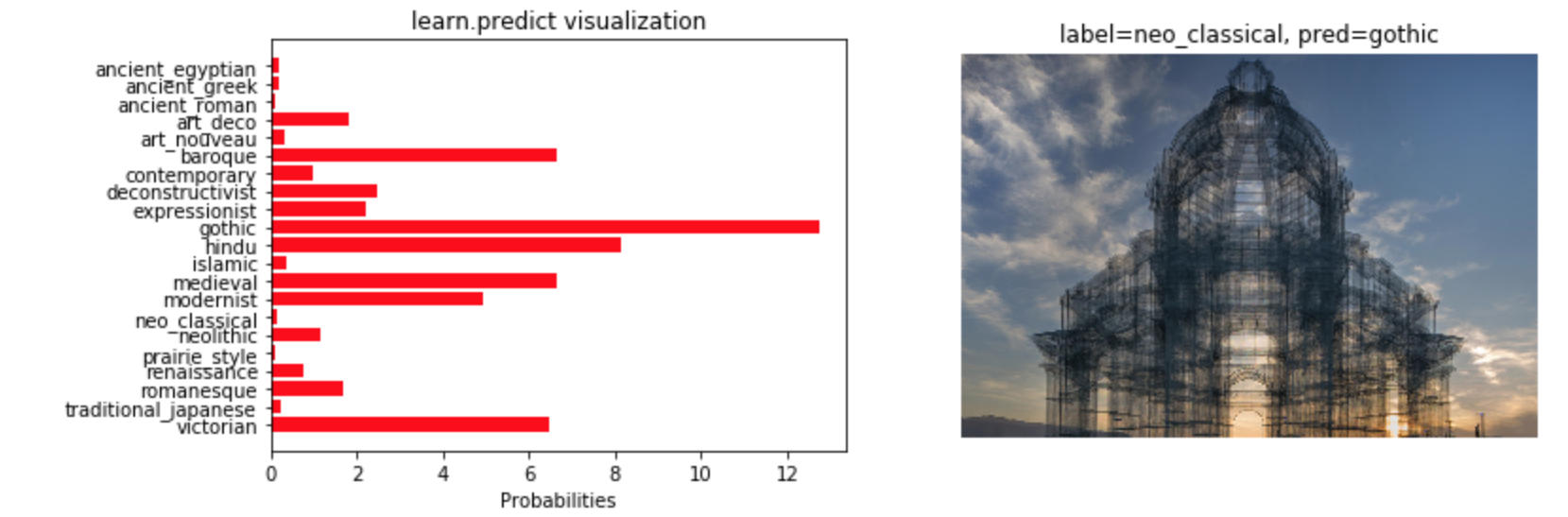
I had a few questions while I’m working through my dataset (architectural style classification):
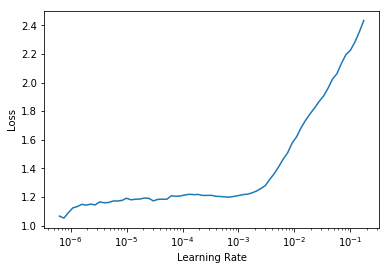
This question was posted upthread by bbrandt but I’m running into it as well - how should one interpret an upward sloping learning rate plot? There is almost no extended downward sloping region to determine a LR. Here’s my actual plot:
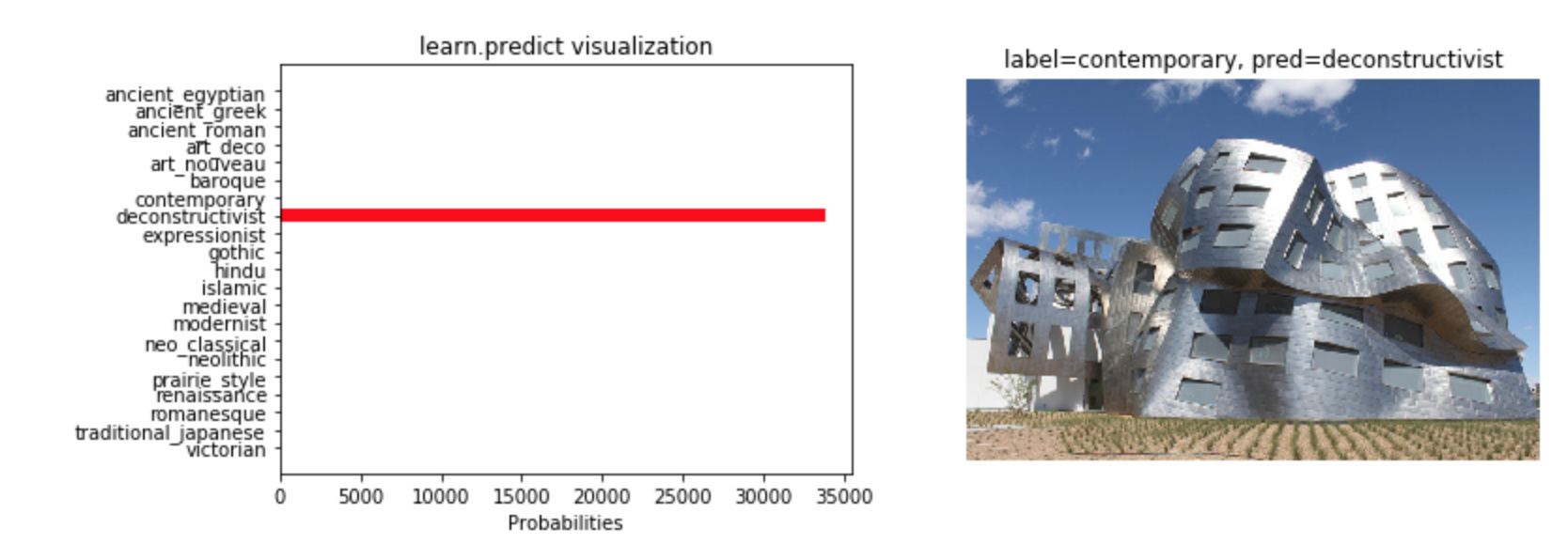
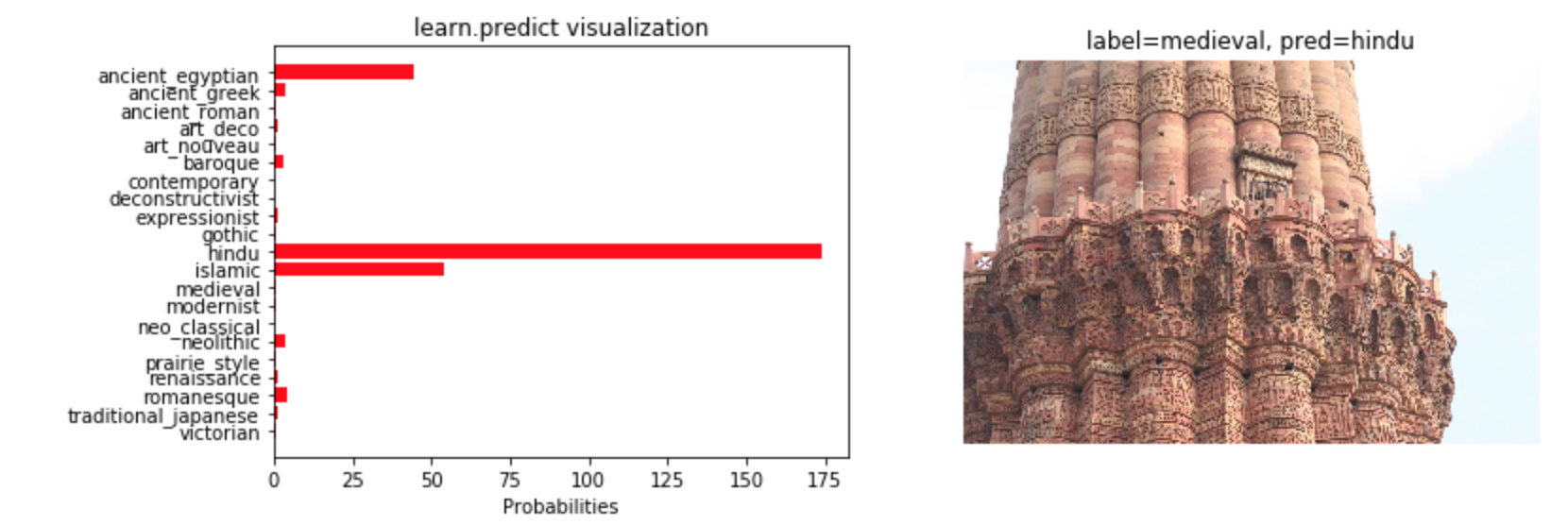
What are the probabilities returned by learner.predict (third element in the tuple)? The documentation (https://docs.fast.ai/vision.learner.html#ClassificationLearner.predict) shows a tensor that sums to 1.0, but I’m finding my model returns values that range from 0 to as high as 35000. I can dig deeper (it appears to be the first element returned by Learner.pred_batch()), but I wanted to ask first. I suspect its the last layer’s output before a nonlinear activation function is applied to these values (to bound to [0,1])?
I wanted to visualize these probabilities for the dataset I was working with . Here are some examples - some are mislabeled but I found the classification outputs interesting nonetheless. These are directly plotting the classification probabilities returned by learner.predict:
@myltykritik One way to look at this is to compare the training/validation pictures with the test/inference datasets.
If the inference-time images also contain information in text or watermarks, in other words, they are both roughly the same, then it is ok to keep the labels/watermarks, and let the model learn to use them.
For example, if you want to train for traffic signals, its ok to have the “STOP” inside the stop sign.
But to train a classifier that would work well on images that have no such text/watermarks,
you should remove them from the images…