I took the nice animation of SGD from lesson 2 and tried to take it a step further, plotting the loss function and the path followed by SGD.
Some visualizations at different learning rates:
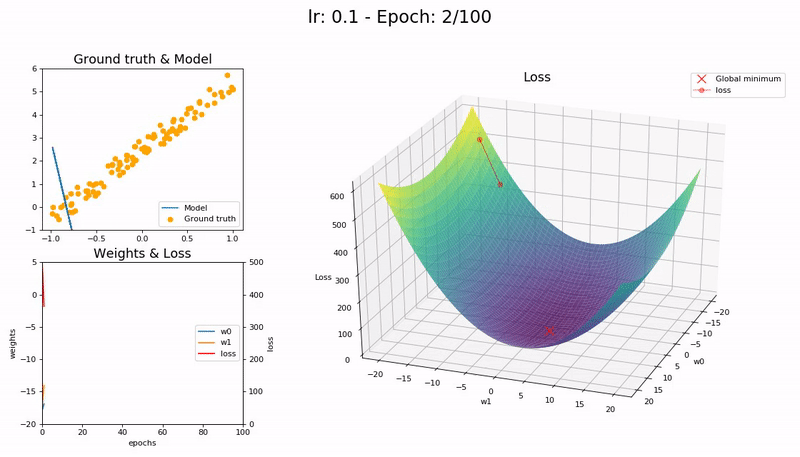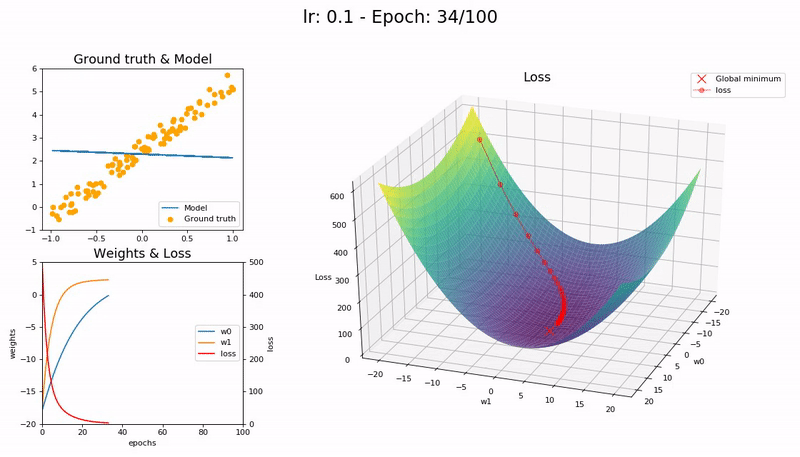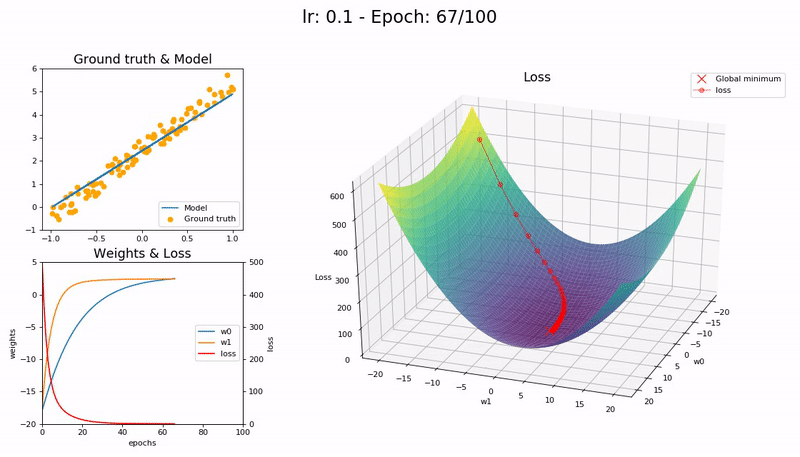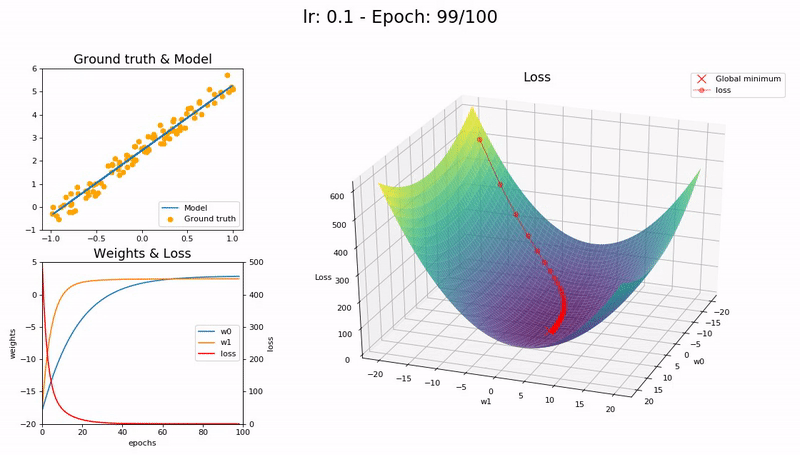

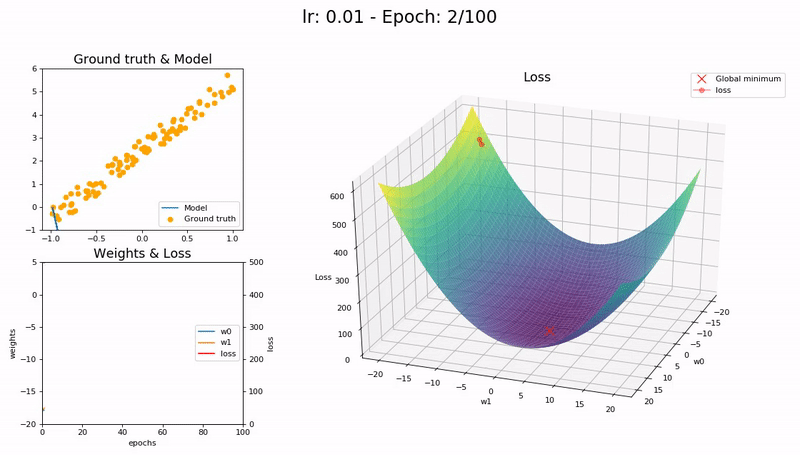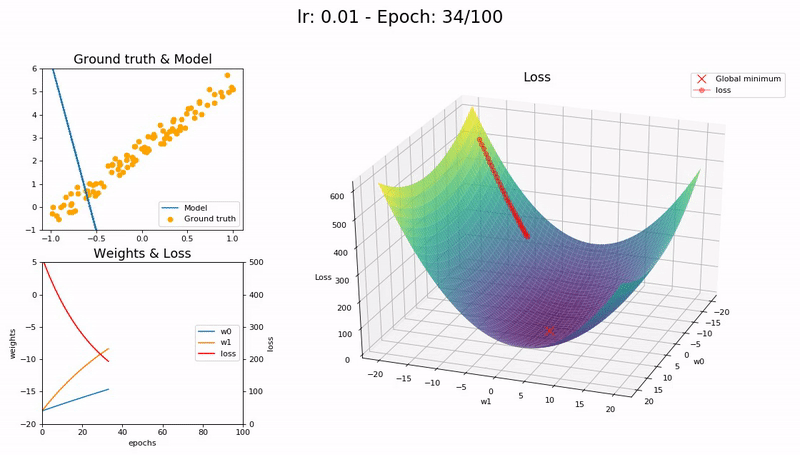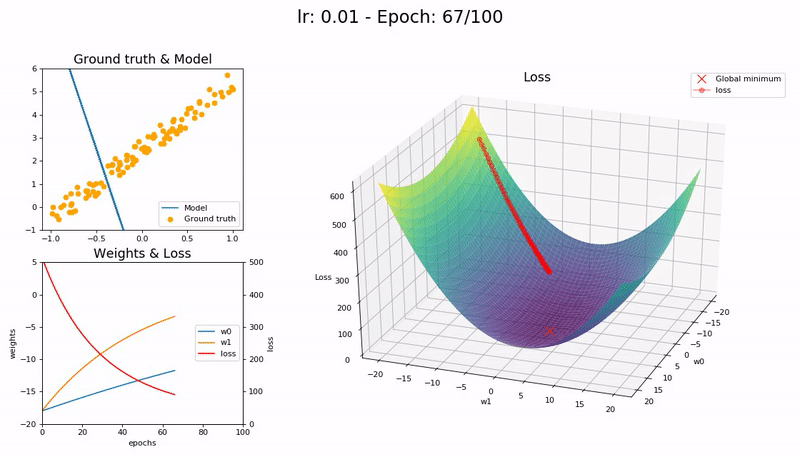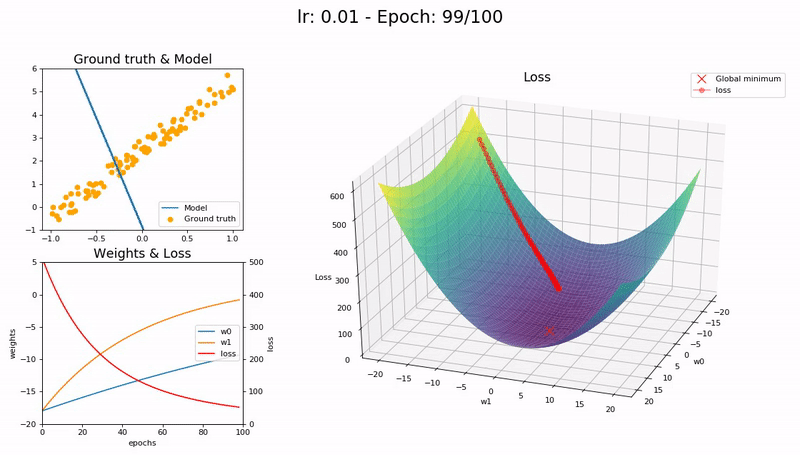

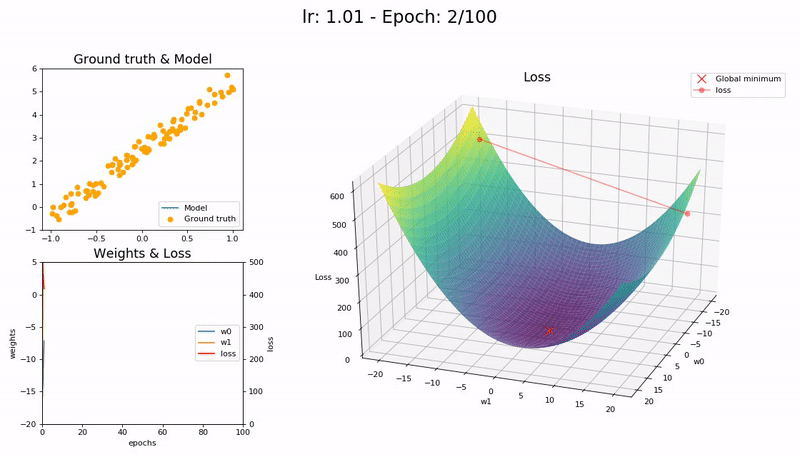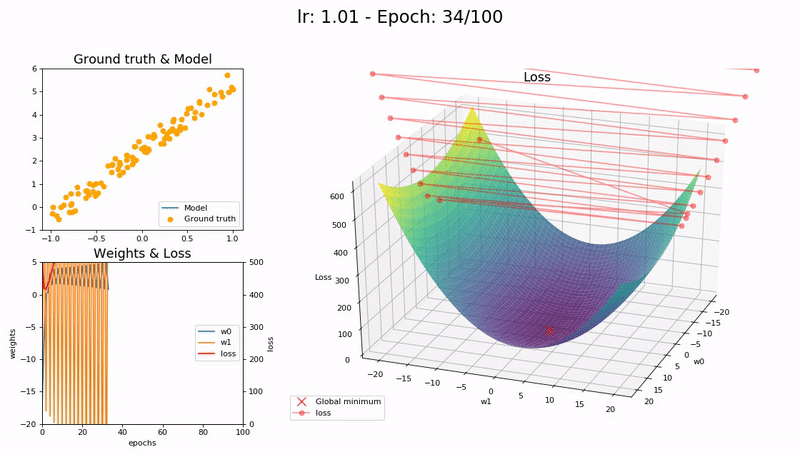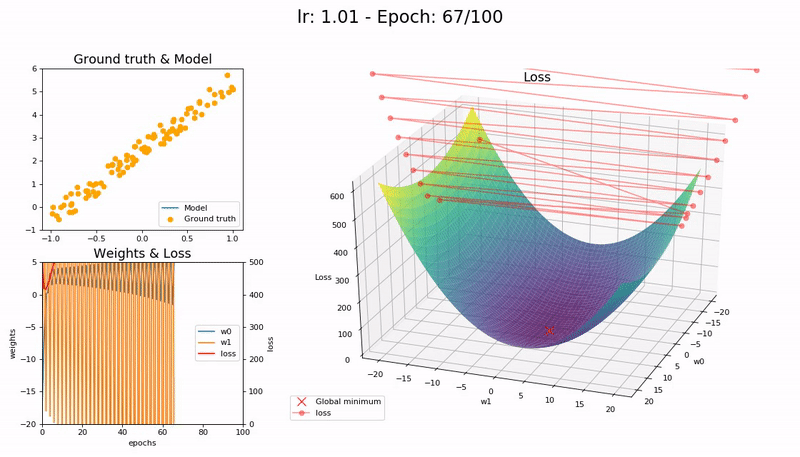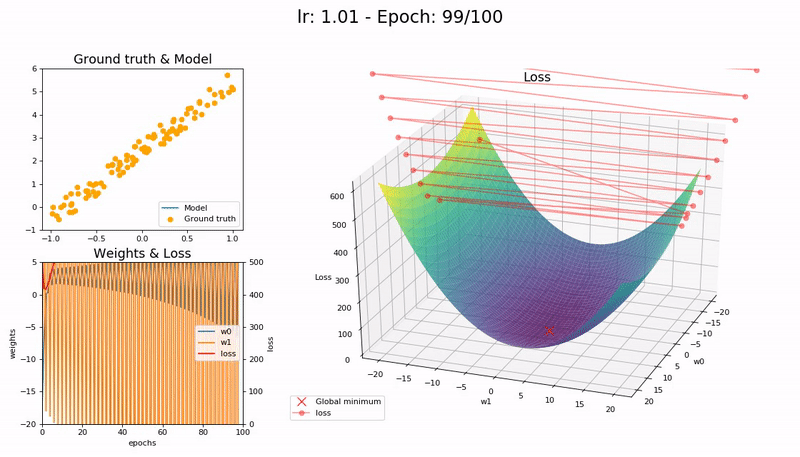
It was a nice learning experience and an opportunity to learn a little bit more on matplotlib as well 