[ <<< Lição 2 | Lição 4 >>> ]
Lesson 3 - Multi-label, Segmentation, Image Regression, and More… (06/11/2019 - UnB - Brasília)
Este tópico permite que os membros do Grupo de IA da UnB (Brasília) estudem coletivamente (em reuniões presenciais e on-line) a lição 3 (parte 1) do curso fastai, mas de um jeito aberto para ajudar também pelas questões, respostas e pelos recursos publicados todos os leitores em português interessados em DL.

Lesson resources
Other resources
Further reading
For next week
The data block API lets you customize the creation of a DataBunch by isolating the underlying parts of that process in separate blocks, mainly:
- Where are the inputs and how to create them?
- How to split the data into a training and validation sets?
- How to label the inputs?
- What transforms to apply?
- How to add a test set?
- How to wrap in dataloaders and create the
DataBunch ?
Each of these may be addressed with a specific block designed for your unique setup. Your inputs might be in a folder, a csv file, or a dataframe. You may want to split them randomly, by certain indices or depending on the folder they are in. You can have your labels in your csv file or your dataframe, but it may come from folders or a specific function of the input. You may choose to add data augmentation or not. A test set is optional too. Finally you have to set the arguments to put the data together in a DataBunch (batch size, collate function…)
The data block API is called as such because you can mix and match each one of those blocks with the others, allowing for a total flexibility to create your customized DataBunch for training, validation and testing. The factory methods of the various DataBunch are great for beginners but you can’t always make your data fit in the tracks they require.
1 Like
In fastai the data-containing object that we need to feed to a neural network is called a DataBunch . This is called a ‘bunch’ because it bunches together several PyTorch classes into one.
In PyTorch there are two primary data objects:
- the
DataSet (which contains all of the data items together with their associated label(s)),
- and the
DataLoader (which gives chunks of the items in the DataSet to the model in ‘batches’ ).
For a typical supervised learning problem we will want a ‘training set’ and a ‘validation set’, with a separate DataSet and DataLoader for each. (as well as an optional ‘test set’, which we will ignore here for simplicity) All of these are bundled up into the fastai DataBunch !
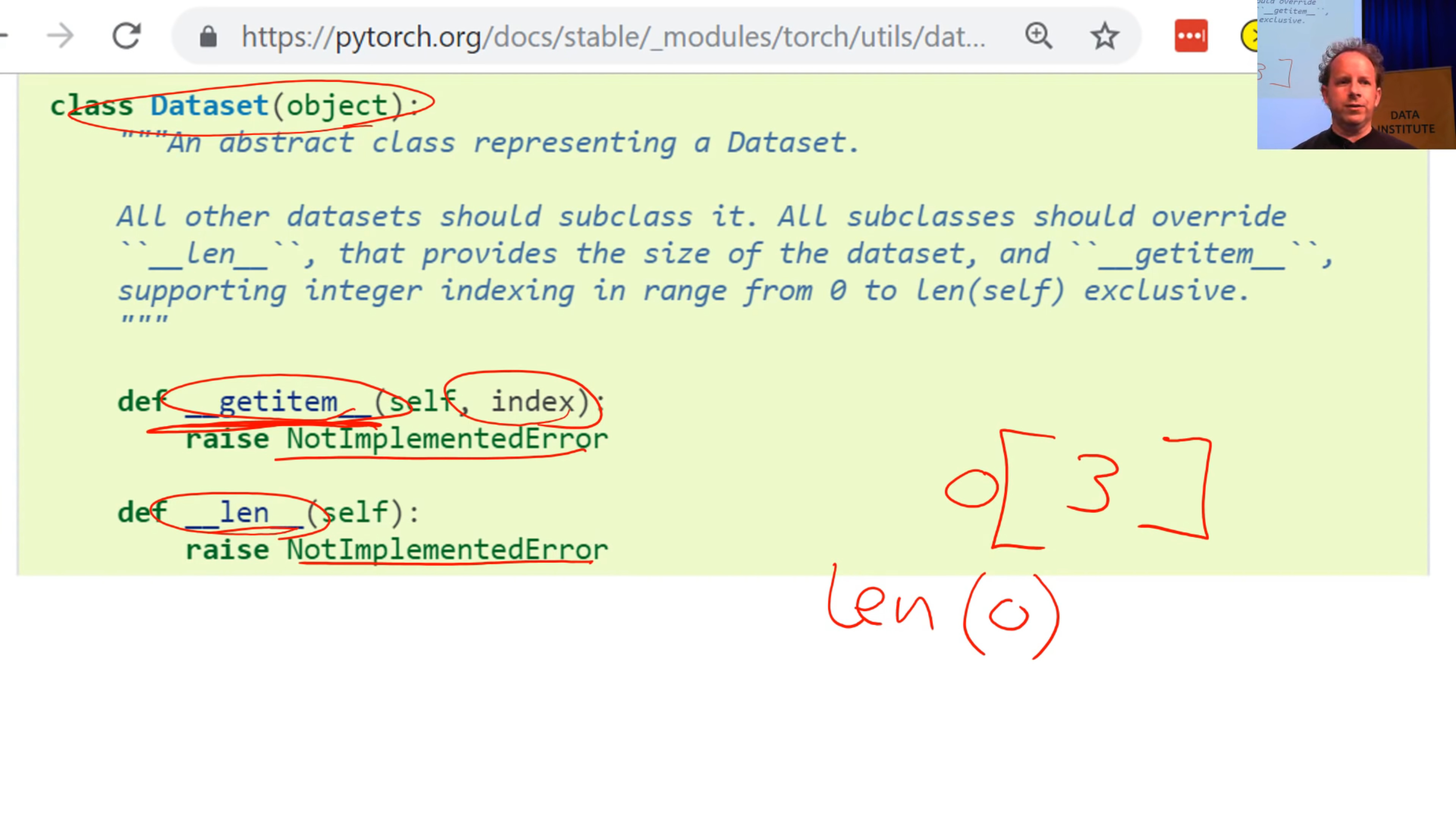
1/3 - PyTorch Dataset
(from Dataset (PyTorch) 18:30)
Although PyTorch says “in order to tell PyTorch about your data, you have to create a dataset”, it doesn’t really do anything to help you create the dataset. It just defines what the dataset needs to do. In other words, the starting point for your data is something where you can say:
- What is the third item of data in my dataset (that’s what getitem does)
- How big is my dataset (that’s what len does)
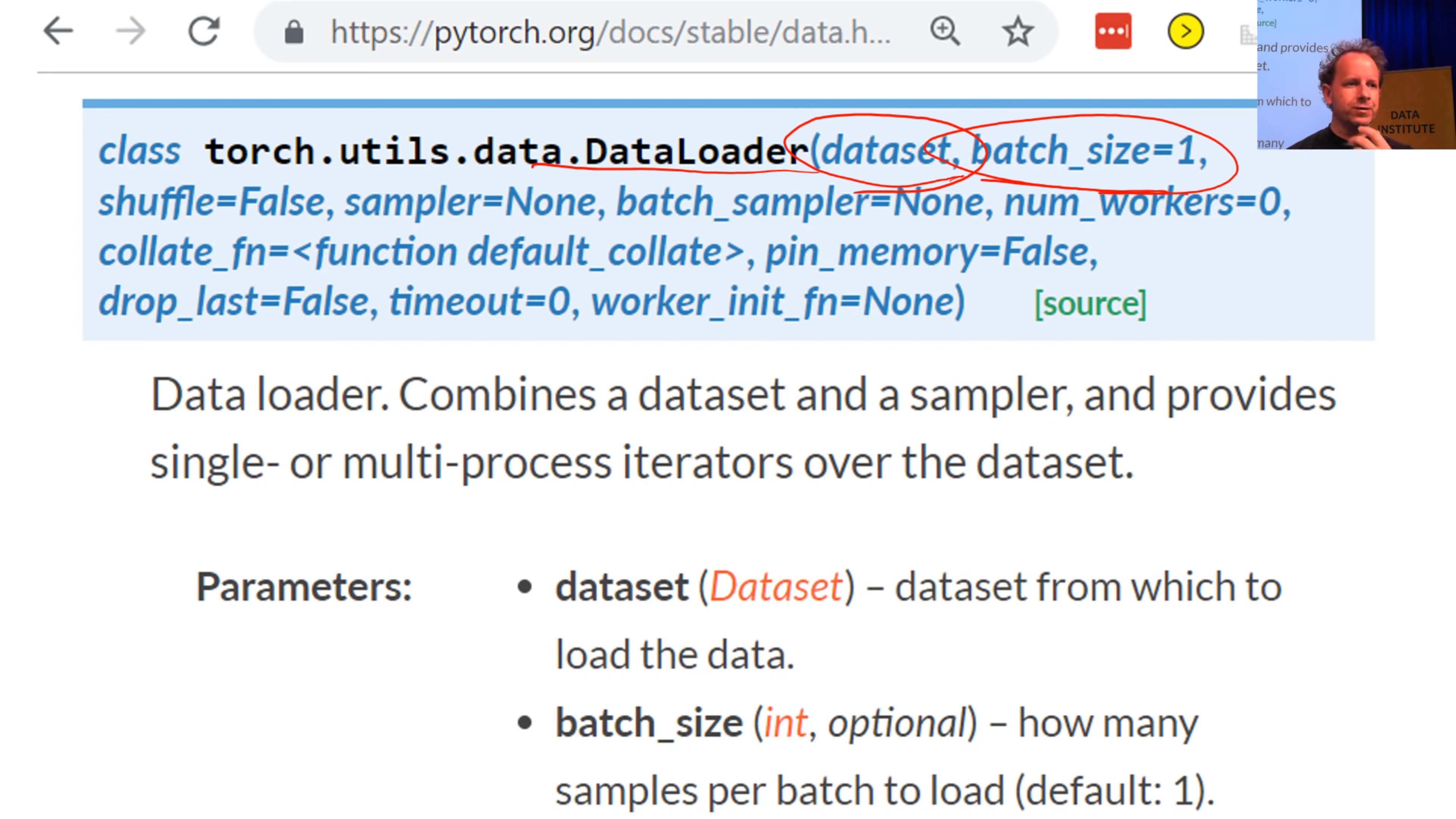
2/3 - PyTorch DataLoader
(from DataLoader (PyTorch) 20:37)
Now a dataset is not enough to train a model. The first thing we know we have to do, if you think back to the gradient descent tutorial last week is we have to have a few images/items at a time so that our GPU can work in parallel. Remember we do this thing called a “mini-batch”? Mini-batch is a few items that we present to the model at a time that it can train from in parallel. To create a mini-batch, we use another PyTorch class called a DataLoader.
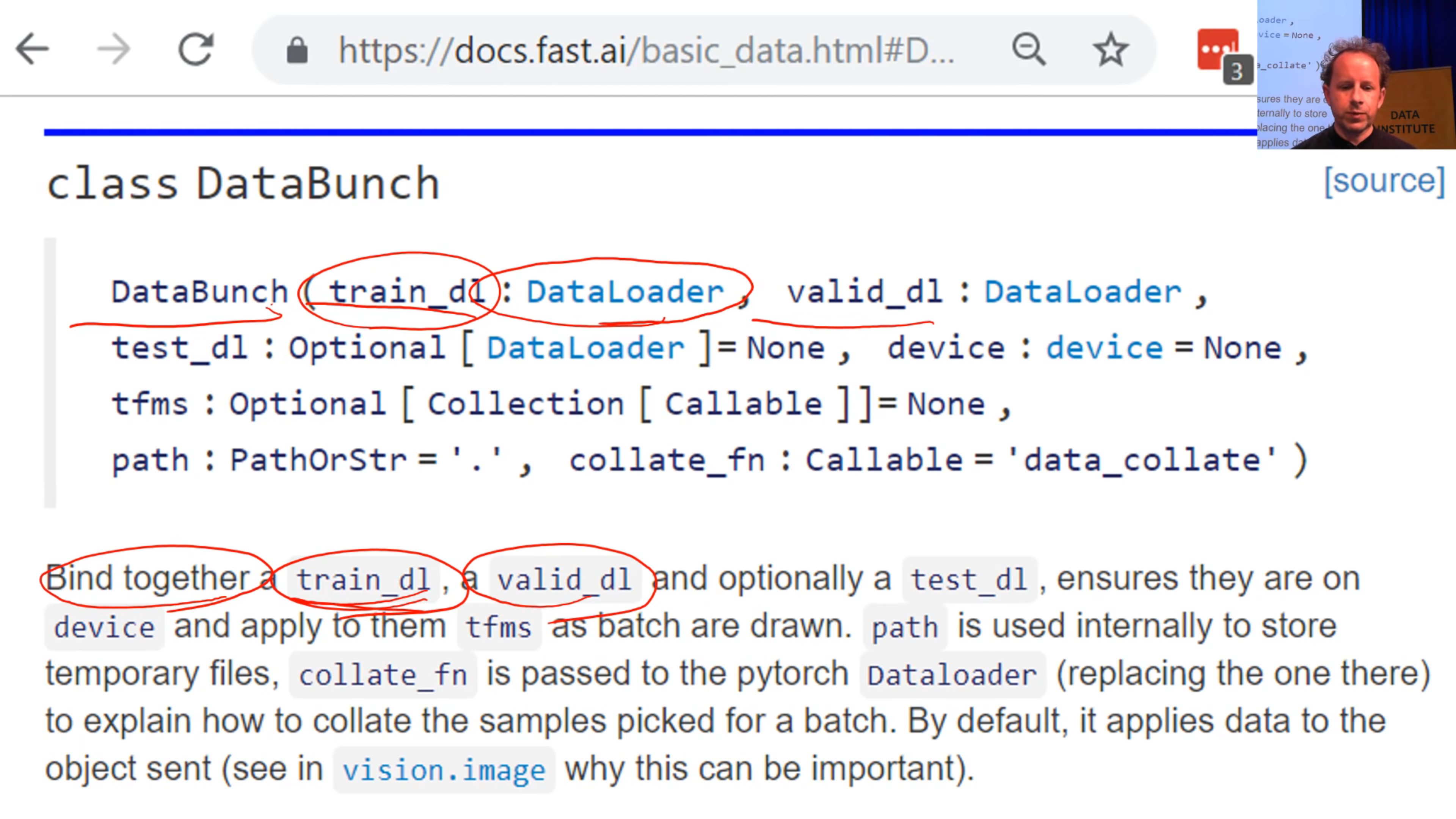
3/3 - DataBunch
(from DataBunch (fastai) 21:59)
It still isn’t enough to train a model, because we’ve got no way to validate the model. If all we have is a training set, then we have no way to know how we’re doing because we need a separate set of held out data, a validation set, to see how we’re getting along.
For that we use a fastai class called a DataBunch. A DataBunch is something which binds together a training data loader ( train_dl ) and a valid data loader ( valid_dl ).
Está procurando datasets para treinar seus modelos de Deep Learning?
Fast.ai Datasets!
Quer entender melhor o que faz a função learn.fit_one_cycle() que permite de treinar um modelo de Deep Learning? Leia "A little more about learn.recorder" 
Wrapping up of the lesson 3 [2:01:19]
What have we looked at today? We started out by saying it’s really easy now to create web apps. We’ve got starter kits for you that show you how to create web apps, and people have created some really cool web apps using what we’ve learned so far which is single label classification.
But the cool thing is the exact same steps we use to do single label classification, you can also do to:
-
Multi-label classification such as in the planet dataset.
-
Image segmentation.
- Any kind of image regression.
-
NLP classification.
- and a lot more.
In each case, all we’re actually doing is:
- Gradient descent
- Non-linearity
Universal approximation theorem tells us it lets us arbitrarily accurately approximate any given function including functions such as:
- Converting a spoken waveform into the thing the person was saying.
- Converting a sentence in Japanese to a sentence in English.
- Converting a picture of a dog into the word dog.
These are all mathematical functions that we can learn using this approach.
Fotos da turma da lição 3
Alguém já teve esse problema?
As soluções que estou encontrando são todas pra pessoas que fizeram o regressor em pytorch, ai pra replicar a solução teria que alterar o código fonte do fastai.
Bom dia @allansouza. Sem ver o seu notebook, é difícil ajudá-lo.
Os rótulos do seu dataset têm de ter o tipo scalar type long e não float segundo a mensagem de erro.