Este tópico permite que os membros do Grupo de IA da UnB (Brasília) estudem coletivamente (em reuniões presenciais e on-line) a lição 4 (parte 1) do curso fastai , mas de um jeito aberto para ajudar também pelas questões, respostas e pelos recursos publicados todos os leitores em português interessados em DL.
Em 2019, a gente não começa um projeto de IA a partir de zero.
O ponto mais importante é a definição e a escolha de um dataset correspondente ao objetivo do projeto.
Não existe uma IA geral ou quase geral. Uma IA treinada a partir de um dataset para uma tarefa particular pode fazer só isso (ie, precisa de dados iguais na produção).
A verdadeira meta do projeto: apresentar um aplicativo realístico e útil que o publico misturado no auditório (técnico ou não) vai entender e gostar.
O aplicativo de cada projeto tem de ser apresentado ao grupo antes da conferência para melhorar a sua apresentação (ie, treino) e verificar que dá certo.
[ 15mn ] Organização da conferência de dezembro (data, horário, lugar, responsável geral, responsável da logística, responsável da comunicação, mentor dos projetos = Pierre)
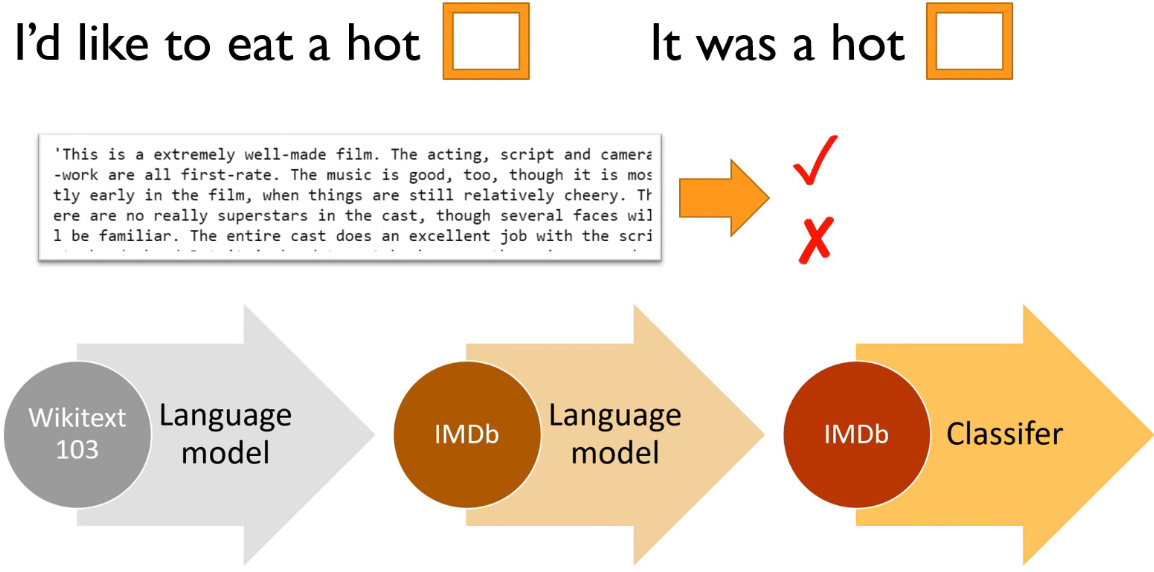
Na lição passada o @pierreguillou comentou que havia pretreinado um modelo em português com MultiFit e disponibilizado no GitHub.
Ao tentar implementar o language model pelo Google Colab usando a arquitetura QNRR, obtive o erro No module named ‘forget_mult_cuda’. Ao pesquisar na web, achei poucos foruns tratando do assunto e que não apresentaram uma solução.
Aparentemente o erro é intrínseco da prlataforma Google Colab. Por acaso, @pierreguillou, você já obteve esse tipo de erro ou tentou usar a arquitetura no Colab?