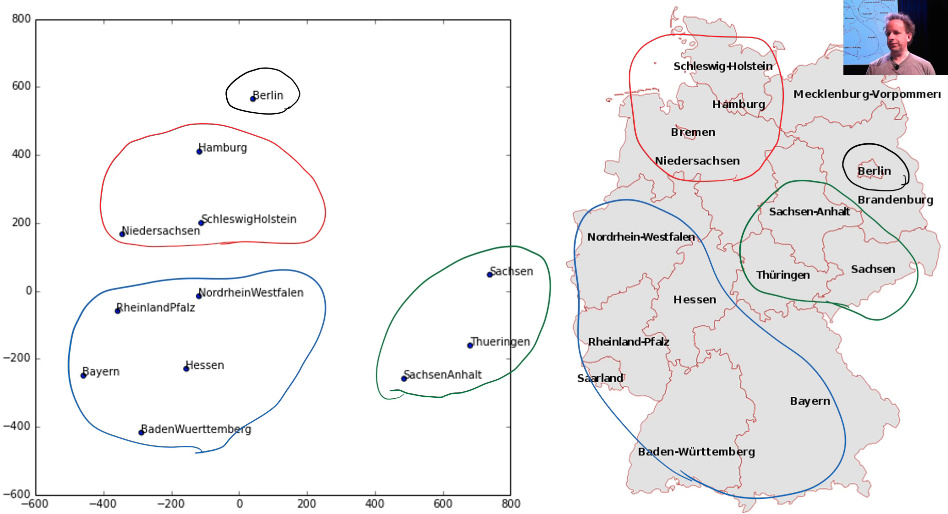
Cross-Entropy loss function
Source: Back to Tabular from lesson5.md
loss_func = nn.CrossEntropyLoss()
Cross-entropy loss is just another loss function. You already know one loss function which is mean squared error 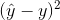 . That’s not a good loss function for us because in our case we have, for MNIST, 10 possible digits and we have 10 activations each with a probability of that digit. So we need something where predicting the right thing correctly and confidently should have very little loss; predicting the wrong thing confidently should have a lot of loss. So that’s what we want.
. That’s not a good loss function for us because in our case we have, for MNIST, 10 possible digits and we have 10 activations each with a probability of that digit. So we need something where predicting the right thing correctly and confidently should have very little loss; predicting the wrong thing confidently should have a lot of loss. So that’s what we want.
Here’s an example:
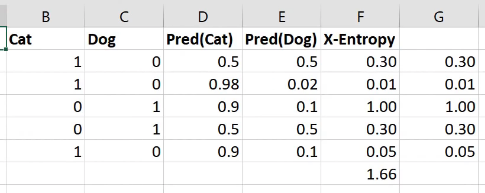
Here is cat versus dog one hot encoded. Here are my two activations for each one from some model that I built - probability cat, probability dog. The first row is not very confident of anything. The second row is very confident of being a cat and that’s right. The third row is very confident for being a cat and it’s wrong. So we want a loss that for the first row should be a moderate loss because not predicting anything confidently is not really what we want, so here’s 0.3. The second row is predicting the correct thing very confidently, so 0.01. The third row is predicting the wrong thing very confidently, so 1.0.
How do we do that? This is the cross entropy loss:
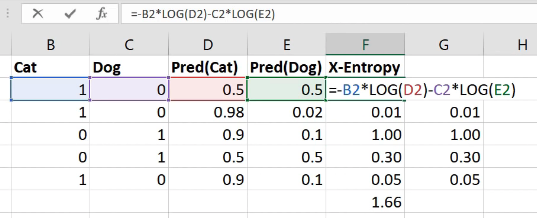
It is equal to whether it’s a cat multiplied by the log of the cat activation, negative that, minus is it a dog times the log of the dog activation. That’s it. So in other words, it’s the sum of all of your one hot encoded variables times all of your activations.
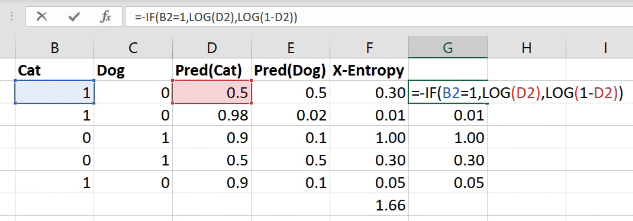
Interestingly these ones here (column G) - exactly the same numbers as the column F, but I’ve written it differently. I’ve written it with an if function because the zeros don’t actually add anything so actually it’s exactly the same as saying if it’s a cat, then take the log of cattiness and if it’s a dog (i.e. otherwise) take the log of one minus cattiness (in other words, the log of dogginess). So the sum of the one hot encoded times the activations is the same as an if function. If you think about it, because this is just a matrix multiply, it is the same as an index lookup (as we now know from our from our embedding discussion). So to do cross entropy, you can also just look up the log of the activation for the correct answer.
Now that’s only going to work if these rows add up to one. This is one reason that you can get screwy cross-entropy numbers is (that’s why I said you press the wrong button) if they don’t add up to 1 you’ve got a trouble. So how do you make sure that they add up to 1? You make sure they add up to 1 by using the correct activation function in your last layer. And the correct activation function to use for this is softmax . Softmax is an activation function where:
- all of the activations add up to 1
- all of the activations are greater than 0
- all of the activations are less than 1
So that’s what we want. That’s what we need. How do you do that? Let’s say we were predicting one of five things: cat, dog, plane, fish, building, and these were the numbers that came out of our neural net for one set of predictions ( output ).
What if I did  to the power of that? That’s one step in the right direction because to the power of something is always bigger than zero so there’s a bunch of numbers that are always bigger than zero. Here’s the sum of those numbers (12.14). Here is to the number divided by the sum of to the number:
to the power of that? That’s one step in the right direction because to the power of something is always bigger than zero so there’s a bunch of numbers that are always bigger than zero. Here’s the sum of those numbers (12.14). Here is to the number divided by the sum of to the number:
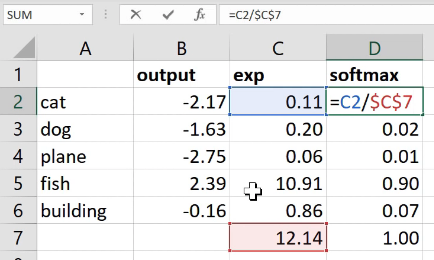
Now this number is always less than one because all of the things were positive so you can’t possibly have one of the pieces be bigger than 100% of its sum. And all of those things must add up to 1 because each one of them was just that percentage of the total. That’s it. So this thing softmax is equal to to the activation divided by the sum of to the activations. That’s called softmax.
So when we’re doing single label multi-class classification, you generally want softmax as your activation function and you generally want cross-entropy as your loss. Because these things go together in such friendly ways, PyTorch will do them both for you. So you might have noticed that in this MNIST example, I never added a softmax here:

That’s because if you ask for cross entropy loss ( nn.CrossEntropyLoss ), it actually does the softmax inside the loss function. So it’s not really just cross entropy loss, it’s actually softmax then cross entropy loss.
So you’ve probably noticed this, but sometimes your predictions from your models will come out looking more like this:
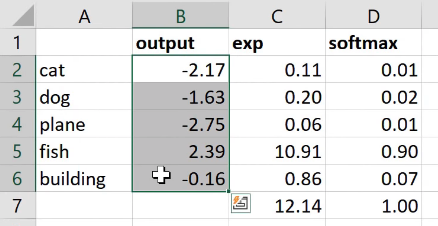
Pretty big numbers with negatives in, rather than this (softmax column) - numbers between 0 to 1 that add up to 1. The reason would be that it’s a PyTorch model that doesn’t have a softmax in because we’re using cross entropy loss and so you might have to do the softmax for it.
Fastai is getting increasingly good at knowing when this is happening. Generally if you’re using a loss function that we recognize, when you get the predictions, we will try to add the softmax in there for you. But particularly if you’re using a custom loss function that might call nn.CrossEntropyLoss behind the scenes or something like that, you might find yourself with this situation.