This topic is for discussion of the 16th live coding session.
<<< session 15 | session 17 >>>
Links from the walk-thru
- Paddy Doctor - Reporting images annotation issues
- UNIFESP X-ray Body Part Classifier Competition - to be discussed next week
- A ConvNet for the 2020s
- Lesson 5 - Deep Learning for Coders (2020) - Ethics for Data Science
- Applied Data Ethics, a new free course, is essential for all working in tech
- (please contribute here)
What was covered
- Outline of Lesson 7
- Curriculum Learning
- Wrong labels
- DICOM Images / JPEG 2000
- Research and paper
- Categories with not much data
- GradientAccumulation
- What to cover next
- Excel
- (please contribute here)
Video timeline by @fmussari
00:00 - Start
01:04 - About Weighting (WeightedDL)
01:50 - Curriculum Learning / Top Losses
03:08 - Distribution of the test set vs training set
03:35 - Is Curriculum Learning related to Boosting?
04:25 - Focusing on examples that the model is getting wrong
04:38 - Are the labels ever wrong? By accident, or intentionally?
06:40 - Image annotation issues: Paddy Kaggle discussion
08:23 - UNIFESP X-ray Body Part Classifier Competition
10:20 - Medical images / DICOM Images
10:57 - fastai for medical imaging
11:40 - JPEG 2000 Compression
12:40 - ConvNet Paper
13:50 - On Research Field
15:30 - When a paper is worth reading?
17:14 - Quoc V. Le
17:50 - When to stop iterating on a model? - Using the right data.
20:10 - Taking advantage of Semi-Supervised Learning, Transfer Learning, Fine Tuning
21:33 - Not enough data on certain category. Binary Sigmoid instead of SoftMax
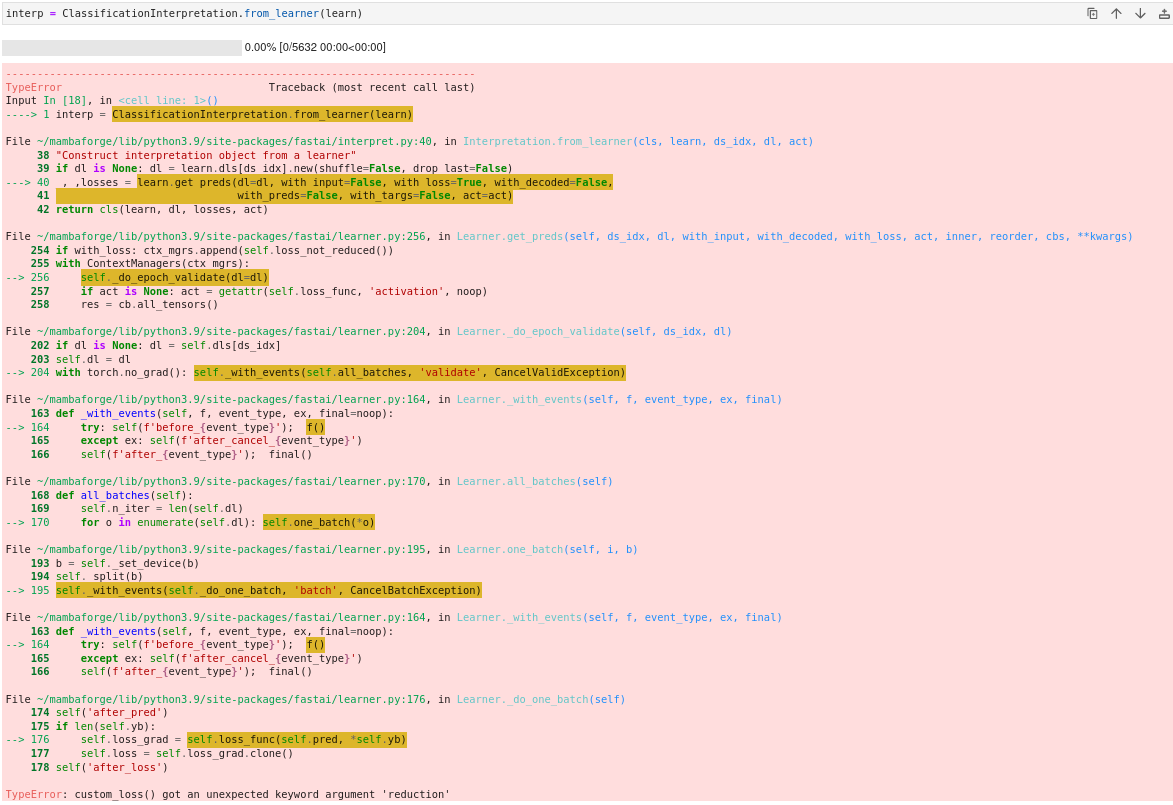
23:50 - Question about submitting to Kaggle
25:33 - Public and private leaderboard on Kaggle
29:30 - Where did we get to in the last lesson?
31:20 - GradientAccumulation on Jeremy’s Scaling Up: Road to the Top, Part 3 Notebook
37:20 - “Save & Run” a Kaggle notebook
38:55 - Next: How outputs (multi-target loss, softmax, x-entropy loss, binary sigmoid) and inputs (embeddings, collaborative filtering) to a model looks like
40:55 - Next: How the “middle” (convnet) of a model looks like
41:32 - Part 2: Outputs of a hidden layer
42:53 - The Ethical Side
44:30 - fastai1/courses/dl1/excel/