This topic is for discussion of the 15th live coding session.
<<< session 14 | session 16 >>>
Links from the walk-thru
-
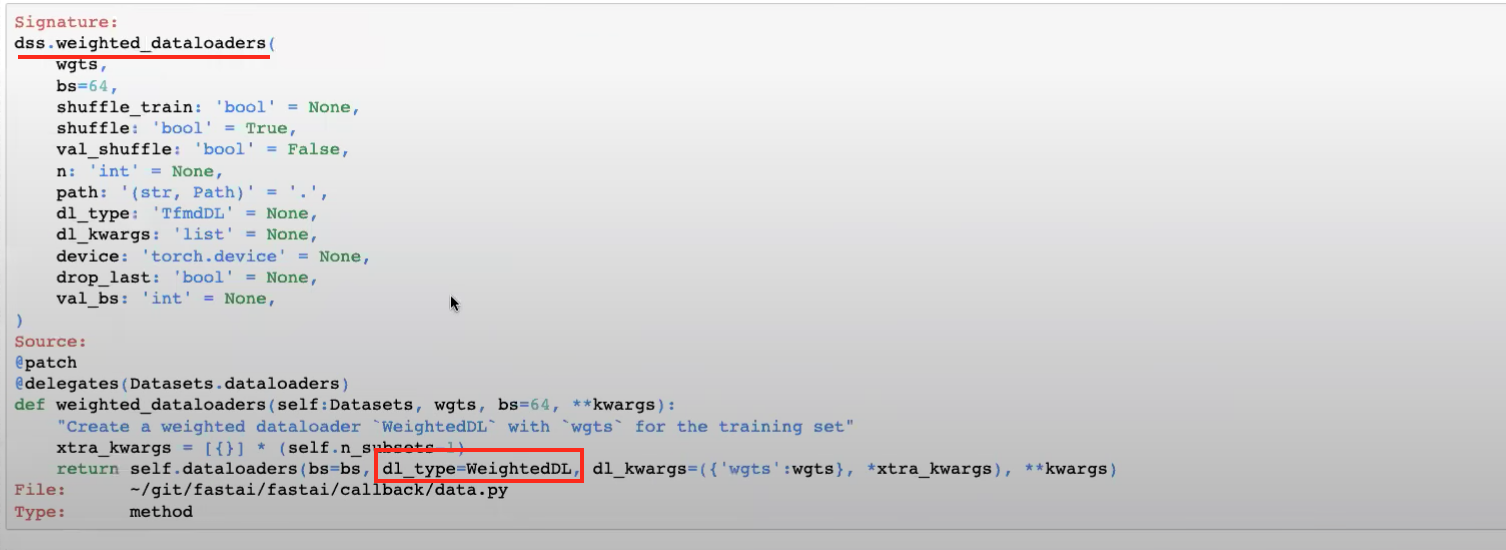
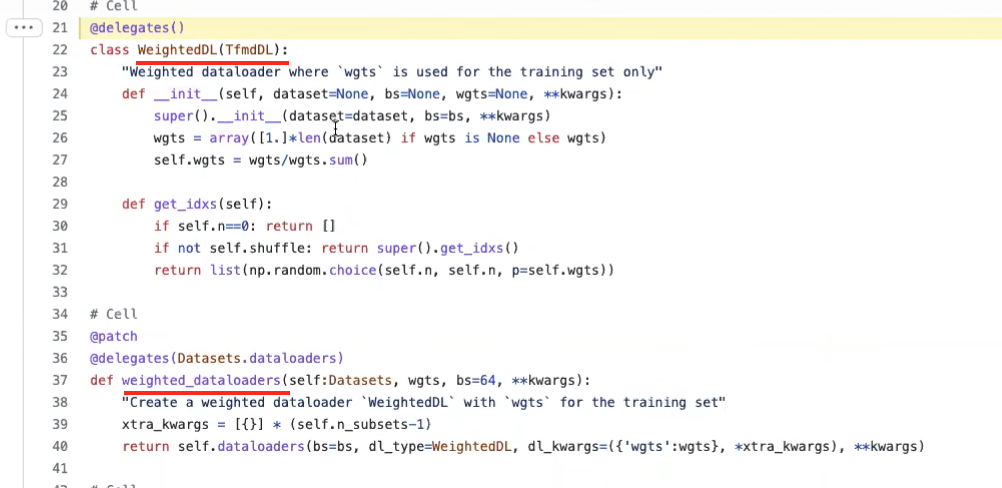
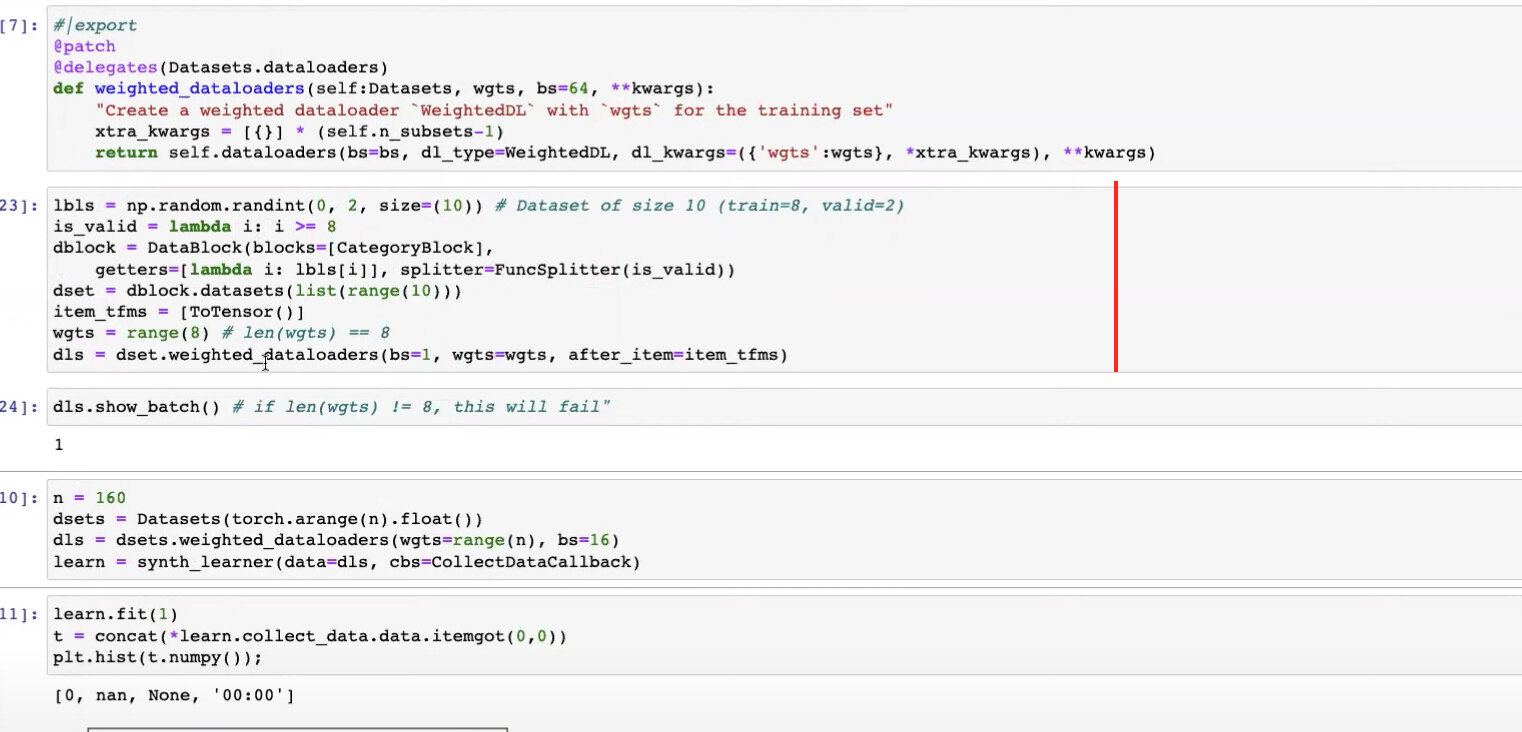
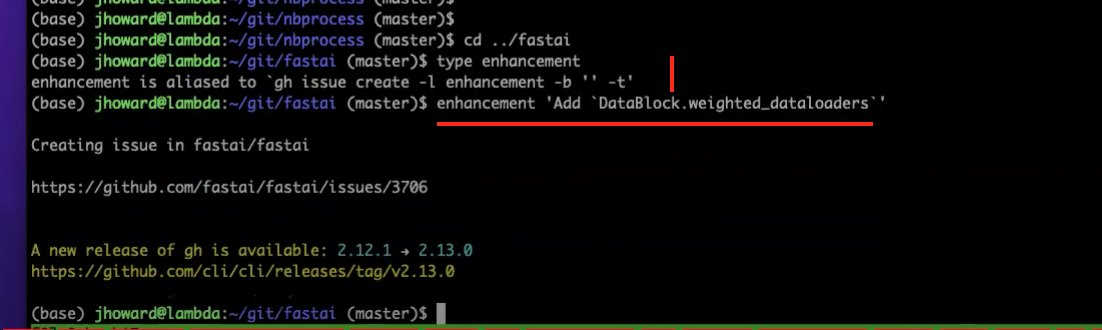
WeightedDLsource code - fastai issue created by Jeremy to add
DataBlock.weighted_dataloaders - How to Install Xrdp Server (Remote Desktop) on Ubuntu 20.04
What was covered
- Xrdp
- tmux
- Weighted data loaders
Video timeline by @mattr and @kurianbenoy
00:00 - Questions
02:00 - Running notebooks in the background from scripts
04:00 - Connecting to your server using Xrdp
07:00 - Can you connect to Paperspace machines remotely?
06:30 - Installing Xrdp
13:30 - Dealing with startup issue in Paperspace
16:20 - Native windows in tmux with tmux -CC a
18:30 - Getting mouse support working in tmux. To be able to scroll the buffer within tmux with your mouse create a config file in your home directory using touch ~/.tmux.config and then within this file include the line set -g mouse on to enable mouse support. Once saved you’ll need to close and reopen tmux to enable the new configuration. Now you will be able to use the mouse to scroll the buffer and even navigate between panes.
20:00 - Experimenting with closing notebooks while fine tuning
24:30 - Progressive resizing recap
26:00 - Building a weighted model
29:00 - Picking out the images that are difficult to classify (Lost Nick in discussion)
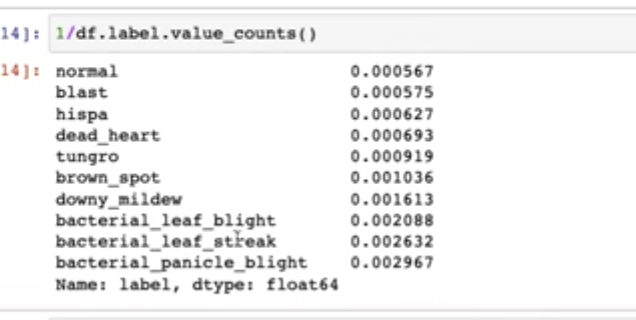
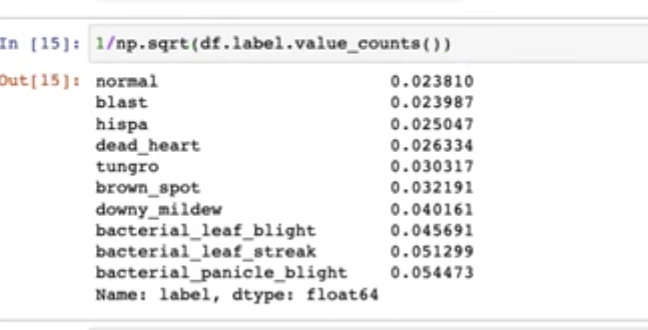
33:30 - Weighting with 1/np.sqrt(value_counts())
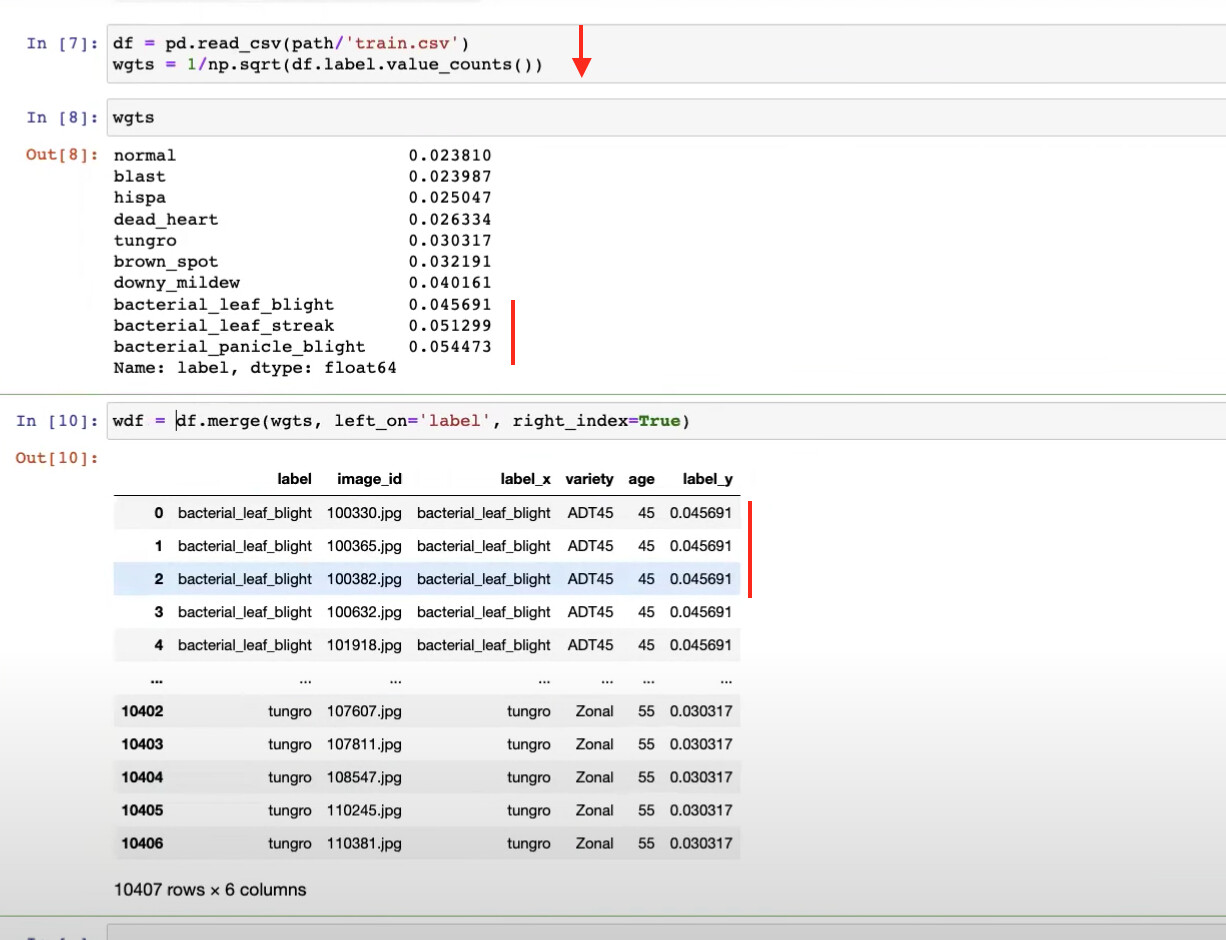
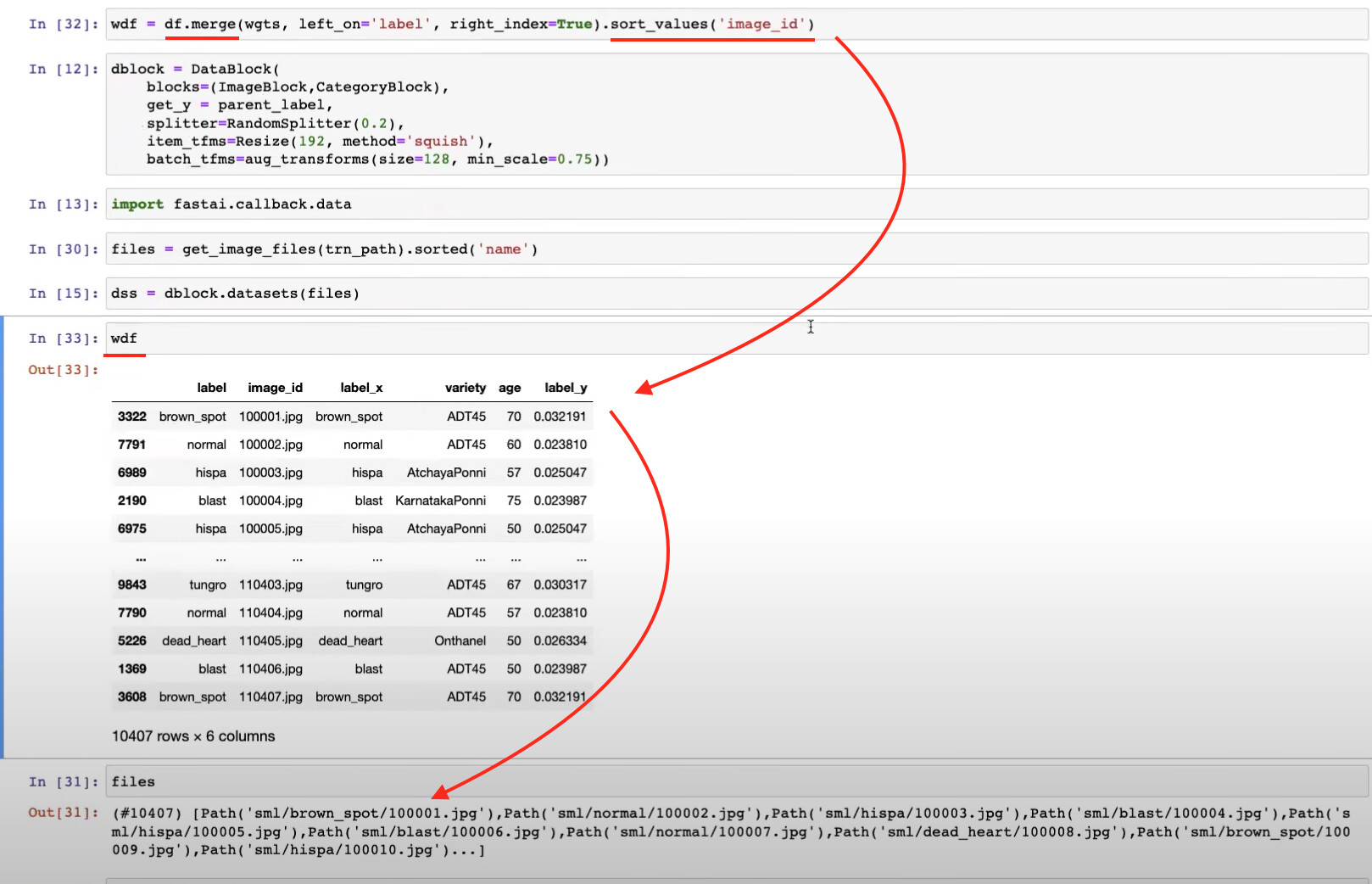
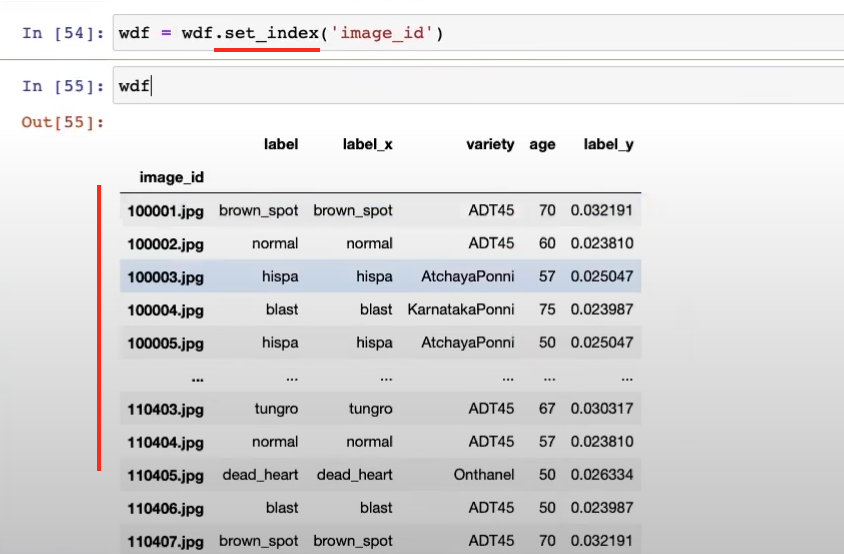
36:00 - Merging the weights with the image description dataframe
38:00 - Building a datablock
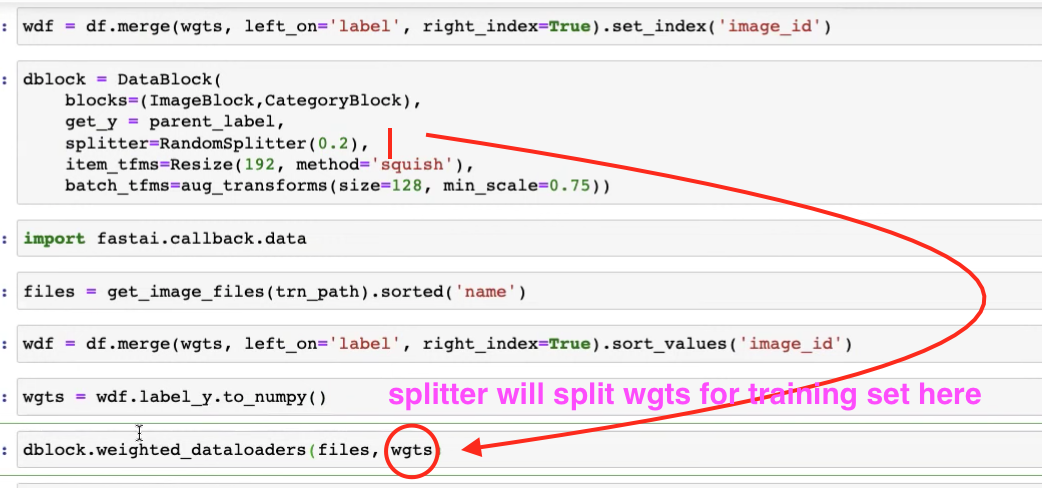
40:20 - How we want weighted dataloaders to work
41:30 - Datasets for indexing into to get an x,y pair
44:00 - Sorting list of weights and image files to match them up
47:30 - Batch transforms not applied because datasets didn’t have this method
49:00 - Reviewing errors
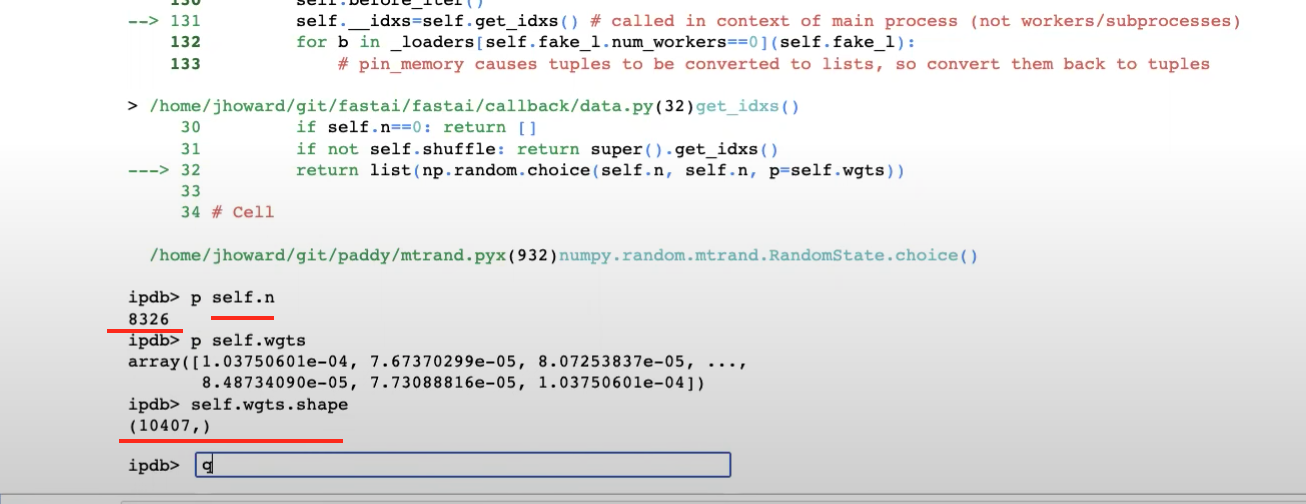
55:00 - Python debugger pdb %debug
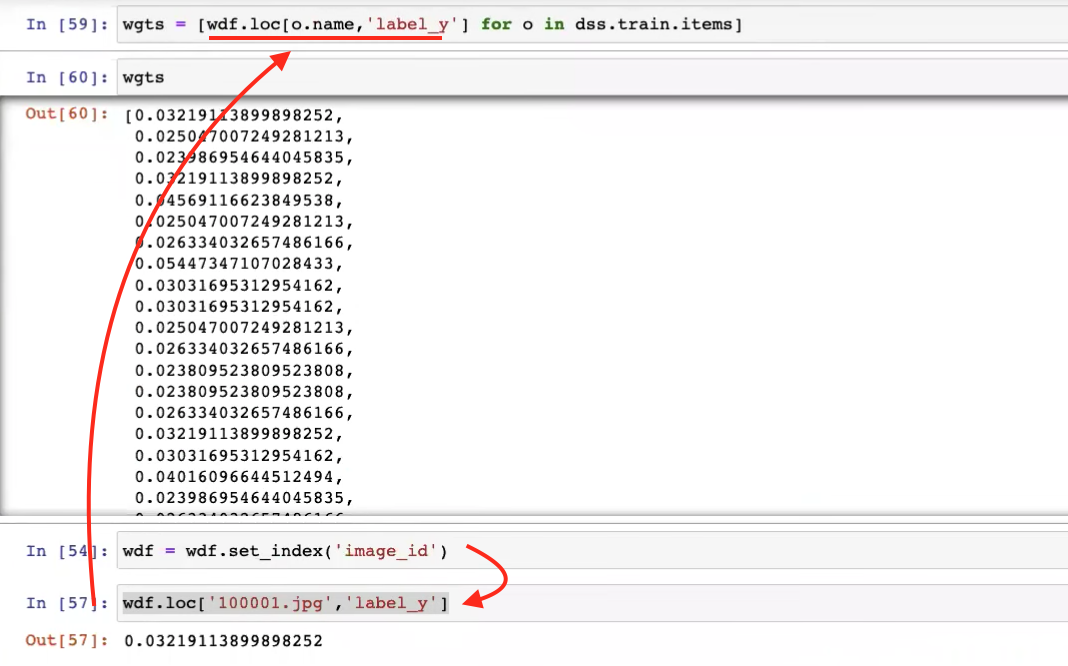
56:50 - List comprehension to assign weight to images
59:00 - Use set_index instead of sort_values
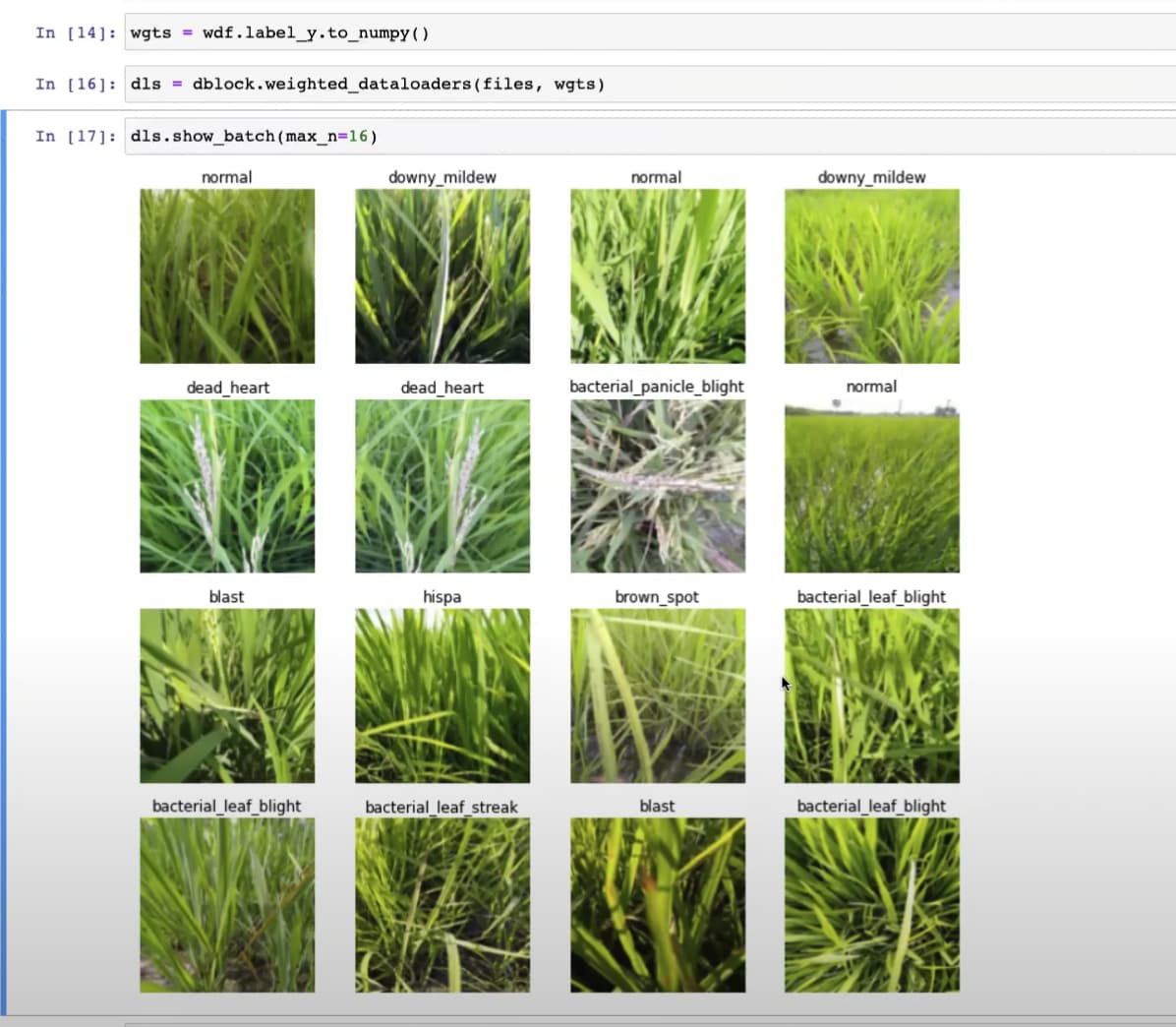
59:30 - Review weighted dataloaders with show_batch
1:00:40 - Review of how weighted sampling will work
1:03:30 - Updating the fastai library to make weighted sampling easier
1:04:47 - Is WeightedDL a callback?
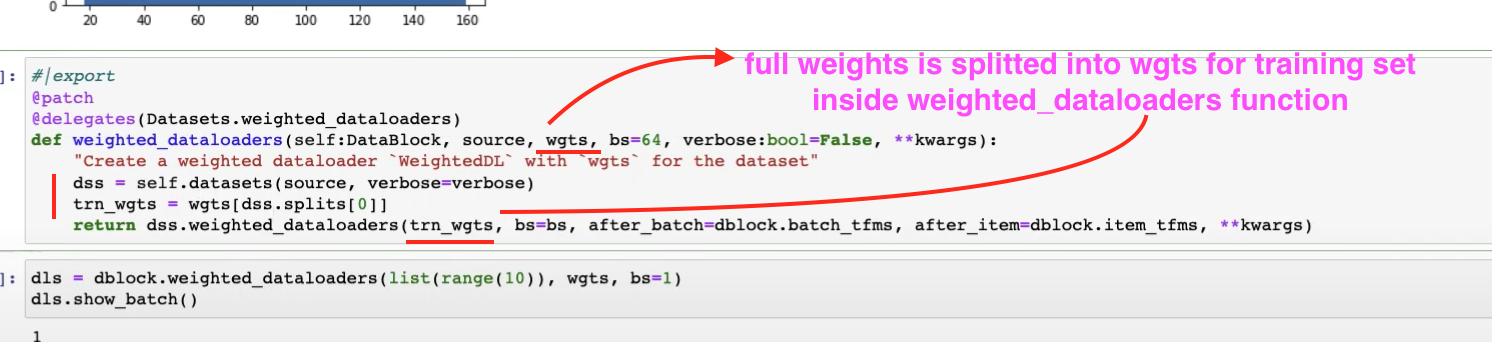
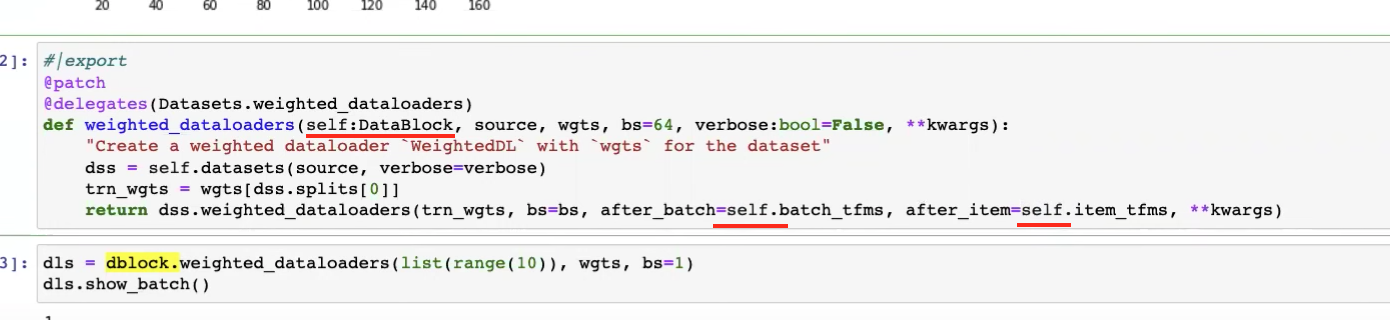
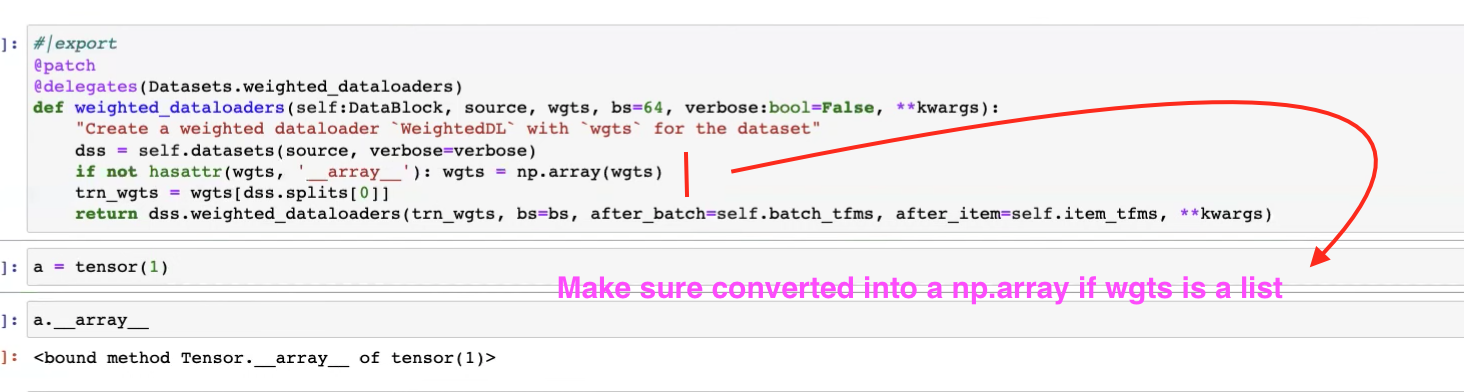
1:06:20 - modifying weighted_dataloaders function
1:10:00 - fixing tests for weighted_dataloaders
1:13:40 - editable install of pip in fastai
1:16:15 - modifying PETS notebooks to work on splitter
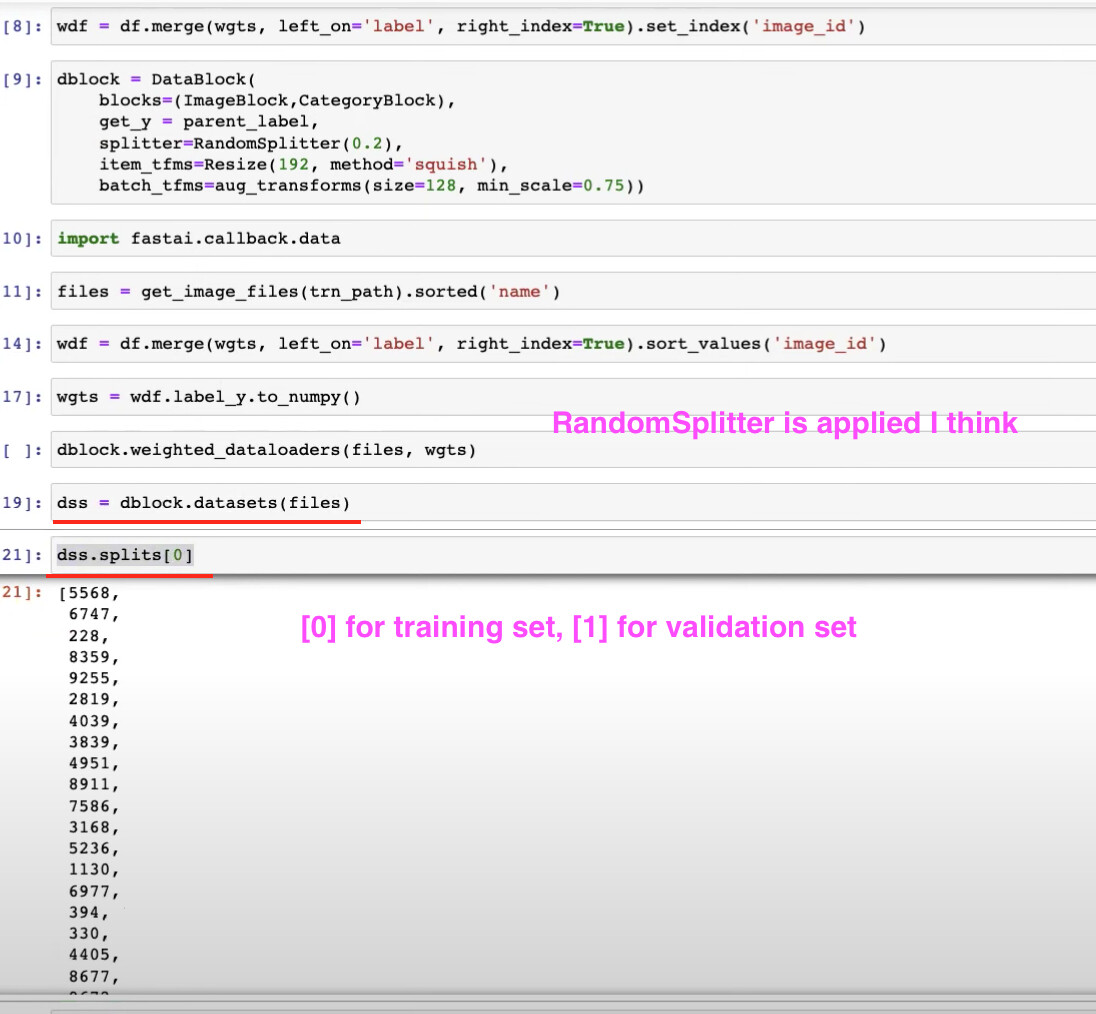
1:18:07 - How does splitters work in datablock
1:20:25 - modifying weighted dataloader by using weights from Dataset
1:23:36 - running tests in fastai and creating github issues
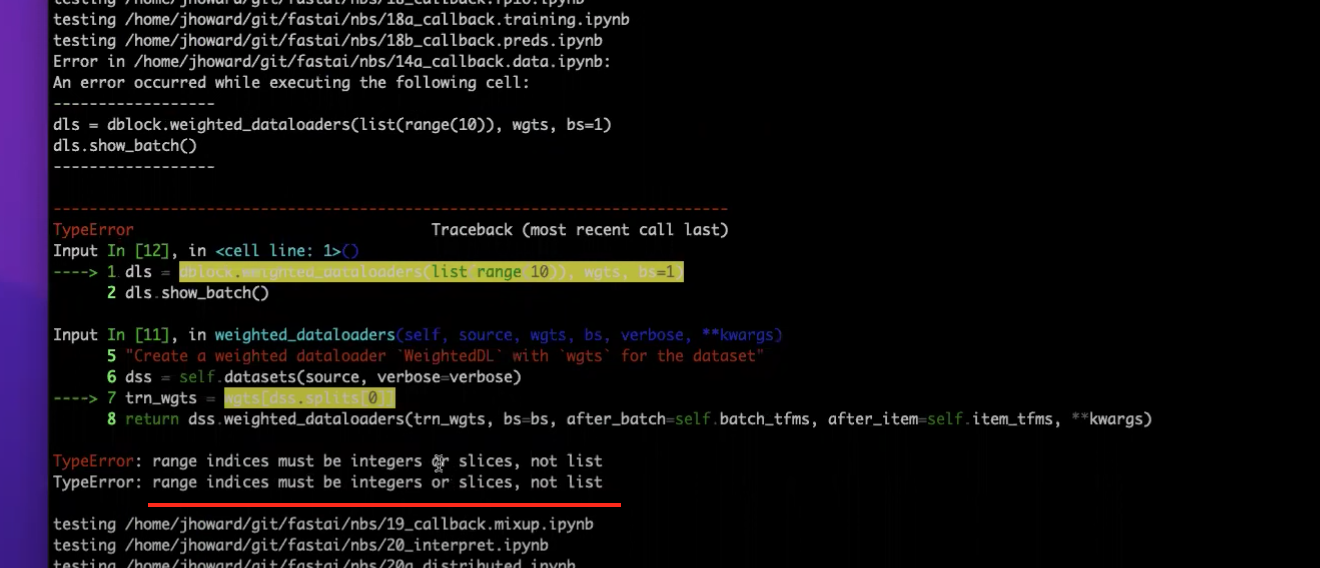
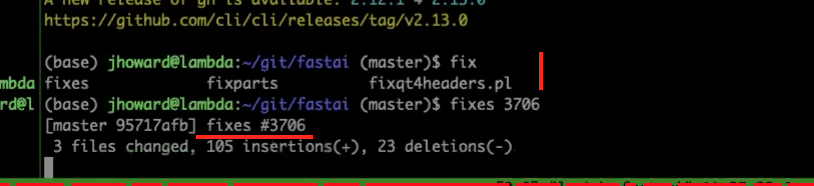
1:24:33 - fixing the failing test
1:29:40 - creating a commit to fix the issue
1:31:30 - nbdev hook to clean notebooks