Hi Jeremy, after tried to write a note on both obsidian and forum, I still would like to try the possibility to automate the replacing my note image links with forum updated image links. Please see the image below for the detailed formats of two types of links, and you can also see the unfinished note on forum
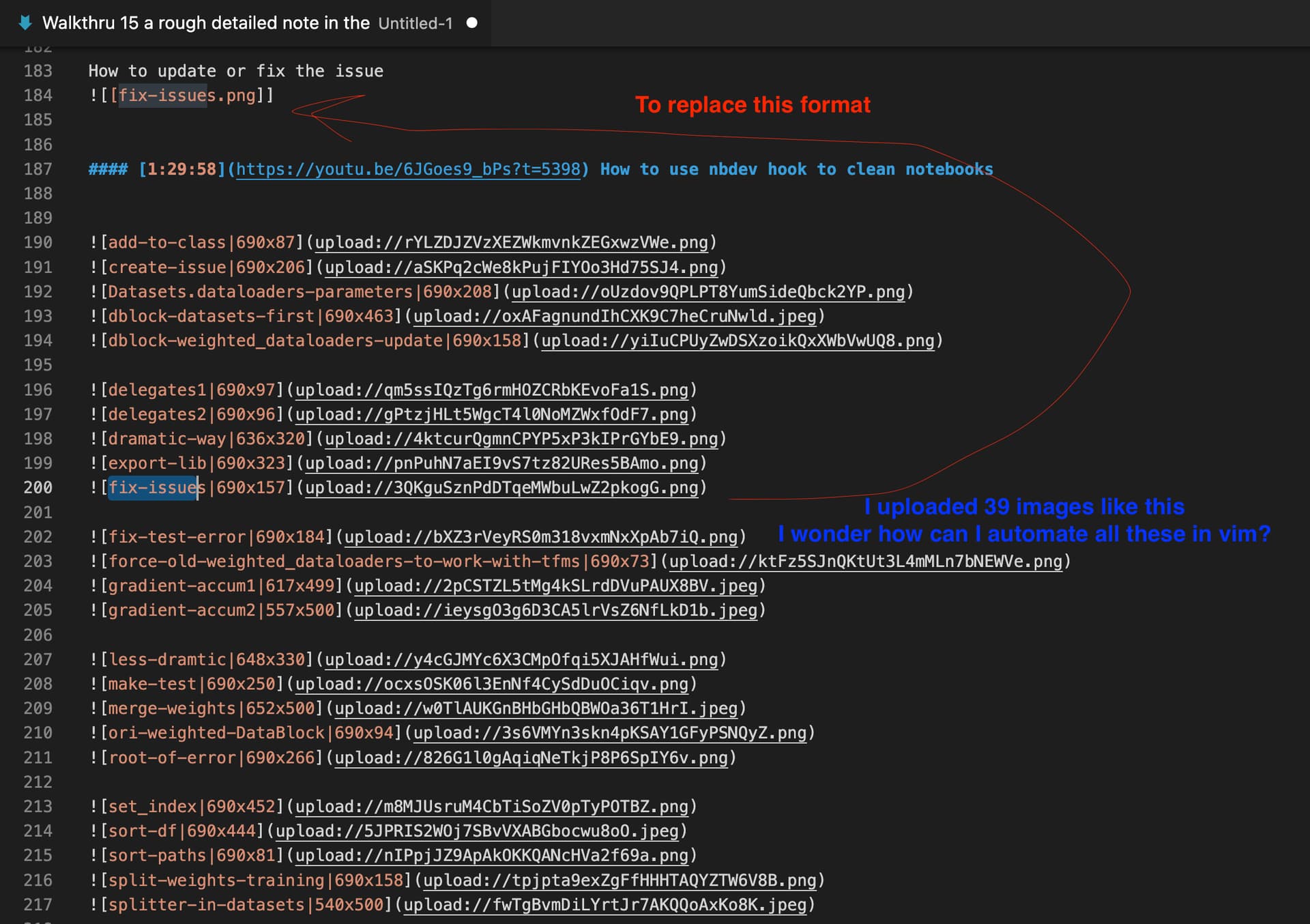
I am doing search and replace on vscode, and it sorts of takes 5-7 actions for me to replace a single image link and put them into a hide details to make them collapsible by hand. I can imagine there will be more images when I update my notes when I revisit the videos. So I think it is a good idea to be able to automate the process as much as I can.
According to previous walkthrus, I know we can use vim to do search on every line of the file for some pattern, but here I kinda need a small loop program to loop through each my forum-uploaded-image link and search for my-obsidian-image-link and replace it with the former link. Is it possible to achieve such automation with vim?
If such automation is not feasible in vim, then how can I use vim to automate the process as much as I can? Could you give me some guidance on this? Thanks