00:00 - Introduction and Questions 05:15 - MultiTask Classification Notebook 07:40 - Good fastai tutorials 08:30 - DataBlock API 12:35 - How does ImageBlock, get_image_files work 15:15 - How is aug_transforms working 17:30 - Converting ImageDataLoaders to DataBlock 22:08 - In PyTorch DataLoaders, what happens at the last batch? 23:23 - Step2: Make DataBlock spit three things 27:30 - Modifying get_y to send as two inputs 32:00 - Looking into Dataset objects 33:50 - Can we have multiple get_items? 35:20 - Hacky notebook using data frames for creating DataBlock 39:40 - How does TransformBlock and ImageBlock works 49:30 - Looking at the source code of TransformBlock, DataBlock code 54:10 - Dataset, Dataloaders discussion 58:30 - Defining DataBlock for Multi-task classification notebook 1:05:05 - Sneak peek into how the multi-task model is trained
One thing I started doing, which I have not been doing before, is I started to capture the functionality I am 100% sure I will need down the road, but I would always need to look it up.
This gets so tedious and then you just give up and don’t even do what you know could be helpful
The most annoying thing in the world:
how to use subplots (though I have this memorized now maybe)
all the seemingly one off things but that end up super useful (how to plot a confusion matrix / correlations)
But there are also fast.ai things in that list.
So I started to use gists to capture some of the that as I am figuring out stuff for the tenth time the same month.
Plus you can keep your gists private if you want to! Very useful
I’m thinking, if you are going through the course and are coming across stuff that is hard to remember, this approach probably can go a long way I have seen students do something similar. Some of us created these repositories like this one for instance essentially doing homework
But now I am hoping to extend this past the duration of the course and in a fashion more organized around reuse for other projects.
I was using a similar approach for this course, just keeping a Jupyter notebook of little snippets of code and stuff mentioned in the forums, sort of like an FAQ … but have fallen behind on it. I think the gist approach is probably better though, you can always get to it from anywhere instead of a local notebook.
Inspired by today’s amazing walk-thru, I created this kaggle kernel.
It is based on Jeremy’s kernel for the Titanic competition, but leverages the functionality (DataBlock) that we discussed today in the walk-thru
I implemented this functionality initially with just minimum fastai functionality (using datasets and dataloaders from PyTorch) and then converted it to using the DataBlock – I can’t belive how many fewer lines of code were required I think I delete like 2/3rds of the notebook
The kernel processes the data using a scikit-learn pipeline (we have not covered tabular data preprocessing with fastai just yet!) and from there on feeds it to DataBlock.
Was fun working on this And the walk-thru from today was super useful Hoping to continue practicing with the fastai framework
Maybe someone will find this useful If you would have any questions, please let me know
I’ve started using it for both this course and my real job as well. I can link it across computers for free using Google Drive, and it’s searchable and can be hyperlinked both within Obsidian and to external links. It also has labels.
I’m using it for what you are describing. I have the same problem where I am constantly looking up the same thing, and when I find it I’ve forgotten all of the fine points that I figured out a year ago. This lets me constantly update the same note with small notes or pointers to myself, rather than having it scattered all over the place. It’s a bit of a time sink because I’m always making new notes, but I tell myself that it’s part of learning. I love it. If I take nothing else away from this course, that will be something valuable that I learned about, so thanks so much for mentioning it.
I just wanted to say thank you for such an amazing walkthrough and course. I’ve fallen irreparably behind due to family and work commitments so I’m lagging a fair bit on the videos now, but I wanted to thank especially Jeremy but also everyone else for such a great educational experience.
I wanted to say it in person but since that’s not going to be possible I didn’t want the series to pass without extending my gratitude. I hope to be able to contribute more to the community as I learn more. (For now, I’m happy to play the role of newbie foil.)
Thanks @Mark_F ! Feel free to join any walkthru sessions you like regardless of how far behind you are – always happy to answer any questions you have about earlier sessions.
I had a doubt on what is behind the representation which gives the number and associated values in fast.ai library. During the last class, I noticed this in dls.vocab. Previously I have noticed this in get_image_files, yet after going a bit deep into it and how it works in a blogpost. I still don’t understand what is behind this output rendered in this specific shape of (#number of files) [Then contents in file] ?
#2 – this instance of L contains two object [first_list, second_list]
Imagine you have a model trained on images of ice cream. You would like your model to predict a) flavor of ice cream (one of vanilla, strawberry or chocolate) and serving size (small, large).
In general, a vocab is a mapping from how the model represents labels or input tokens to a representation meaningful to us.
And sorry, if I misunderstood your question, now that I read it again – yes, this is an instance of L, which provides a superset of functionality to L (and nicer rendering).
Thanks @mike.moloch and @radek for clarifying my doubt. Now I see L is the reason behind this nice rendering. I am curious to see how it really works under the hood, probably should deep dive into fastcore foundation module.
Hi all - I have been getting an error when starting a paperspace notebook using the Fastai image/runtime this weekend (6/18-19). Error is “Could not find the conda environment: fastai”.
I switched to the Pytorch runtime and the notebook and machine started up as usual but then I had to install the fastai dependencies.
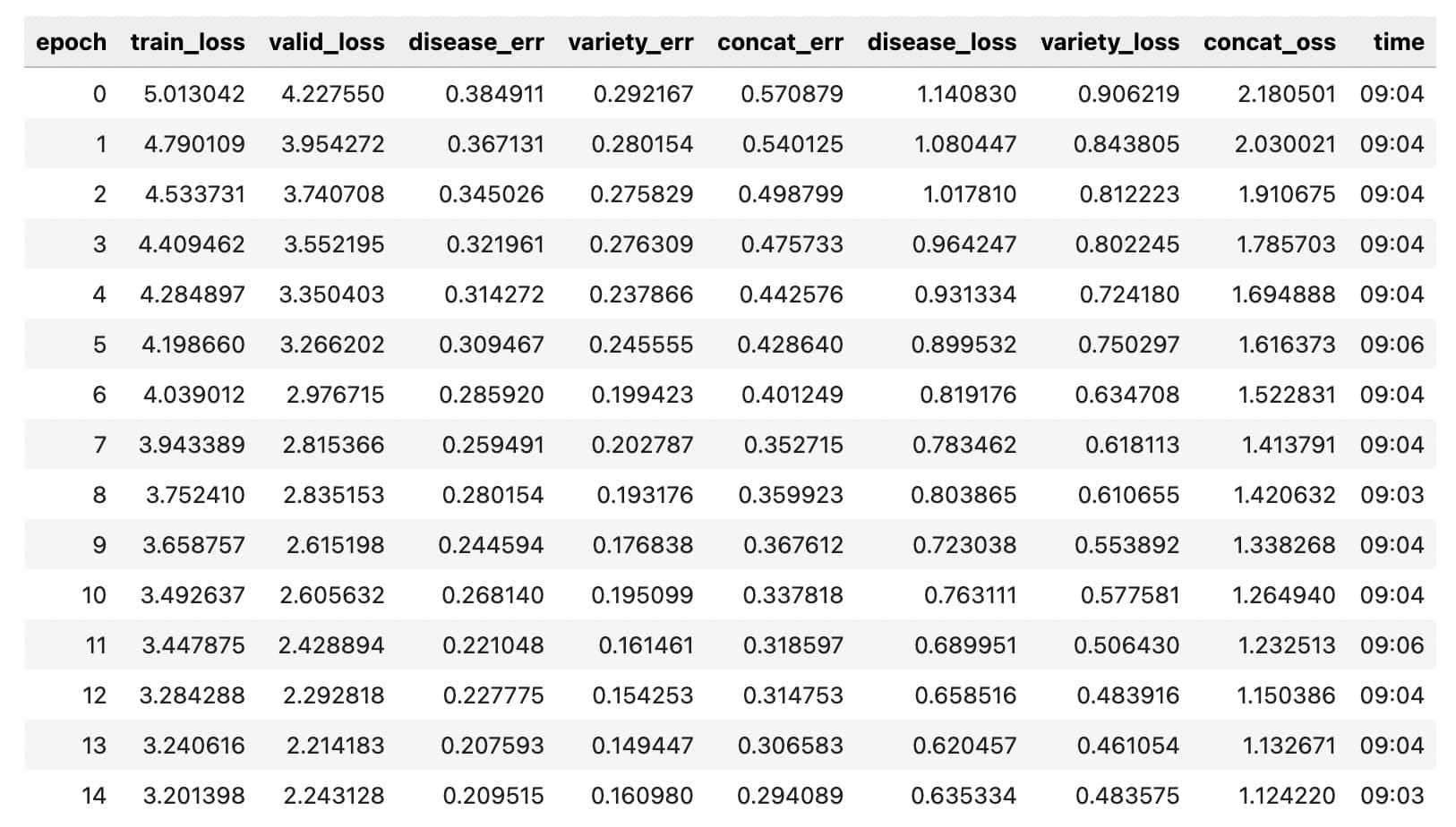
So, my experiment did not work after all Given a learning rate of 0.1 as indicated by the learning rate finder, I get the following result with the disease error plateauing at a terrible 20%
I suppose I was overengineering things and Jeremy’s more simple model should be able to pick up the interaction between disease and variety by itself anyway.
Now, another idea that came to mind was to use the variety as an input to the model rather than as an output like so: