00:00 - Review of best vision models for fine tuning 10:50 - Learn export file pth format 12:30 - Multi-head deep learning model setup 16:00 - Getting a sense of the error rate 20:00 - Looking inside the model 22:30 - Shape of the model 23:40 - Last layer at the end of the head 26:00 - Changing the last layer 29:00 - Creating a DiseaseAndTypeClassifier subclass 38:00 - Debugging the plumbing of the new subclass 46:00 - Testing the new learner 49:00 - Create a new loss function 52:00 - Getting predictions for two different targets 56:00 - Create new error function
I’m really digging these sessions. The last portion of it sort of went over my head, but I think after I watch it a second time, I’ll (hopefully) get it. It kind of gives me (a total beginner to fastai/python) a glimpse of the power that is elegantly hidden in the fastai libraries. Thank you so much for taking the time to share this knowledge with us!
I’m confused about what’s happening in the DiseaseAndTypeClassifier . I mean I know we’re changing the head to output two predictions ( ricetype and disease) but I don’t understand how the model knows that we’re changing the head?
Are self.l1 and self.l2 “special names/symbols” from some other python class/object that refer to the layers in the head part of the model? because in init we set these and then delete the last layer but I don’t see the newly created layers (“the new head”) being somehow attached to the body of the new model at the head position.
Also, I don’t understand what the ‘x’ is in forward(self,x) ?? who/what calls the forward method and what is the x that’s being passed into it?
class DiseaseAndTypeClassifier(nn.Module):
def __init__(self,m):
super().__init__()
self.l1 = nn.Linear(in_features=512, out_features=10, bias=False) #rice type
self.l2 = nn.Linear(in_features=512, out_features=10, bias=False) #disease
del(m[1][-1]) #it removes the last layer
self.m = m
def forward (self,x):
x = self.m(x)
x1 = self.l1(x)
x2 = self.l2(x)
return x1,x2
Are self.l1 and self.l2 “special names/symbols” from some other python class/object that refer to the layers in the head part of the model? because in init we set these and then delete the last layer but I don’t see the newly created layers (“the new head”) being somehow attached to the body of the new model at the head position
x is input
the model updated in the __init__ (last layer removed).
and l1 and l2 been defined but not attached yet.
in forward:
first, we pass the input through m, x = self.m(x), except the last layer.
then we attach two last layers: for rice and for disease and pass x from them separately. x1 = self.l1(x) and x2 = self.l2(x)
the points @nikem makes are correct – just adding some additional information
This type of model construction can be confusing (or at least it was for me before) – we do not need to explicitly notify the original “model” that there is a new head being used and therefore we do not need to go about attaching it.
The DiseaseAndTypeClassifier class is what can be considered our model. The new “head” layers that we want to use can be utilized by simply initializing them when we instantiate the model. So that when we call our forward pass – Pytorch keeps track of which modules were used and is able to appropriately backpropogate this information through all the applicable (used) layers. The first few paragraphs of the Autograd doc/notes do a good job of explaining this: Autograd mechanics — PyTorch 1.11.0 documentation
We are able to use this type of constructor because everything is a Module class: Module — PyTorch 1.11.0 documentation the main points are pasted here: “Base class for all neural network modules.Your models should also subclass this class. Modules can also contain other Modules, allowing to nest them in a tree structure” – So our original model was a module which was itself built from Module objects. This allows us to swap out, replace or add on top of an existing module object.
In regards to the forward method – this is something that is required for modules – we define what the desired behavior is with our input data and provide what will be returned. Module — PyTorch 1.11.0 documentation as mentioned in the docs this needs to be overriden by all subclasses.
Thanks @nikem and @ali_baba , I understand that we’re copying the model and then messing around with the last layers (aka head). I also see the model being passed into DiseaseAndTypeClassifier. I don’t see anything being passed into forward() though and I don’t see forward being called anywhere in Jeremy’s code.
So, if x is “input” to forward
what is it input of? is this the input to head ?
Is the function forward() where we’re attaching the two layers we just created in init() to the body of the model we passed into the instantiation?
Why are we passing x to self.l1 and self.l2 and what does that do?
what does self.m(x) resolve to? because we’re assigning it back to x ( x = self.m(x) )
what I’m having trouble with is that I can’t see where control passes to forward() … maybe that’s what pytorch is doing?
Sorry for these questions as they’re probably quite elementary but I don’t quite understand what’s happening here.
I just would like to reflect on two wonderful things I saw Jeremy do
Copying notebooks when trying out a new idea
This is huge to the workflow! I have often suffered in the past because I would just redo the cell with new logic, and then find out I am having a hard time going back to the previous, working state (or state where I would get a better result!).
I sometimes would be rescued by committing often, but this gets messy and is not the real solution. The real solution is to mash that copy button Which is what I have now started doing and I absolutely love it.
How to add functionality
When Jeremy started to implement something new (multi-task loss) and it was not working initially, he traced back to the simplest working state with a hint of the new functionality.
This was sooo good. This is precisely the formula for getting your ML code to run and do something interesting
Just a reminder to myself on this We often get lost in the heat of the action, but there is a methodical way of working on your code that makes a lot of sense to reach out for
And I guess it sounds simple when watching Jeremy, but it is a little bit like watching a maestro play the violin. Yeah, simple. But take a violin in your hands and things don’t go that well from start
28:38 How to create a DiseaseAndTypeClassifier class to build two linear layers for the head?
How to create the __init__ function of DiseaseAndTypeClassifier class
32:20 How to create the forward function of DiseaseAndTypeClassifier class and what does this forward do?
34:25 What amazed Radek from this line of code dtc = DiseaseAndTypeClassifier(m) class? we now actually created a new model which trains two separate linear layers (one for predicting varieties, the other for diseases) at the same time
Don’t forget the boilerplate of creating a Sequential layer using pytorch? super().__init__()
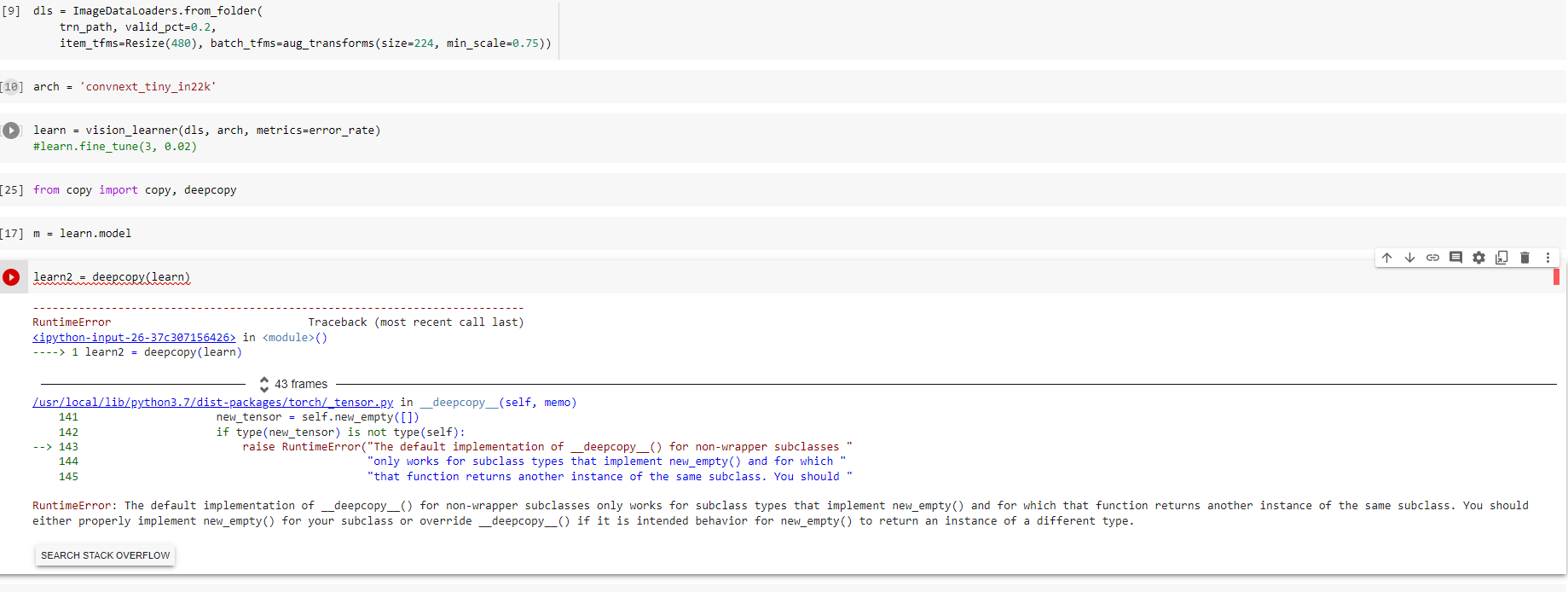
36:44 How to duplicate/copy the existing learner to make a new learner?
How to add our new model onto the newly duplicated/copied learner?
37:11 How Jeremy sort out a half-precision error when making a prediction with the new model
When things mess up without a clue, try to do restart the kernel first
#question When copy learner, maybe it is safer to use deepcopy?
42:19 How to get to the point that a copied learner (without adding the new model) can do get_preds without error?
#question Did Jeremy at this point assume that after the copied learner added our new model can still do get_preds without error? I think he assumed it at this moment since he didn’t run the code for it
43:46 How to create a DummyClassifier instead of using our DiseaseAndTypeClassifier and add it to the copied learner to see whether the new learner can still do get_preds?
This is a great demo on how to solve the problem by taking a step at a time! Very thorough and a very solid-science work style!
44:44 How to create DiseaseAndTypeClassifier to nicely build (get codes tidy and clean) the new model with two separate layers for disease and variety prediction and add this model to the copied learner and check whether get_preds works or not?
Now the error tells us we need to have loss function, assuming no other problems with running get_preds
47:10 Why we should expect an error about loss or loss func?
reminder: what is a loss function or loss?
Why we are having this tuple of tensors/losses error? because original design of loss func only return a single tensor for loss
47:53 How does Jeremy find out where the loss func of a Learner come from? or from where a loss func is get defined? so that we can design our own loss func and put it there
How to find out which loss func a model is using? use learn.loss_func
49:15 How to design the loss func for our model which output two groups of predictions?
What is the content of preds of our new model? (rice_preds, dis_preds) no longer a single 2D tensor disease_preds
How to design a new loss func (a dummy loss_func) which receives preds and targs from our new learner but only apply current loss func to only dis_preds not rice_preds?
53:54 How can we usually build a learner without specify the appropriate loss func?
Why or how does training set help specify the loss func for us?
When will we need to specify a particular loss func to replace the default loss func?
56:01 How to build a new metric (a dummy metric_func) using preds and targs from the new learner and only apply current error-rate metric to dis_preds
57:07 Let’s run lr_find() and fine_tune() with our new learner and we should expect it behaves the same as our previous learner solely on paddy disease
58:00 Not yet found previous fastai multi-loss func and in this case above we use lr_find() to pick a learning-rate more appropriate than the conservative suggestion given by lr_find
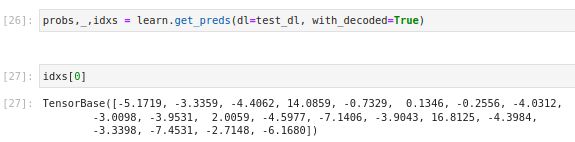
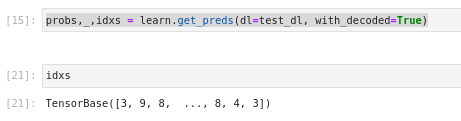
Did anyone notice learn.get_preds with multi-staged model doesn’t yield the class indexes. Check the outcome below:
In contrary to what a normal model would yield:
Is this is how it should be? It would be easier if get_preds would have returned the class indexes. Do we have to apply argmax ourselves on the output of multi-stage model?
When we use our own loss functions etc we need to handle more stuff ourselves. There isn’t a general way that fastai can know what your custom functions are doing.
Thanks Jeremy. It makes sense as there might be numerous possibilities to do different things with the output based on the use case.
The idxs vector isn’t probabilities as few values are minus, I applied softmax() followed by argmax():
idxs[:,0:n0].softmax(dim=1).argmax(dim=1)
Hopefully this is the right approach. The cool thing with walkthroughs and course is that it is allowing to learn much finer details of fast.ai library specifically and DL in general to create my own things. Thanks.
I’m finally catching up with all of these videos and ran into something strange during this one. Nobody else having a similar problem makes me nervous that I am missing something super obvious, but I thought I’d post it here in case someone runs into a similar issue.
At 18:35 there is a discussion about how things that work well on small models tend to work well also on larger models (e.g. of the same family). Are language models exception to that? It seems like there are these emergent capabilities that tend to happen only on huge billion-parameters models…