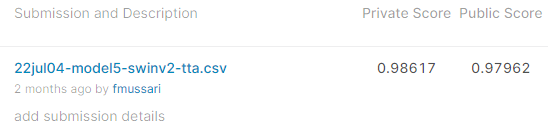
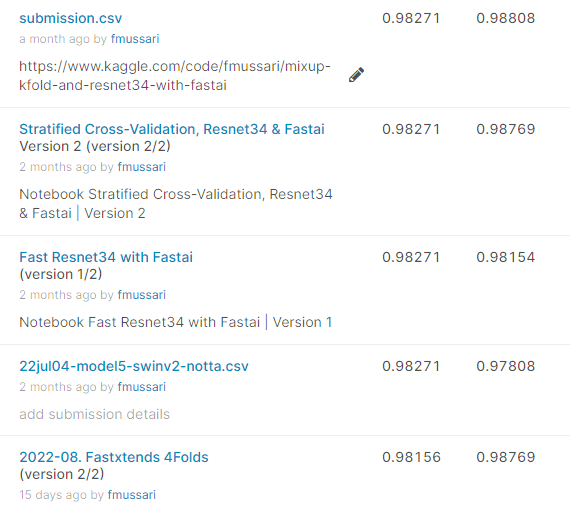
I wanted to compile videos, notebooks and information about the Paddy Doctor Community Competition.
Please add any comments or what you think is missing.
And would be great if you share your experience and things you have tried.
How it started
The Kaggle community competition Paddy Doctor: Paddy Disease Classification was introduced to many of us through this forum post: Practice walk-thru 6 / chp1 on Kaggle!. There @radek put together a repository and instructions on how to submit to Kaggle from Paperspace and a list of questions and things to try on that dataset.
In the same post Jeremy replied: “Might be fun to look at this tomorrow…”
How it became part of the fastai way of learning
Next day in Live coding 7 session, Jeremy asked: “ok, Radek, you want to tell us about what this thing is?”. “This is the fastai way of learning”, he replied before start explaining his post.
From that point the competition became an increasingly important part of the course and live coding sessions. And (I think that) many of us learned the fastai way by trying that competition with our own hands.
The road to the top
In the live coding sessions Jeremy showed us how to explore and solve many things. From setting up and automating the creation of a work environment, to techniques as progressive resizing. Without being sure of what I was doing, we were looking inside a model, digging fast.ai code base, tutorials and documentation, creating custom loss functions… Jeremy shared with us fastkaggle for automating Kaggle stuff.
Most of what was covered was translated into these 5 notebooks:
Kaggle Notebooks shared by Jeremy during the Lessons and Live Code Sessions
- The best vision models for fine-tuning
- First Steps: Road to the Top, Part 1
- Small models: Road to the Top, Part 2
- Scaling Up: Road to the Top, Part 3
- Multi-target: Road to the Top, Part 4
Part 3 notebook got Jeremy to the top of the leaderboard, but not for too long.
Students passing to the top of the leaderboard
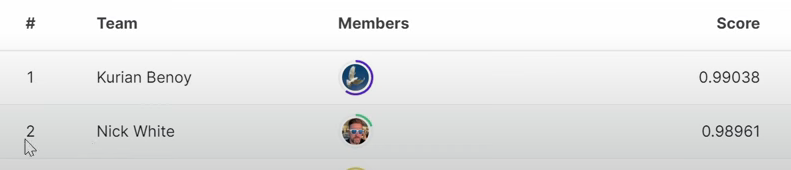
At some moment two students passed Jeremy in the leaderboard.
@kurian posted this topic Tips on how to improve your accuracy on Kaggle discussions.
Some days after another person who reached the top posted Thanks Fast AI!
How is Paddy Doctor Kaggle Competition Going?
This community competition ends in a month.
Competitions are great to learn data science but I suppose I’m not alone in the experience that in the first few competitions you are perhaps only learning to compete. To create the bases of code and understanding for experimenting a little more in the i(th) competition. Whichever your iteration is, you can start now with Jeremy’s Kaggle Notebooks. They are a synthesis of the video lessons and live coding sessions.
There are lots of fast.ai students in the leaderboard.
I hope there are going to be wonderful notebooks and discussions about techniques and approaches at the end of the competition.
References
Lessons with mentions about Paddy Competition
- Lesson 6: Practical Deep Learning for Coders 2022 | Official topic | Recording
- Lesson 7: Practical Deep Learning for Coders 2022 | Official topic | Recording
Live coding sessions with mentions about Paddy Competition
- Live coding 7 | Topic | Recording
- Live coding 8 | Topic | Recording
- Live coding 9 | Topic | Recording
- Live coding 10 | Topic | Recording
- Live coding 11 | Topic | Recording
- Live coding 12 | Topic | Recording
- Live coding 13 | Topic | Recording
- Live coding 14 | Topic | Recording
- Live coding 15 | Topic | Recording
- Live coding 16 | Topic | Recording
Intermediate/Advanced things to try (or to get familiar with)
I haven’t tried much of the techniques and tricks referenced here (yet). But trying to understand how some of them works makes you think about the internals of the model, the functions involved, the fitting process. I personally ended tweaking the Excel/Sheets files again simulating “target encoding” “label smoothing”.
Some of these resources come from @kurian topic Tips on how to improve your accuracy.
- Fast.ai Book Chapter 7: Sizing and TTA
- Recording: Lesson 12 (2019) - Advanced training techniques; ULMFiT from scratch
- wandb: Revisiting ResNets: Improved Training and Scaling Strategies
- arxiv: Bag of Tricks for Image Classification with Convolutional Neural Networks
- arxiv: Revisiting ResNets: Improved Training and Scaling Strategies
- Fastxtend Docs