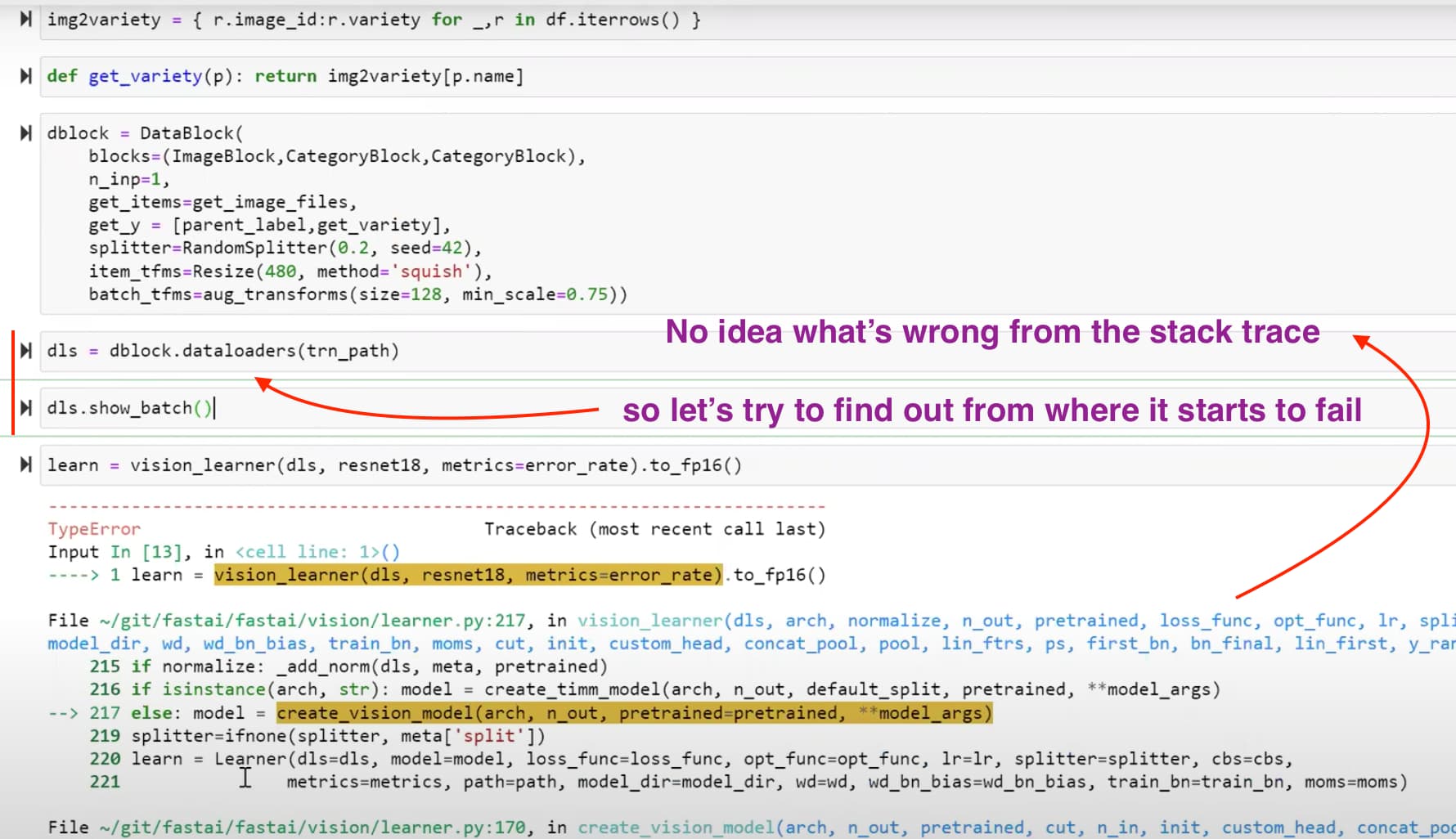
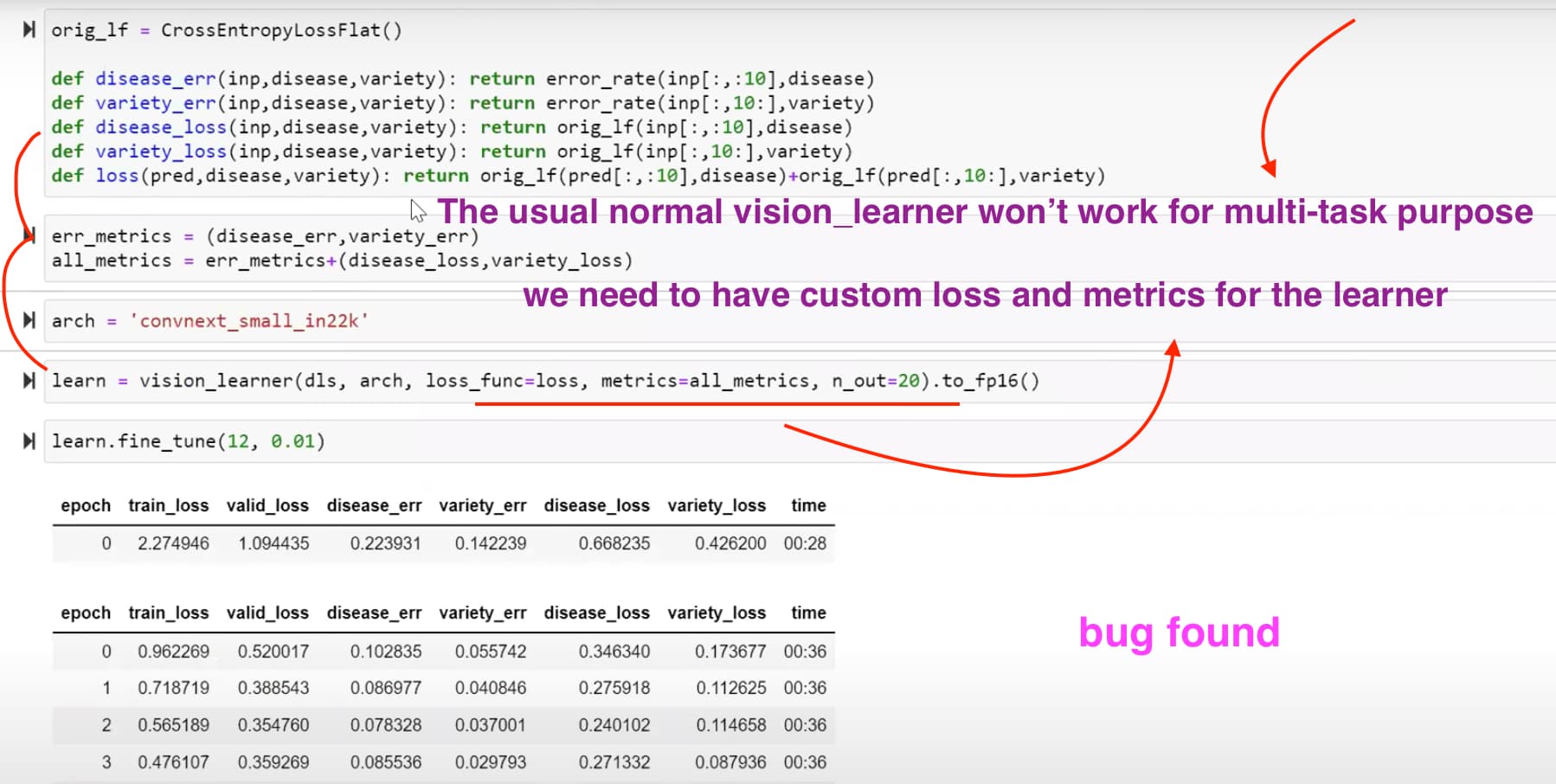
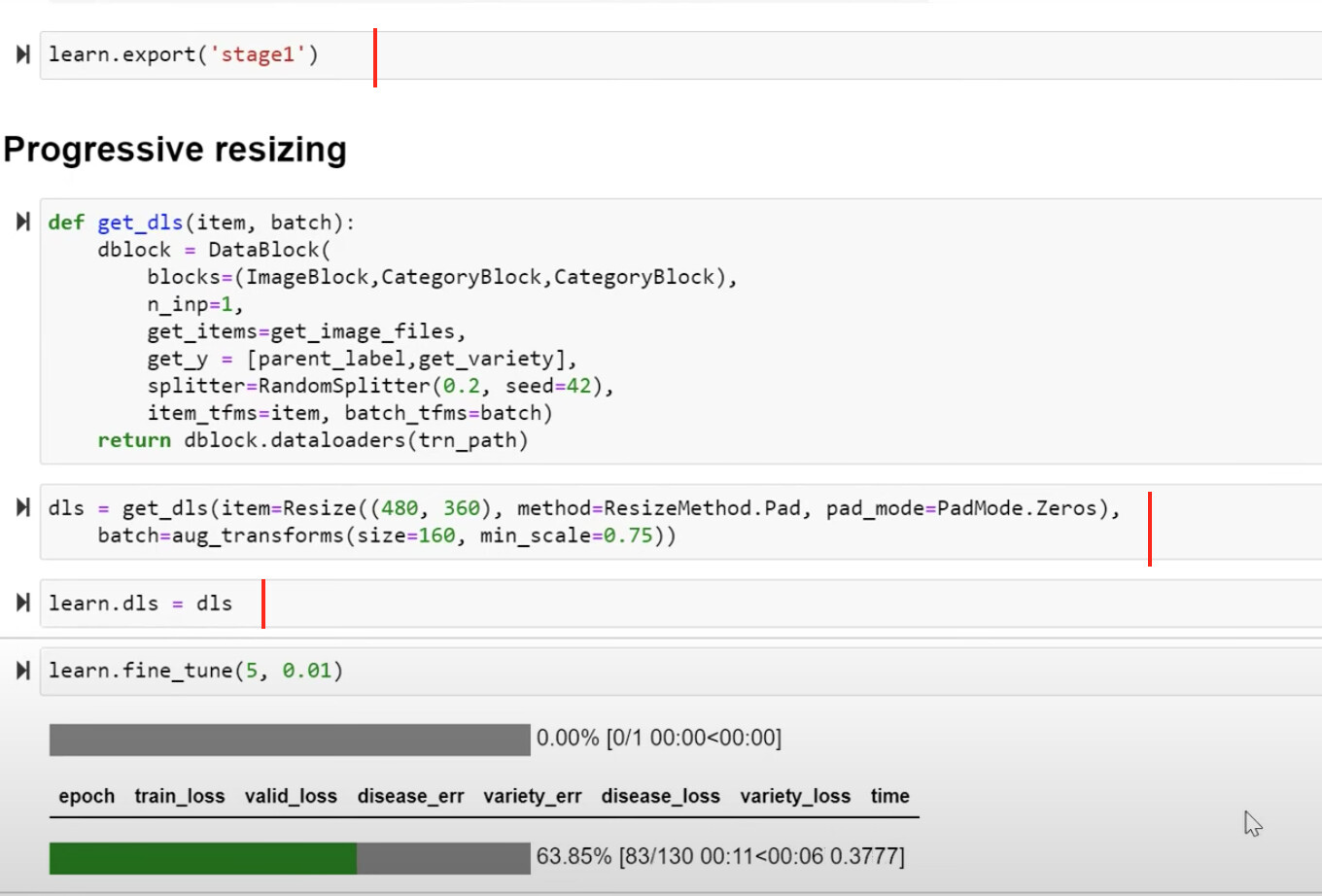
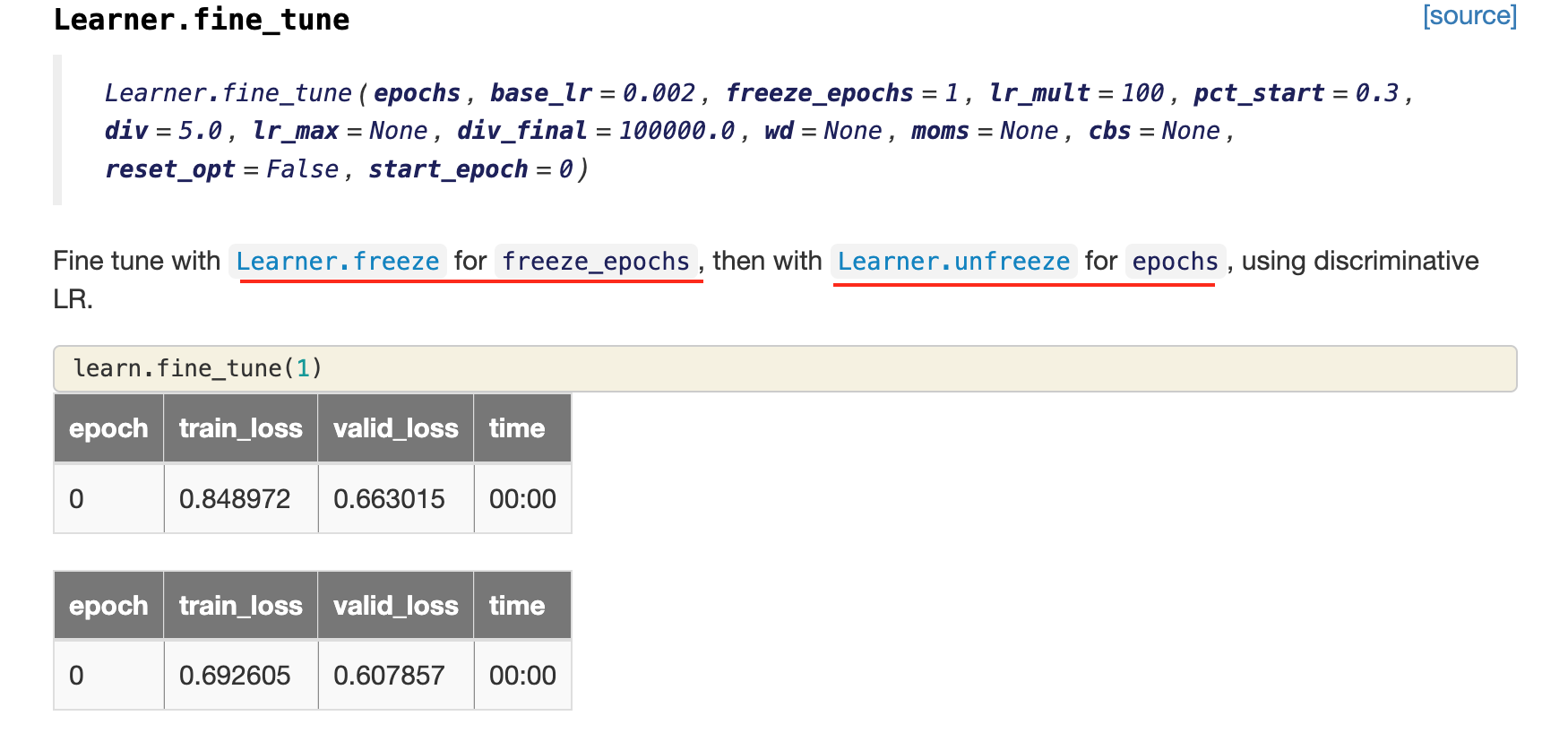
00:00 - Questions 00:05 - About the concept/capability of early stoppings 04:00 - Different models, which one to use 05:25 - Gradient Boosting Machine with different model predictions 07:25 - AutoML tools 07:50 - Kaggle winners approaches, ensemble 09:00 - Test Time Augmentation (TTA): why does it improve the score? 11:00 - Training loss vs validation loss 12:30 - Averaging a few augmented versions 13:50 - Unbalanced dataset and augmentation 15:00 - On balancing datasets 15:40 - WeightedDL, Weighted DataLoader 17:55 - Weighted sampling on Diabetic Retinopathy competition 19:40 - Lets try something… 21:40 - Setting an environment variable when having multiple GPUs 21:55 - Multi target model 23:00 - Debugging 27:04 - Revise transforms to 128x128 and 5 epochs. Fine tune base case. 28:00 - Progressive resizing 29:16 - Fine tuning again but on larger 160x160 images 34:30 - Oops, small bug, restart (without creating a new learner) 37:30 - Re-run second fine-tuning 40:00 - How did you come up with the idea of progressive resizing? 41:00 - Changing things during training 42:30 - On the paper Fixing the train-test resolution discrepancy 44:15 - Fine tuning again but on larger 192x192 images 46:11 - A detour about paper reference management 48:27 - Final fine-tuning 256x192 49:30 - Looking at WeightedDL, WeightedDataLoader 57:08 - Back to the results of fine-tuning 256x192 58:20 - Question leading to look at callbacks 59:18 - About SaveModelCallback 01:00:56 - Contributing, Documentation, and looking at “Docments” 01:03:50 - Final questions: lr_find() 01:04:50 - Final questions: Training for longer, decreasing validation loss, epochs, error rate 01:06:15 - Final questions: Progressive resizing and reinitialization 01:08:00 - Final questions: Resolution independent models, trick to make TIMM resolution independent by changing positional encodings
The aim of this was a quick validation that it was worth the effort of looking into further, and verifying that it does indeed provide better test results. The setup is extremely straightforward:
Dataset: URLs.IMAGEWOOF
Model: resnet18, not pretrained
Batch Size: 64
Metrics: accuracy
I then fit for 5 epochs and took that validation. It wound up being 18.09%. This serves as my baseline.
From there I changed the augmentation size of the final Resize transform (see snippet in the notebook for the caveat of doing so).
Jeremy if we want to do something like this to make progressive resize easier perhaps how the Pipeline's are created should make a deepcopy of each transform? (See nb for what I mean)
Actually, this is the perfect way to increase the progressive resize shape/size since it adjusts both train and val
For my test I changed the final resolution to 448 rather than 320x320, as this is typically what I’d perform for progressive resizing (2x the image size).
This new upscale got 18.6%! Which is an improvement! Phenomenal.
But, the final test was whether it was worth doing fit_one_cycle one last time for a single epoch. And the results might (or might not surprise you).
This final accuracy at the upscaled size was 19.11%, beating our only-upscale-on-inference by almost 2x when comparing it against our benchmark.
So, is it worth doing? I’m not entirely sure. Where someone could pick this up is trying to see what happens if you mimic Kaggle. E.g. We have a train/val/hidden test set, and performing inference on that hidden test set at the very end and comparing the three options performed here again.
It could be worth it if you don’t have a few spare minutes on your GPU quota, but otherwise wasn’t too too impressed with the results
This is also of course an n of 1, but the difference wasn’t high enough for me to think about trying across 5 runs and averaging, etc
(I of course invite all criticism and please try this yourself too! It’s a fun little exercise )
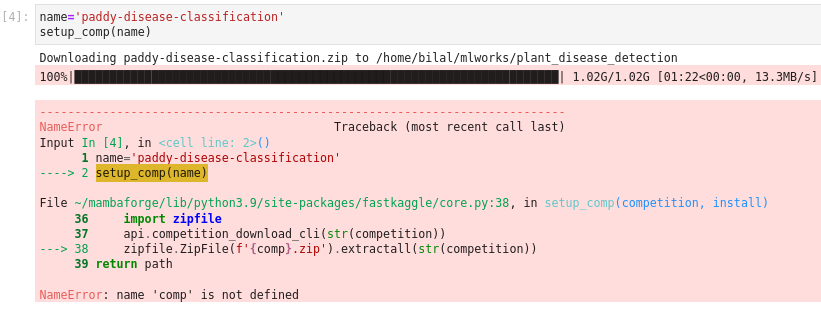
Just discovered a tiny bug in the fastkaggle library. I’m sure it is not a big deal. The setup_comp raises error if you use a different variable for holding the competition name than comp. See the following error:
@zach the accuracy in your baseline (18%) is much lower than what I’ve got executing your code on colab (44%). Could you share what version of fastai you are using?
Here is how the notebook looks like after execution on colab:
The version on my instance is 2.6.3. As you can see in the gist the change to 448px crop size at test time drops the accuracy from 45% to 39%. Fitting one cycle gives an accuracy of 30%. So, the claim from the paper is not replicated in my instance of env.
But even if it were, we might have a few more issues:
TTA seems to fix the issue brought in the paper as the pipeline is the same then.
They seem to assume that the apparent pixel sizes of objects don’t vary much in the test set. This may be true for imagenet, but I doubt it is always the case. They make this assumption; otherwise, training a model to recognize objects in more pixel sizes should improve the generalization and test accuracy (as these sets do not have to have the same distributions).
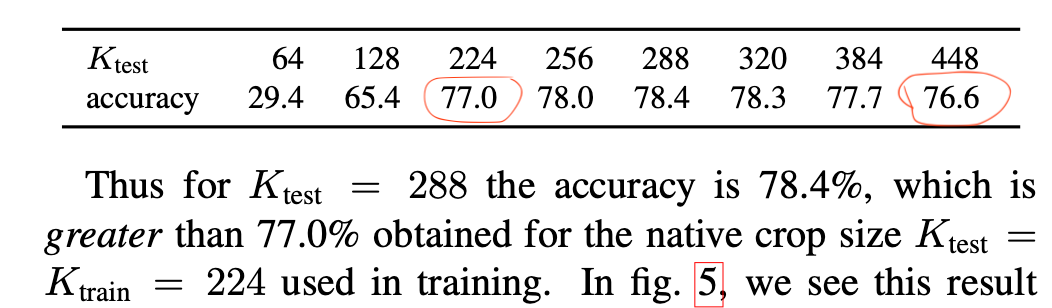
They observe improvement when scaling test size to 1.3x of train size (from 224px to 288px), at 2x scale (448px) the performance drops again. The notebook uses the 2x scale.
Training for the 5th epoch on a larger crop might make the model learn more no matter the crop, as the model did not plateau. So we can’t claim 1 more epoch is better without trying to control that.
But the paper is quite interesting thank you for putting that together I will try to play with it more.
No problem! thanks for noting the performance drop, which aligns with your behavior. There may have been some lag in some degree or some weird bug with the states that caused the notebook to get weird results (an issue on me, oops), don’t have the time to get around to test it today but will trust what you say and that my analysis is flawed!
Following up on the issues above. Training for longer (20 epochs) gives us a better model where we can observe the improvement in performance when changing to 288. (Fitting one epoch degraded the performance as the LR was too large.)
After lowering the LR and fitting for 5 more epochs on 224px we get better performance than previously after changing 288, switching that model to 288 gives again better performance.
TTA with 224 is 4x slower but gives almost the same performance than switching to 288px
TTA with 288 gives the best performance I’ve seen.
Here is the colab notebook with results:
This was briefly touched on towards the end of the previous walk-thru (13): Walkthru 13 - YouTube (~65 min mark)
Not sure if you are looking for more information on them or the difference between the two (error & loss functions)? If so, it was covered in lesson 4: Practical Deep Learning for Coders Lesson 4 - YouTube (~59 min mark)
Sometimes it is not easy to understand that you need a custom error/loss function. At least for me. I need to be familiar with checking the source code. Thanks Ali.
I’ve tested the paper assumption on pre-trained models, if the model in most of the exp. it gives 10% - 15% improvement. But when a model is pretty good already it can be determinetal, so my guess is that if we get a more capable model the trick won’t help. Here is a summary of the results in excel. So I’m not sure It make sense to implement the full paper.
hint: 1. why use large images to train weights when small images can do; 2. inspriation from changing learning rate during training, why not image size
42:34 Potential comparison experiment: which one is better, models training on 224 and predicting on 360 vs models training first on 360, then on 224, and finally predicting on 360
1:04:49 What would happen and what to do if you want to keep training after 12 epochs?
If the error-rate gets better but validation loss worse, is it overfitting?
no, it is just overconfident
What would happen to your learning rate if you continue to train with fit_one_cycle or fine_tune?
hint: learning rate up and down in cycles, so reduce learning rate by 4-5 times to keep training
What would Jeremy do to learning rate when he re-run the code above?
hint: halve lr each time/model
1:06:16 Does any layer of the model get reinitialized when doing progressive resizing due to different image sizes? No
Is convnext model resolution independent? what does it mean?
it means the model works for any image input resolution
Why convnext model can be resolution independent? 1:07:21
hint: it’s just a matter of more or less matrix patches
1:07:49 Is there a trick we can turn resolution dependent models resolution independent with timm? Interesting to see whether this trick can also work with progressive resizing
1:08:58 Why Jeremy does not train models on the entire training set (without splitting data to validation set)? and what does Jeremy do about it?