That doesn’t sound right - generally LRs are 0.01 or lower.
4 Likes
I am a little confused about the second notebook that Jeremy posted on Kaggle. In the scaling up section, for the item tfms he used Resize((480, 360), method=ResizeMethod.Pad, pad_mode=PadMode.Zeros). I am a little confused here. The original image is 640, 480. So should we not either squish or crop? Can we use padding even when we are reducing the size in transformation?
Check out the fast.ai docs on resize methods, and see what you find out – then come back here and let us know! Be sure to experiment with running the code in the docs yourself of course… ![]()
And if you still have questions after that, let us know and we’ll help as best as we can.
2 Likes
Could you add this one to the YT playlist? Thanks!
2 Likes
A question regarding the shape of the images shown in this walkthru. This shape is (640 x 480 x 3). Shouldn’t the number of channels (3) be the first index instead of the last? I thought an RGB image is 3 blocks of matrices, each of size, say 640 x 480 (in this example). To me, it looks like there are 640 matrices with 480 rows and 3 columns… I hope I’m not confusing anything here.
Thanks, Jeremy. I looked in the docs and source code. After playing around with it I have a better understanding now. It seems like if the ratio of height to width in the transformed image is exactly the same as that in the original image then all the three methods give very similar results (images on the left in the figure below). Bigger sizes mean better resolution. When the ratio is different then we can see the difference between these methods. In the figure below, I have taken exact same images for all cases.

2 Likes
Is the AGT segment supposed to be in the playlist? ![]()
It can be either. Different libs/frameworks use different approaches as to whether channels are last or fast. PyTorch and fastai can support either ((beta) Channels Last Memory Format in PyTorch — PyTorch Tutorials 2.4.0+cu121 documentation).
1 Like
I saved it for my daughter - was meant to be in “watch later” but youtube mobile defaults to the walkthru playlist!
1 Like
Excellent analysis! ![]()
1 Like
Renaming the file worked, I was able to startup the machine. I wonder what the issue was? Thanks.
That’s a wonderful explanation. Thank you. Just to be sure though - under the hood, when these matrices are being multiplied, we do change it back to the shape: (batch size, num of channels, H, W) once it’s fed to the model or we shouldn’t worry about such things?
Understood. The thing that worried me is what shape the model is expecting to get (for example, ResNet that we’ve been using initially). But from what I understand, in ResNet’s implementation, they will change the shape of the input tensor so that the channel would be recognized. Thanks, Jeremy!
walkthru 13 rough note
if you do read it and please correct me if anything not right and you are very welcome to ask any questions about the note)
00:00 - Introduction and Questions
01:12 Why the previous approach of building a model with 2 separate final layers (2 heads) is confusing to some?
02:01 Fastai Unconference with part 2 of the course is possible later in 2022
03:27 Fastai walkthru is going on happily forever, Yeah!
05:13 Spoil alert! multi-task (2 separate final layers) didn’t help the score but Jeremy is very happy about what he found out along the way
06:06 First, let’s create a DataLoader in which each image has two labels (disease and type/variety)
06:43 Why we can’t just use ImageDataLoaders for the two labels feature? What shall we do about it?
07:22 How did Jeremy find out how to create such a DataLoader with the help of docs.fast.ai?
How does Jeremy think of docs.fast.ai as a customer?
08:33 How to replicate what we did with ImageDataLoaders.from_folder using DataBlock
Where to learn more of DataBlock? The fastbook and tutorials on docs of fastai
Set up blocks of inputs and labels using ImageBlock and CategoryBlock
get_y can get us label of each image by using a labeling function called parent_label
splitter, item_tfms, batch_tfms can just copy from previous Paddy notebook
10:03 How to create a DataLoaders from DataBlock?
What is source of dblock.dataloaders()?
source is anything you can iterate into or index into in order to grab things and give them to functions prepared in DataBlock.
so, source can be a path like trn_path
How does get_items=get_image_files of DataBlock work?
Once source=trn_path is set in dblock.dataloaders(), the path is given to get_image_files to get all the image items
Now, we can use dls.show_batch() to see whether we have a working dls based on pure DataBlock
11:06 What does ImageBlock and CategoryBlock do?
we can learn about them by reading from source code.
ImageBlock is to apply PILImage.create() and IntToFloatTensor to images
12:46 What exactly is applied to PILImage.create() as well as to ImageBlock?
through PILImage.create?? source code, we will find out it can be a path, string, tensor, array or event bytes
13:16 How does get_items=get_image_files and ImageBlock or more specifically PILImage.create work together?
All image items are specified in a list of path which is output of get_image_files(trn_path),
and each item path will be given to PILImage.create to create, store (in format of bytes) and display the image
then when a batch of images is collected, they will be transformed by IntToFloatTensor
15:21 , Explore docs to understand the image transforms applied to single images first and then to batch of images through item_tfms=Resize(), and batch_tfms=aug_transforms()
17:38 After constructed the DataLoaderwhich can performImageDataLoader.from_folder, What did Jeremy do to achieve super fast iteration for testing the dataloader all the way to training?
use the small image size for augmentation, 128 not 224
use a small and fast model without requirement for image size, such as resnet18
use learn.fit_one_cycle(1, 0.01) to train one epoch in 20 seconds
and check the error rate for a reasonable performance
19:41
20:33 Does training for 1 epoch mean your model will guarantee to see all the images/data items once? yes
dblock.dataloaders() will by default 80% of the datasets will be shuffled and put 64 items into a batch
every item in the training set is guaranteed to meet the learner through fit_one_cycle(1)
21:58 Does fastai handle the last batch for you? Yes
fastai dataloaders by default include the last batch even when it is not full (less than 64 items), but you can set it to drop the last batch.
Don’t do shuffling dataset youself, it is very messy and error prone
The next version of fastai will replace current dataloader() with the pytorch dataloader.
23:17 How did Jeremy make sure the new learner has the same performance or (should) be the same as the learner using ImageDataLoaders.from_folder?
first, run the learner with super lean and fast setup;
then, use the same setup (architecture, image size, number of epochs) to see whether the performance is on the same error rate.
23:32 How to make your dataloader to spit out 3 things (image, dis_label, rice_label) in dls.show_batch()?
blocks=(ImageBlock, CategoryBlock, CategoryBlock)
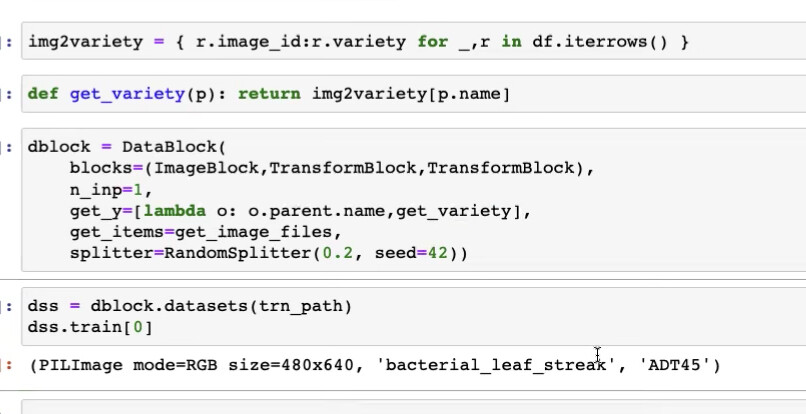
24:01 How to create a function to return rice type when given image id?
How to create a dictionary to map image id and rice type/variety?

How to turn this dictionary into a function to output rice type when given image id?
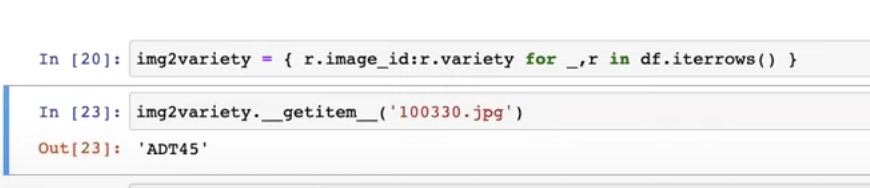
27:27 How to use two label_func to get two labels for get_y?
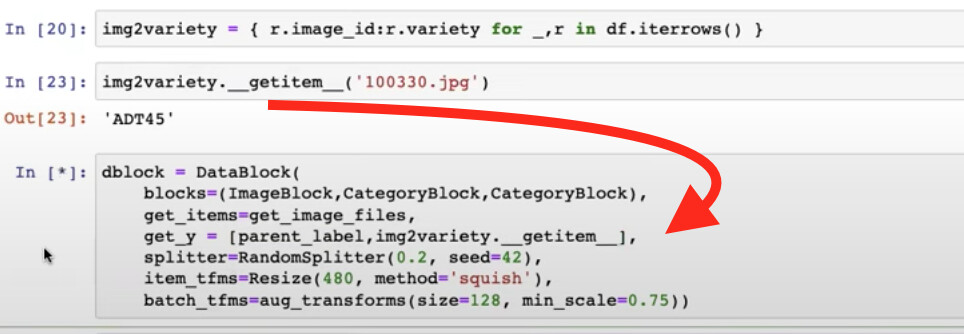
27:52 How to tell DataBlock that which (ImageBlock) is independent variable (input) and which two things (two CategoryBlocks) are dependent variable (label)?
The error message is very helpful
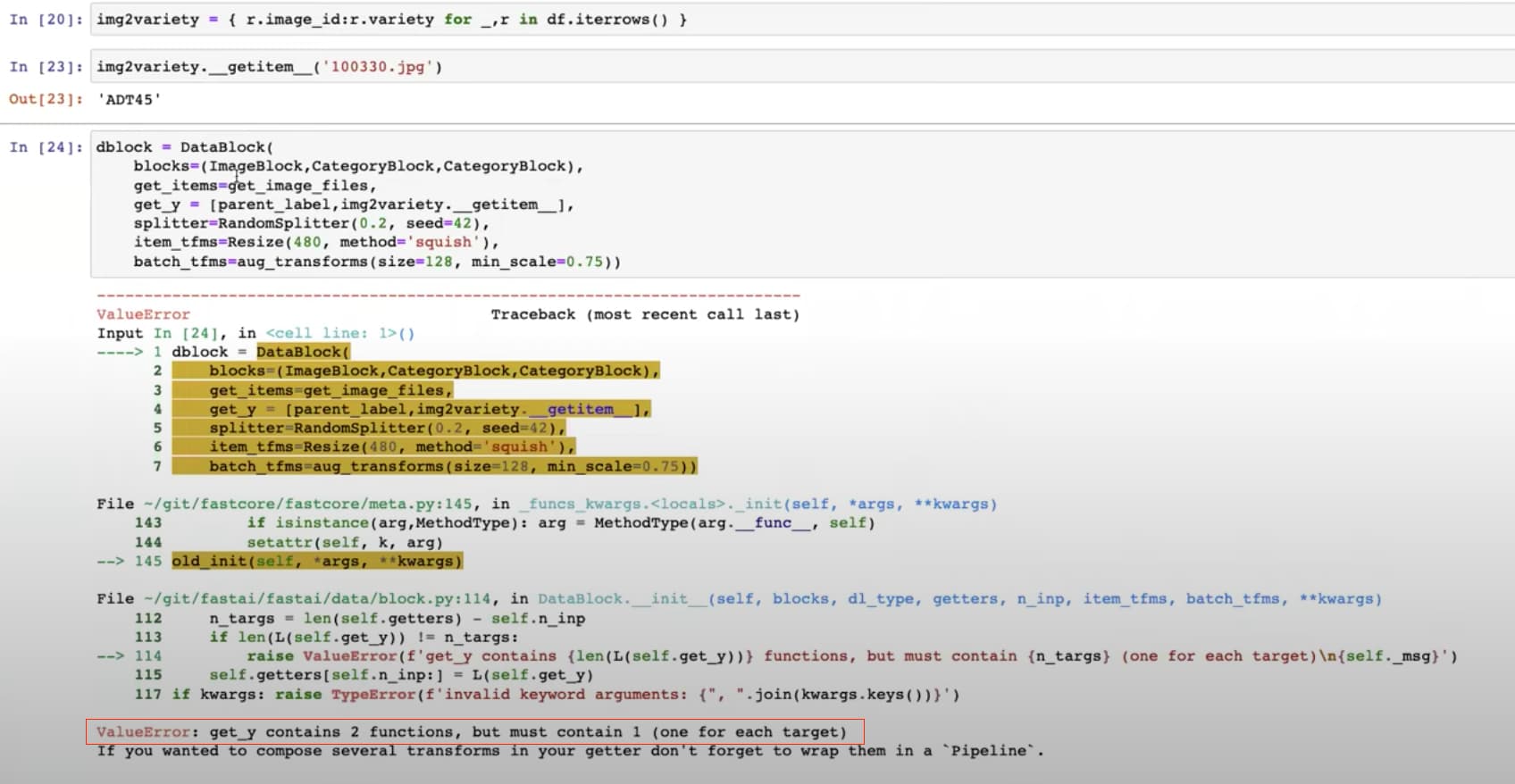
How to tell DataBlock the first (or ImageBlock here) is input and the rest are labels?
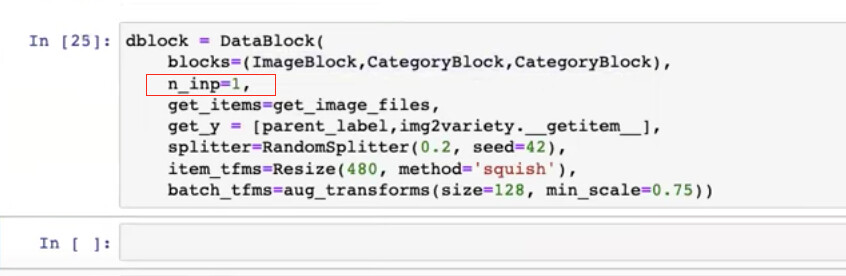
28:29 How to quickly test whether our new DataBlock or dblock is working? Why use datasets() instead of dataloaders()?
Because datasets() is much easier to debug than dataloaders()
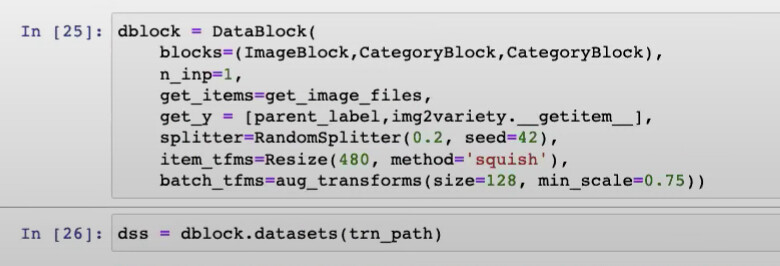
28:55 How to debug what’s the problem of our dblock when using datasets()?
KeyError: Path('train_images.../1022332.jpg' means that DataBlock is passing a image path rather than an image name (like 102232.jpg) into img2variety.__getitem__() instead of the name or image_id.
So this KeyError is more informative than the long traceback error message
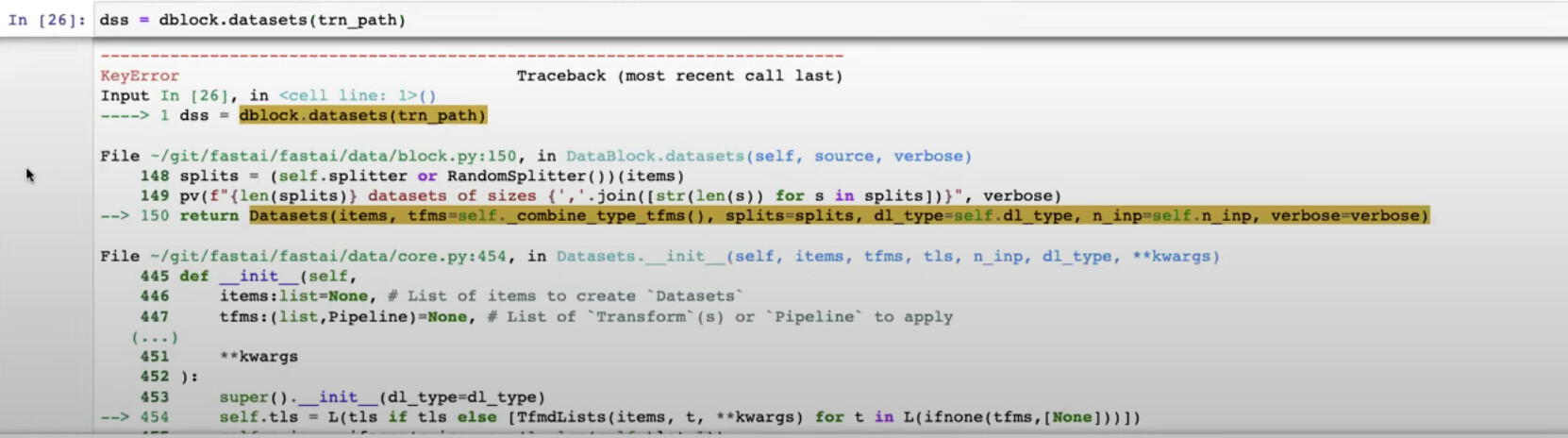
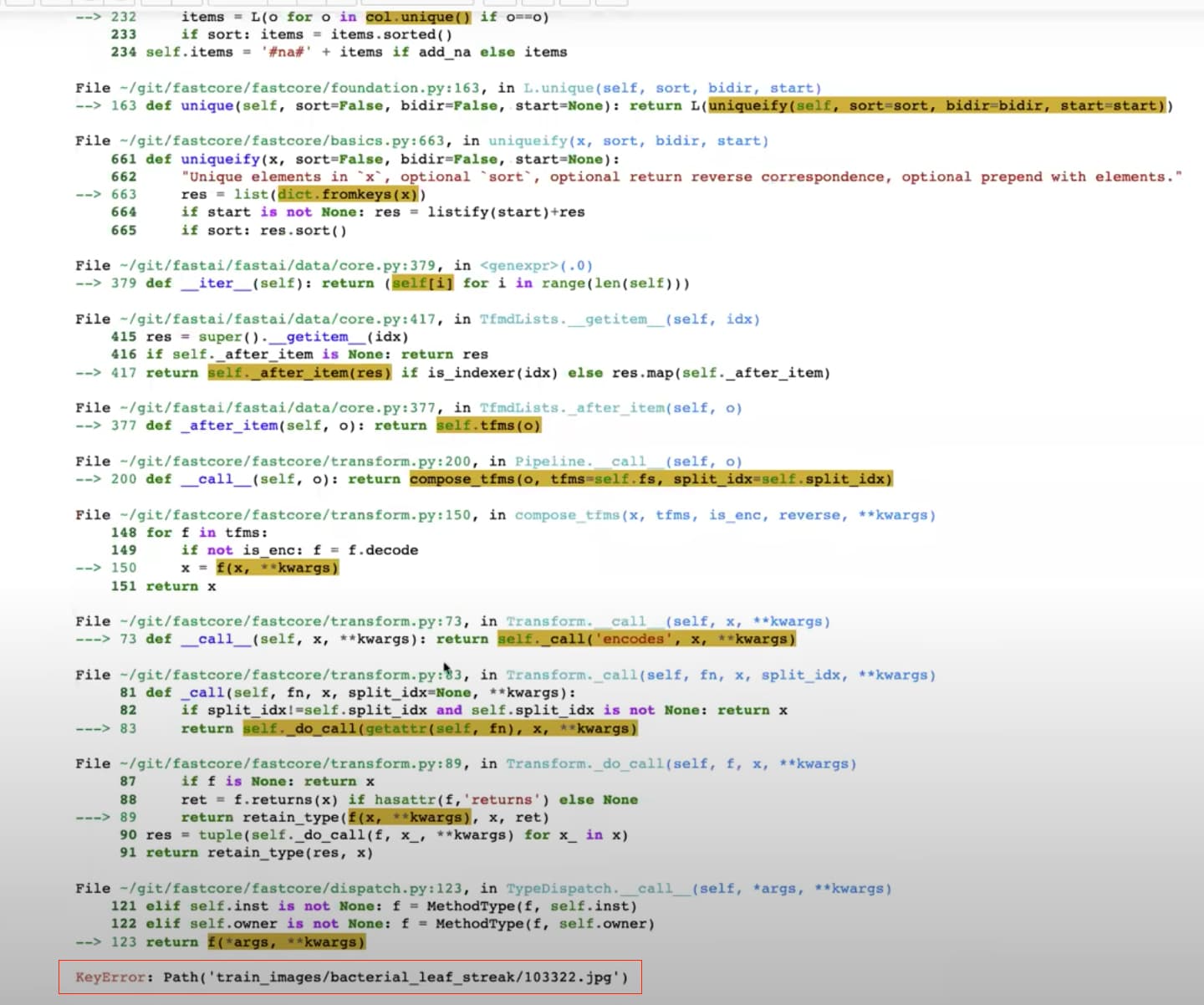
30:26 How to write a function that receives a path and returns a string of variety using img2variety?
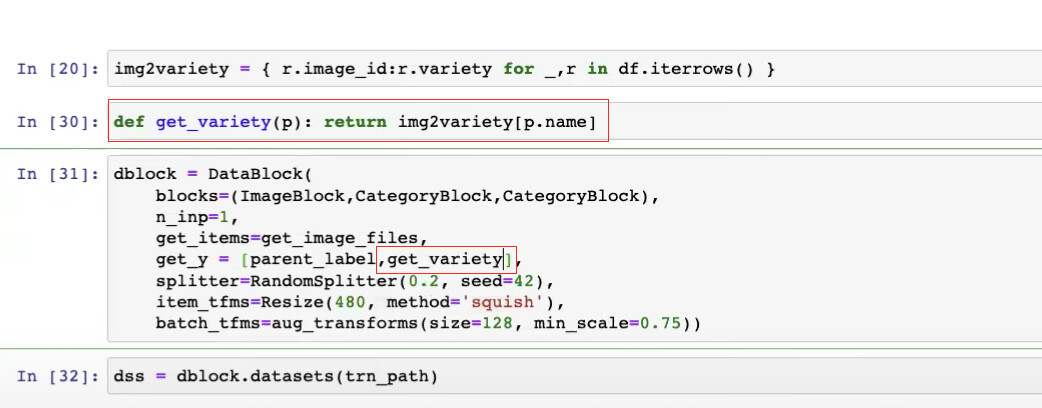
31:32 How to check whether our DataBlock is actually working by checking the datasets (train and valid)?
How to access the training and valid datasets?

How to check on the first item in training set?

How to see the image of the first training item
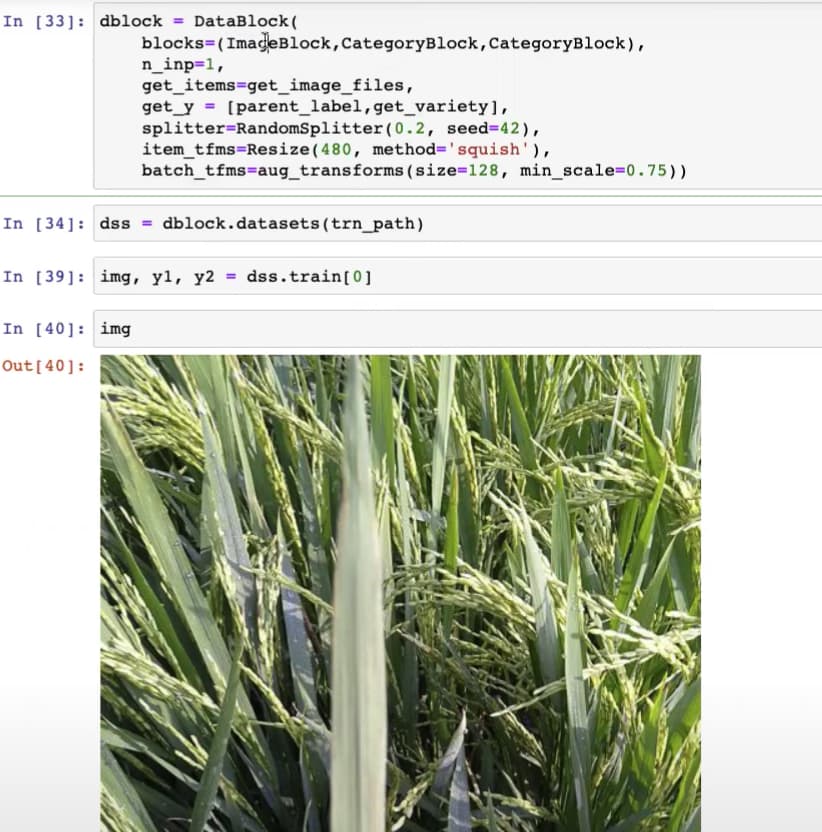
32:08 How does dblock.datasets use a folder path trn_path to build training and valid sets and get images and labels right?
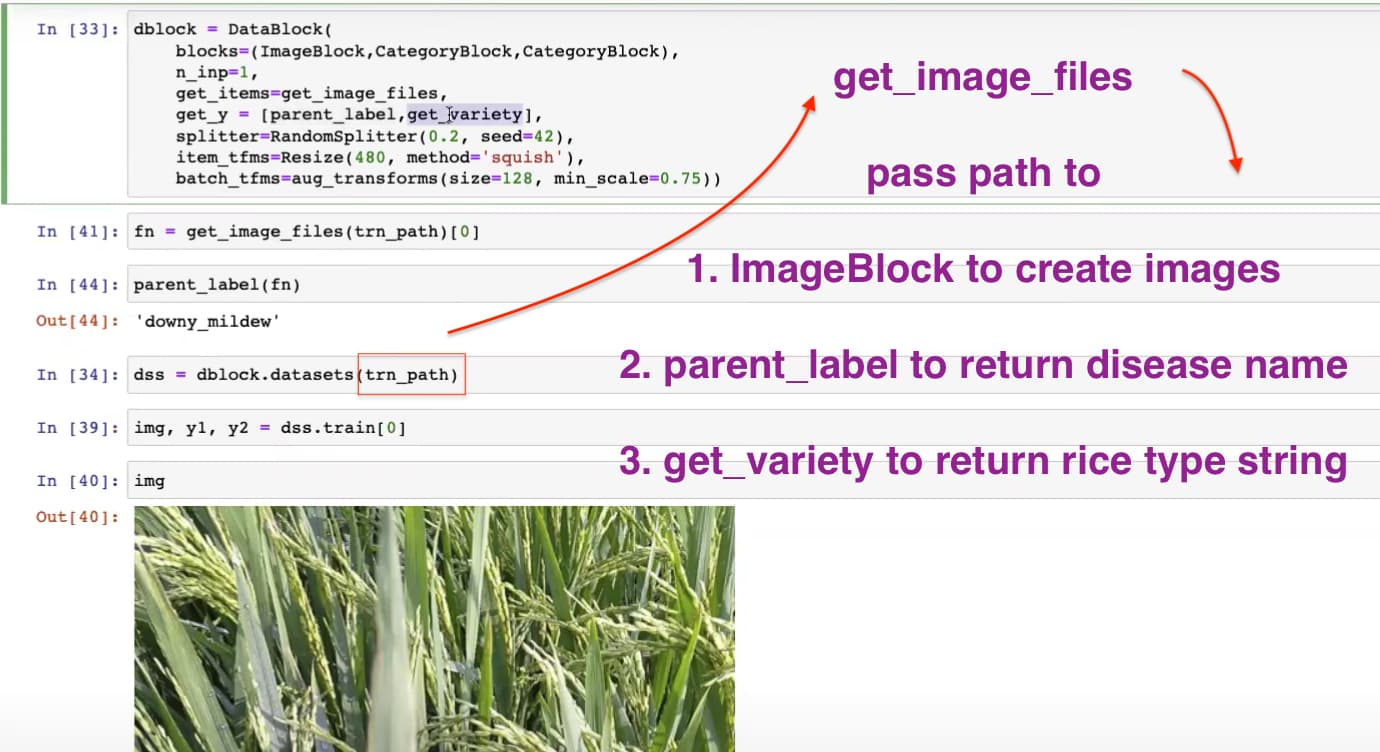
33:47 How to use get_items, get_y, get_x to their full potential?
35:20 How source (a dataframe) is delivered to DataBlock and get turned into a path by get_x as ImageBlock won’t accept a row of dataframe but a path or string of path and two strings as two labels by get_y
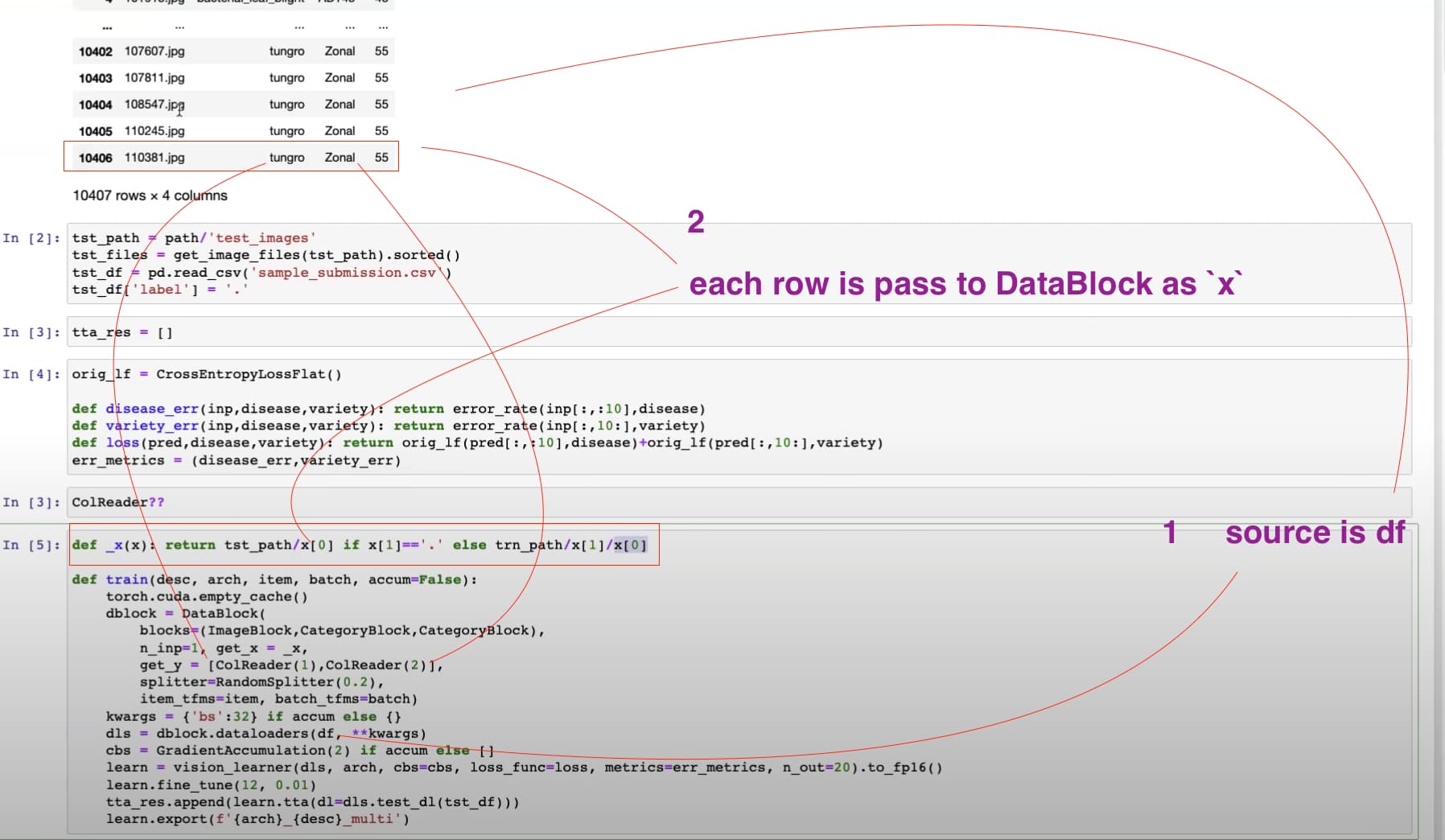

can get_x and get_y accept a list of functions like [ColReader(1), ColReader(2)]? yes, and Jeremy recommended to read docs to learn more; and I can confirm it in the source code
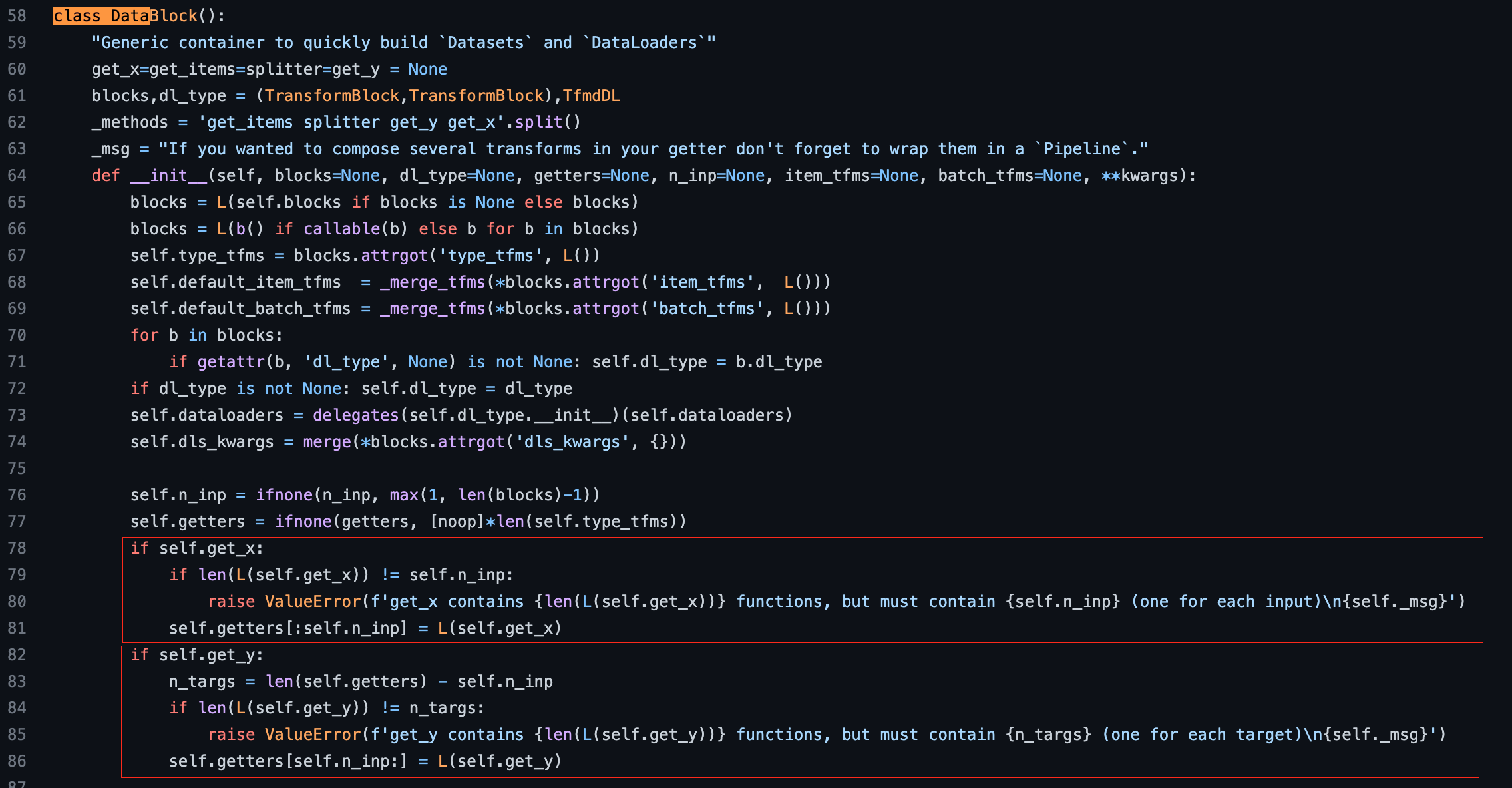
39:24 How does TransformBlock and ImageBlock works
The source code of TransformBlock and ImageBlock like most fastai source are very easy to read
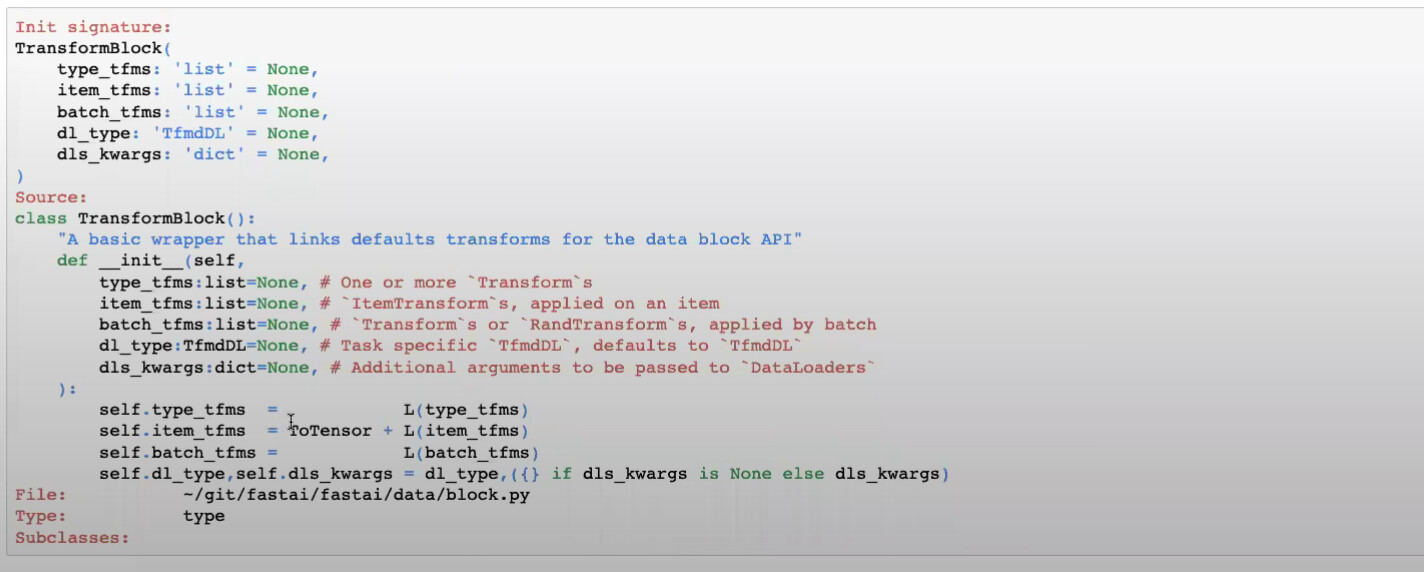

How to build the simplest DataBlock with the simplest blocks?
Instead of using ImageBlock and CategoryBlock, pure TransformBlock without adding any parameters will do nothing (no transforms) to items (or path) returned from get_items=get_image_files
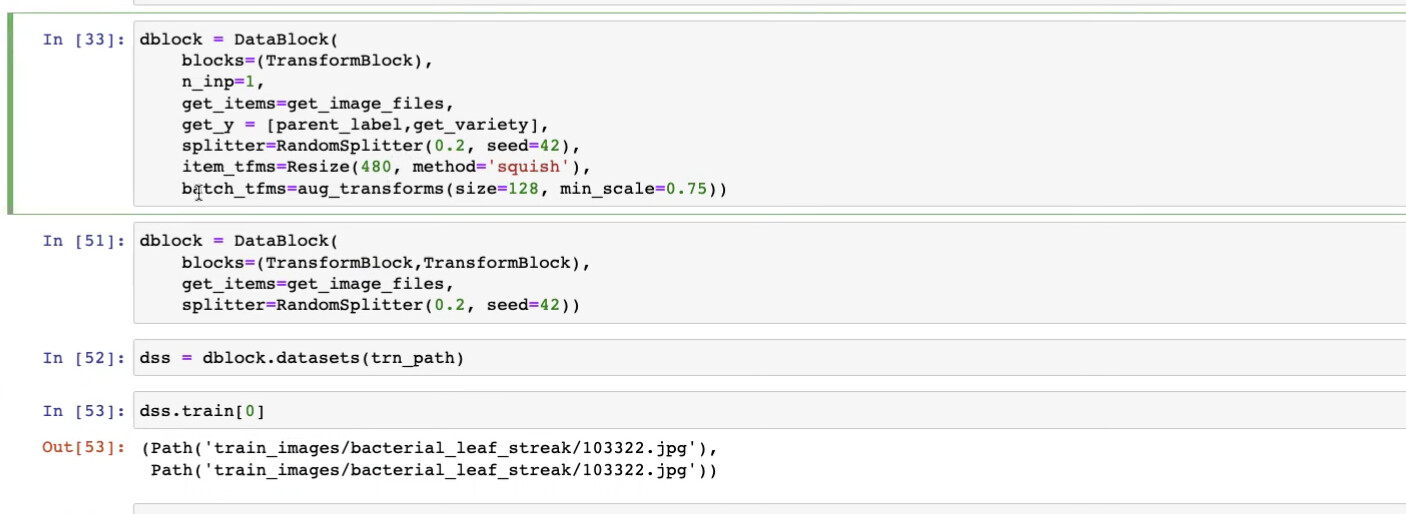
review the source code of TransformBlock here
What is the blocks in DataBlock, is it a tuple or a list?
Jeremy didn’t tell the answer, but we can confirm it to be a L in the source code
42:26 Where and How to create a function to process an item’s path and then pass it to the blocks of transforms?
43:31 How Jeremy tackle the local gpu server problem live?
continued from 45:06 get_x pass the result to the first TransformBlock and get_y passes to the second
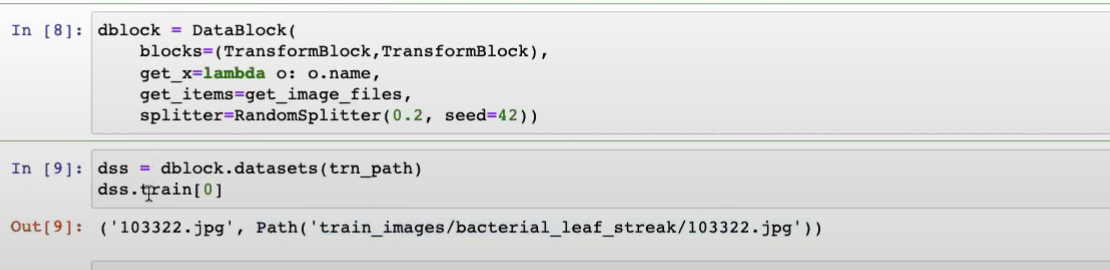
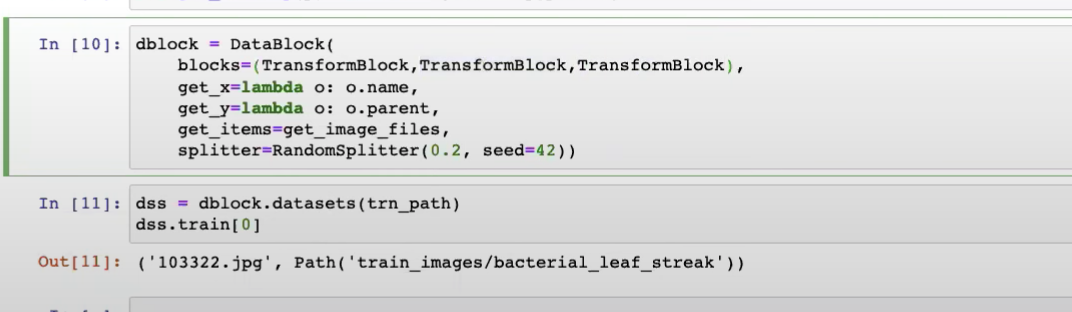
How does DataBlock know which get_x function applies to which TransformBlock?
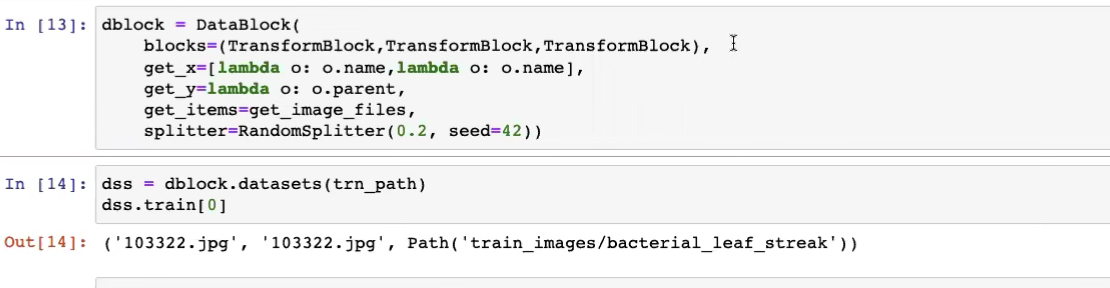
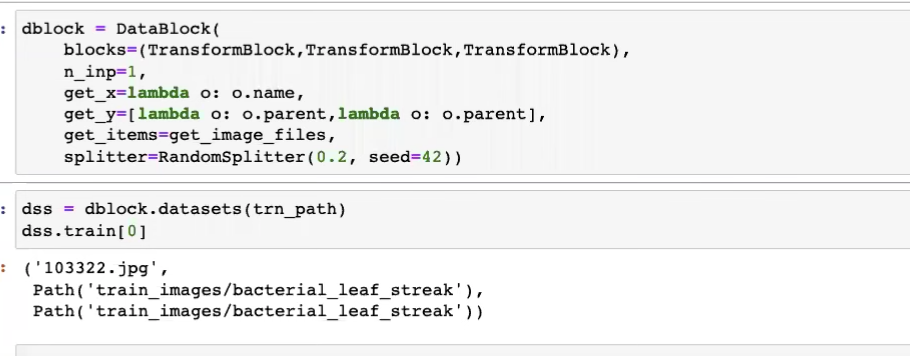
Can we give the get_x function to the first TransformBlock(type_tfms=[]) of the blocks instead?
yes, as blocks is full of functions to do transforms, we just need the get_x func under the type_tfms
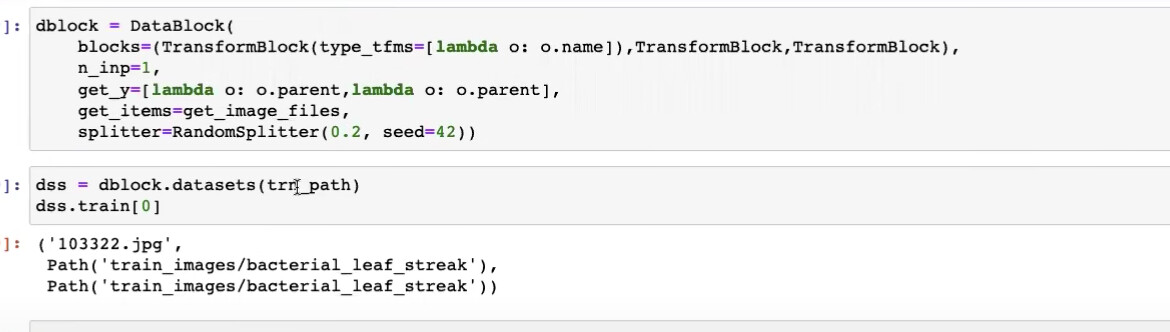
48:45 How to understand what are ImageBlock, TransformBlock
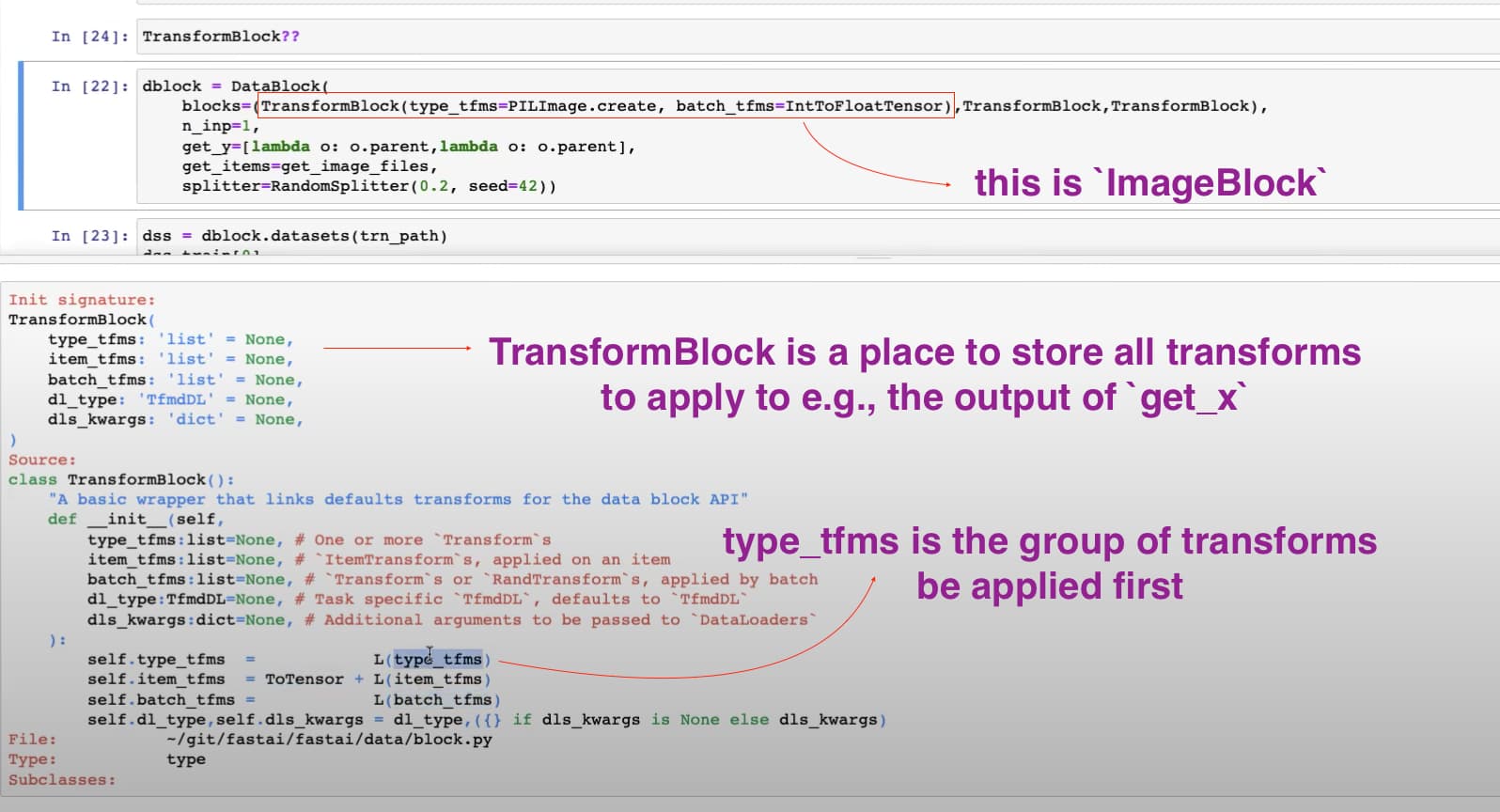
51:07 How do we know type_tfms get called before item_tfms, batch_tfms?
Jeremy showed us in the source that when dblock.datasets() only type_tfms get called, not the other tfms.
but how do we know get_x is called before type_tfms, given get_items must be called before all these functions above?
I found it in the source
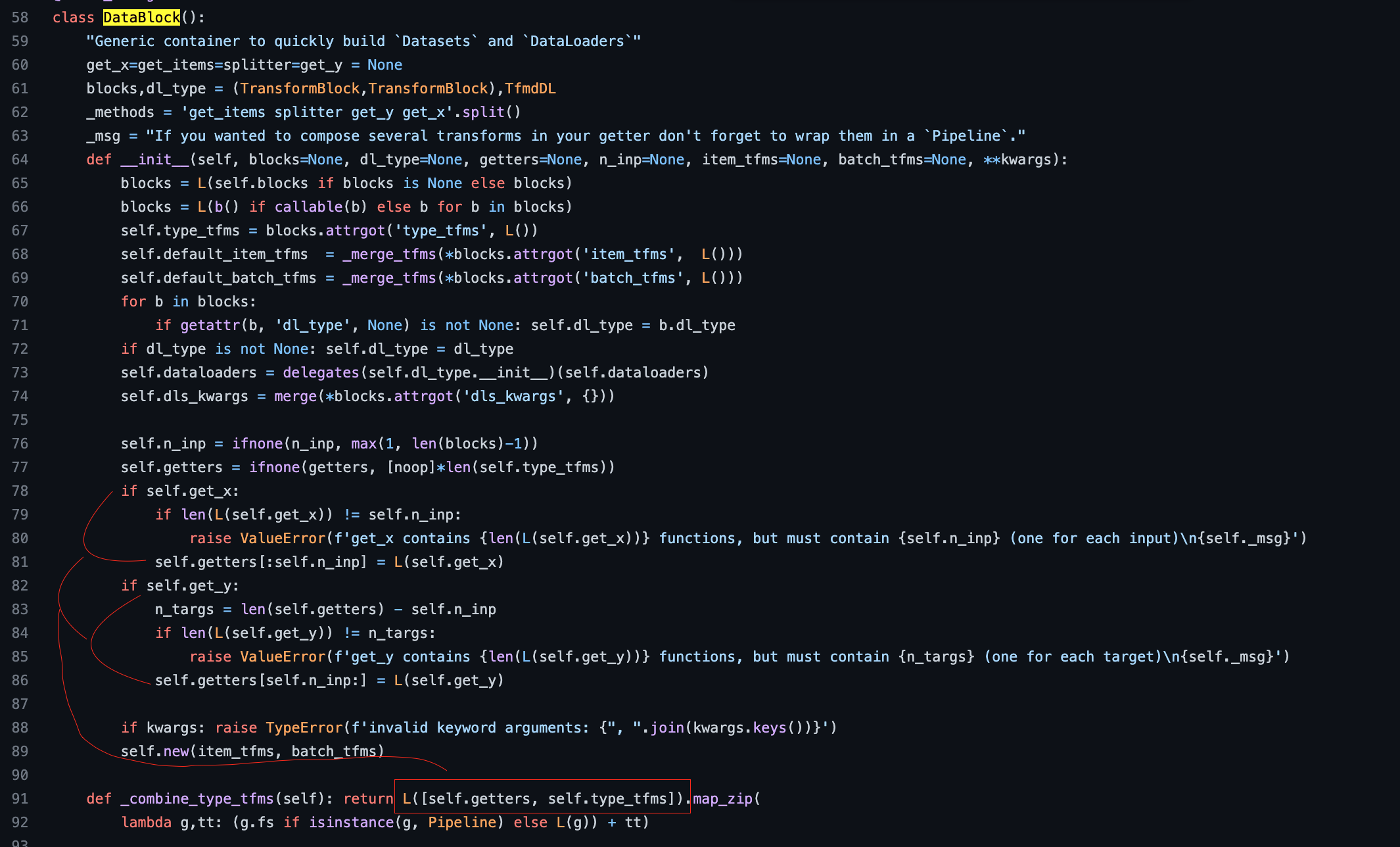
52:13 Why must type_tfms come first?
They must happen before dataloaders()
dataloaders receive tensors or convertable to tensors, and then do transforms on them
and type_tfms are to create datasets and spit out things that can be converted into tensors, in other words to make sure of the type is right
How do we know type_tfms get called before item_tfms and batch_tfms?
I can confirm with the source code below
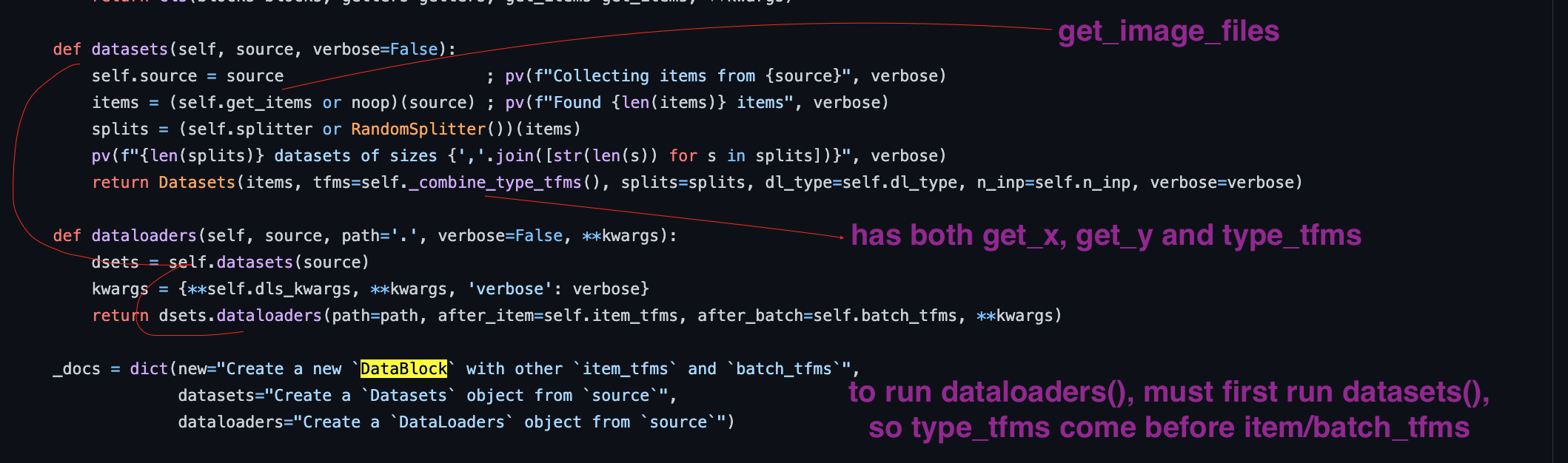
53:09 item_tfms and batch_tfms on GPU?
GPU not necessarily for item_tfms, a callback can determine whether batch_tfms is on GPU or not
54:07 Jeremy revealed the detailed logic of design for type_tfms (vs item_tfms and batch_tfms)
58:20 What does CategoryBlock do?
Before CategoryBlock, get_y can give us two strings for labels
However, we want get_y and type_tfms to help turn everything into tensors before dataloaders() apply item_tfms and batch_tfms onto those tensors
so, we use CategoryBlock to turn categorical labels into tensors
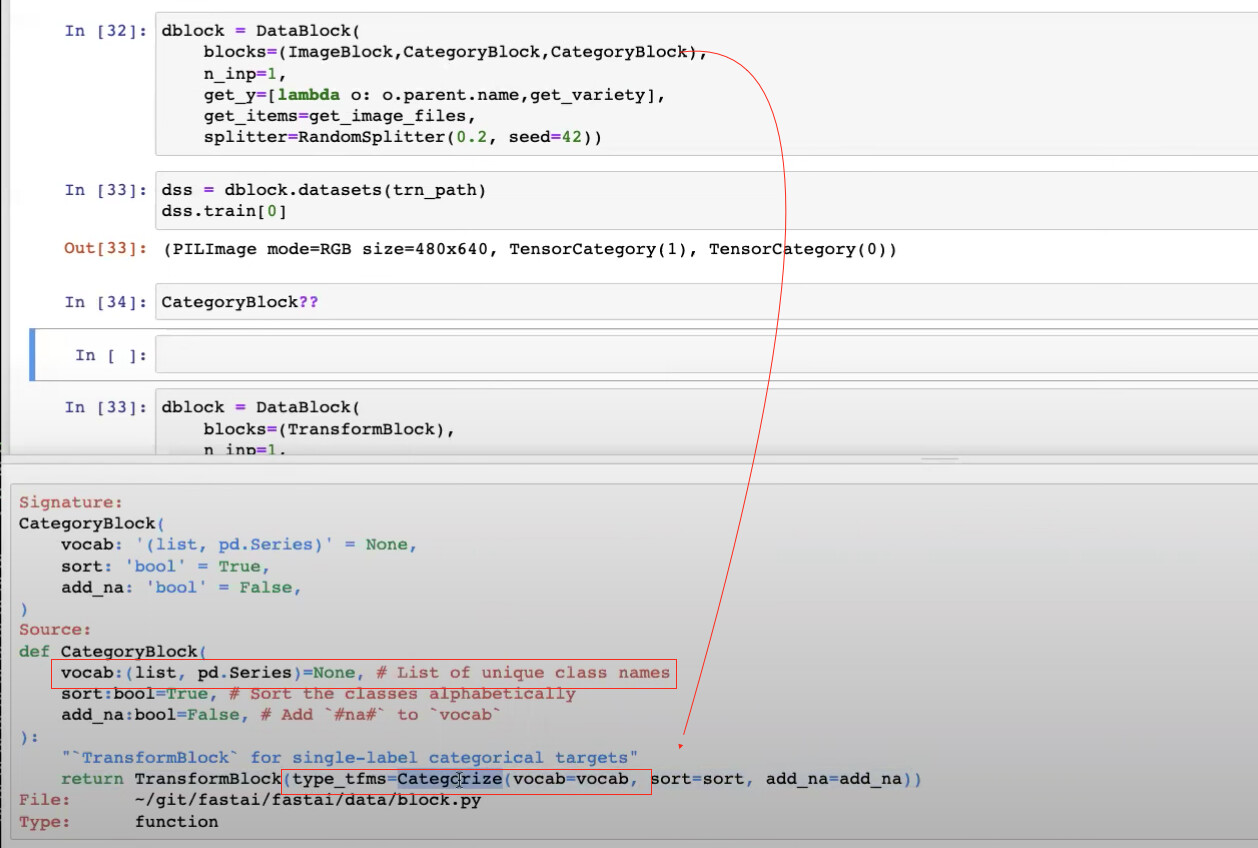
When the tfms of CategoryBlock get called?

From where can we access the label vocab transformed by Categorize from CategoryBlock?
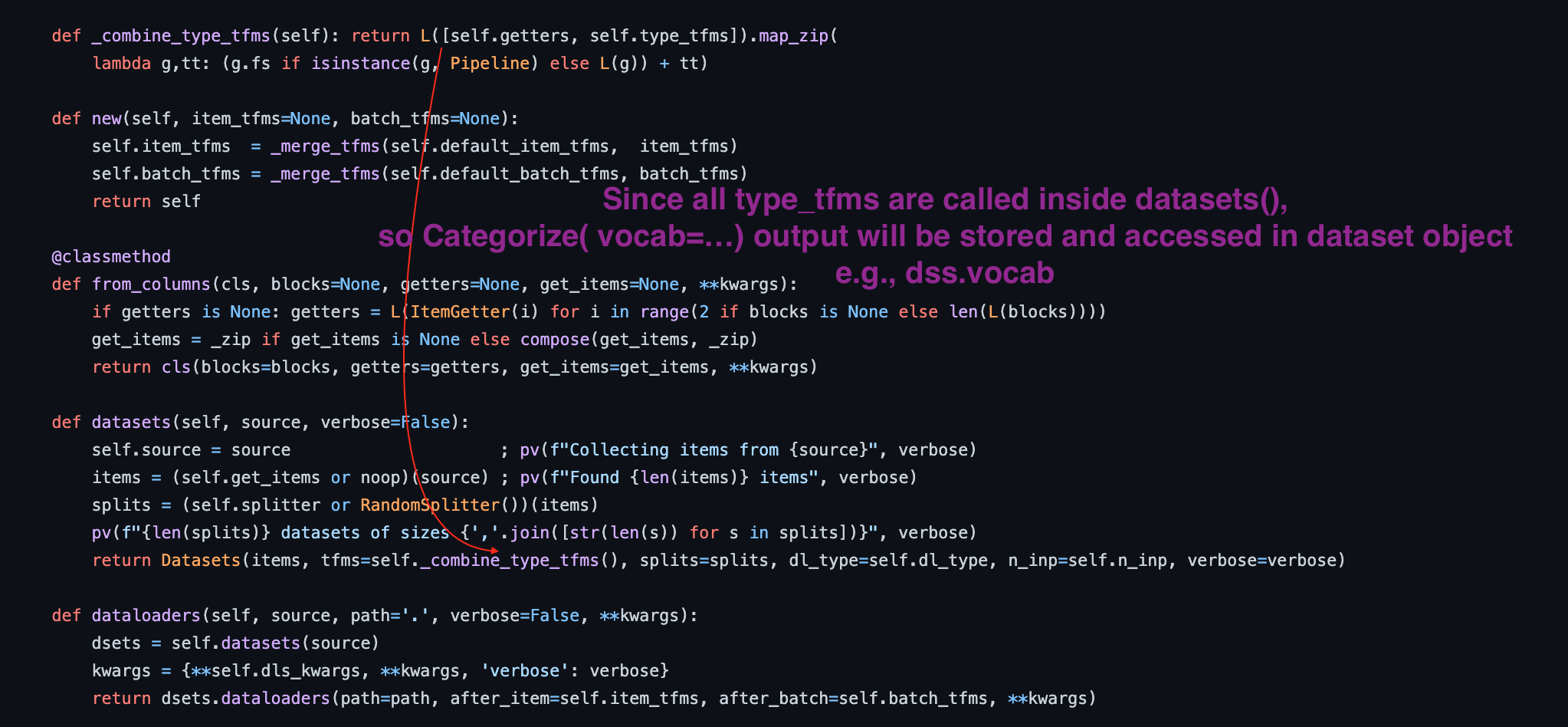
1:02:11 How does item_tfms only apply to image tensors not category tensors?
thanks to fastcore’s type dispatch
as Radek asked, if our y or labels are actually images, it means replacing the CategoryBlock with ImageBlock, then will item_tfms automatically get applied to images even though they are actually ys or dependent variables.
do check out Siemase tutorial
fastai’s amazingly powerful and flexible and transparent functionalities to do bounding box and segmentation and point clouds are unparallelled by other libraries
1:03:59 then fastai api automatically print out two labels nicely on top of the image

1:04:35 Do we have to tell our learner how many labels we are expecting?
yes, with n_out=20
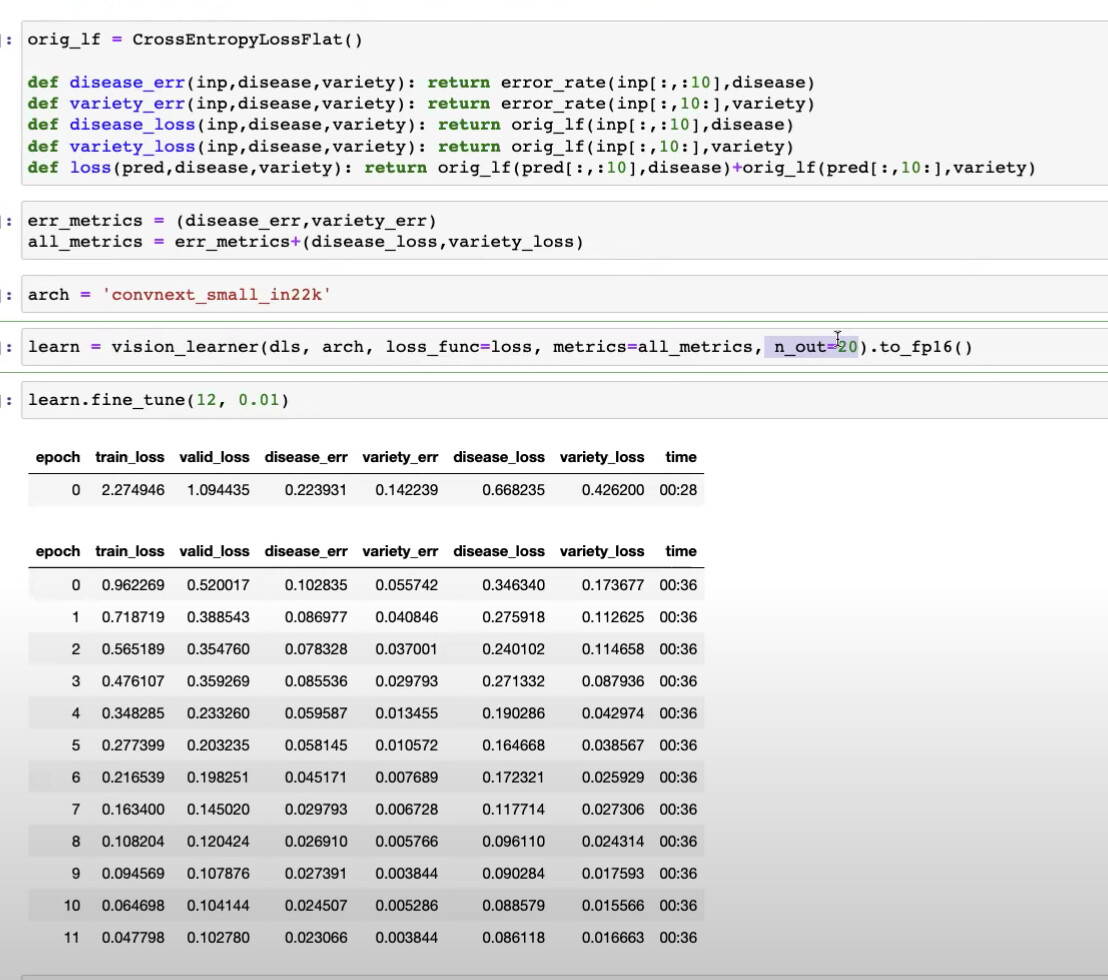
1:05:41 How to create error metrics and loss functions for disease and variety, and the total loss function? How to put them into the learner? Can we view them during training?
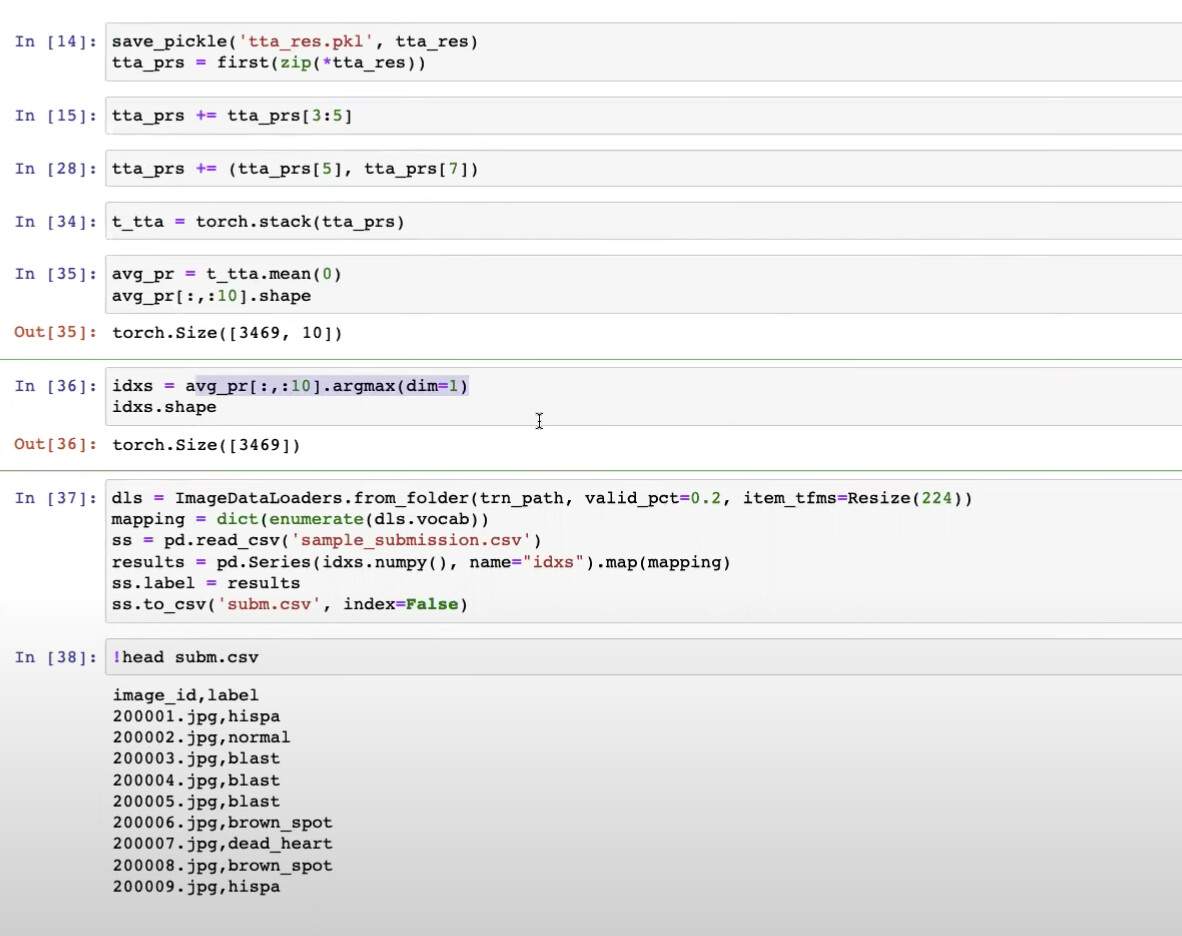
1:06:37 Do you need to add softmax function due to the custom loss during prediction?
How to access the ensemble results just for disease prediction?
3 Likes
Are there meant to be images in this? Any chance you could either include them, or remove the tags that aren’t working?
FYI you can paste images directly into the markdown editor here.
1 Like
Thanks for reply, Jeremy! I am sorry I have been irresponsibly lazy with those images.
You are right that uploading images is easy here. However, I have too many images (and I intend to keep doing notes with even more images), and currently I can only use editor’s find and replace feature to get those images into the right places in the post. So, it is very labour intensive.
I am still looking for a way to automate all these (loop through all the  and find the right ![[...]] and replace the latter with the former). But so far I have no clue how to do it. Do you have any suggestions? Thanks
I’d love to help with that! Can you explain exactly what search and replace it required? What’s the image URL required for each one exactly?
Alternatively, what if you did your original note-taking here in the forum thread, pasting the images in here directly as you write?
Do you need your notes in some other format as well? Would doing your notes as a blog (e.g on fastpages) instead of on the forum be more convenient?
Alternatively, it would be easy enough in vim to auto-delete the non-working image tags, if we’re not able to find a way to include them directly. But it would be nice to find a way for us to benefit from your work in creating images!
2 Likes
Yes, this makes things easier. I can take note in the usual place and at the same time paste note points with images onto forum along the way, without uploading all images and search and replace them all in the end.
Thanks again for replying to the note! Knowing people do read them on the forum gives me strength to make them better. I have updated the images and make them collapsible for better viewing.
Like @radek said communicating should be the real purpose of taking note, so a long detailed note on its own can be intimidating to read and difficult to use for discussion. This was the reason I feared long notes like this one won’t be actual use for others in the format of forum post at least, until I discovered this feature of forum below:
if there is header in the post, the header can form a link, and we can use the link to quickly come to the exactly location in the long post. This makes reference of specific note in a long detailed post so much easier. And of course the usual quote can display the specific note or point for better viewing.
Any more suggestions on the note? Thanks
1 Like
That looks great!
One more thing, if I updated the previous post (like I just did a minute ago) you replied, will the forum get you a notice for it?