fast.ai Course Forums
Part 2 Lesson 9 wiki
Part 2 & Alumni (2018)
Moody
(Sarada Lee)
March 31, 2018, 7:20pm
368
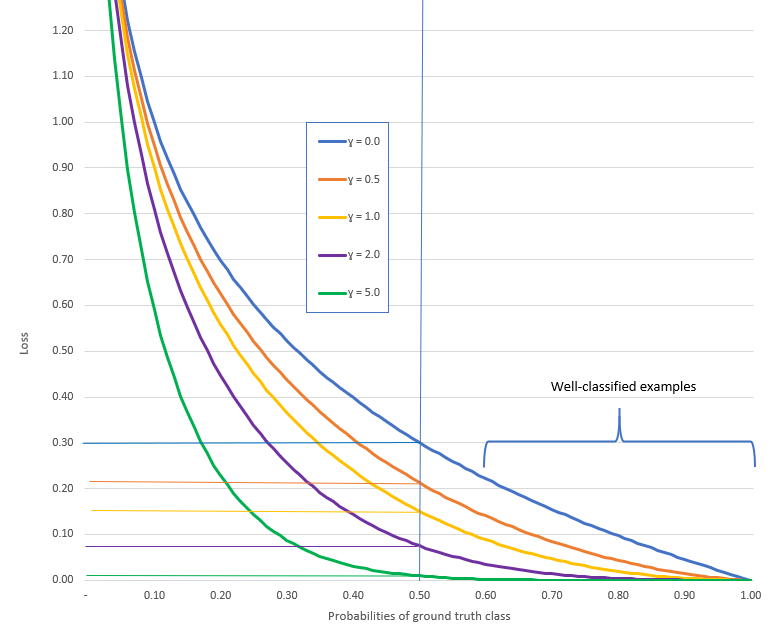
Done. Now, I can see the gamma value in relation to the loss.
image
783×643 40 KB
7 Likes
Live coding 16
show post in topic