fastbook Chapter 1 solutions
I thought in conjunction with the course, we could add the answers to the questionnaire for the fastbook chapters for people who are struggling. I have posted the questions here. @jeremy if you think this is a good idea, could we make this post a wiki so we could all add the answers?
Here are the questions:
- Do you need these for deep learning?
- Lots of math - False
- Lots of data - False
- Lots of expensive computers - False
- A PhD - False
- Name five areas where deep learning is now the best in the world:
Any five of the following:
Natural Language Processing (NLP) – Question Answering, Document Summarization and Classification, etc.
Computer Vision – Satellite and drone imagery interpretation, face detection and recognition, image captioning, etc.
Medicine – Finding anomalies in medical images (ex: CT, X-ray, MRI), detecting features in tissue slides (pathology), diagnosing diabetic retinopathy, etc.
Biology – Folding proteins, classifying, genomics tasks, cell classification, etc.
Image generation/enhancement – colorizing images, improving image resolution (super-resolution), removing noise from images (denoising), converting images to art in style of famous artists (style transfer), etc.
Recommendation systems – web search, product recommendations, etc.
Playing games – Super-human performance in Chess, Go, Atari games, etc
Robotics – handling objects that are challenging to locate (e.g. transparent, shiny, lack of texture) or hard to pick up
Other applications – financial and logistical forecasting; text to speech; much much more.
- What was the name of the first device that was based on the principle of the artificial neuron?
Mark I perceptron built by Frank Rosenblatt
- Based on the book of the same name, what are the requirements for “Parallel Distributed Processing”?
- A set of processing units
- A state of activation
- An output function for each unit
- A pattern of connectivity among units
- A propagation rule for propagating patterns of activities through the network of connectivities
- An activation rule for combining the inputs impinging on a unit with the current state of that unit to produce a new level of activation for the unit
- A learning rule whereby patterns of connectivity are modified by experience
- An environment within which the system must operate
- What were the two theoretical misunderstandings that held back the field of neural networks?
In 1969, Marvin Minsky and Seymour Papert demonstrated in their book, “Perceptrons”, that a single layer of artificial neurons cannot learn simple, critical mathematical functions like XOR logic gate. While they subsequently demonstrated in the same book that additional layers can solve this problem, only the first insight was recognized, leading to the start of the first AI winter.
In the 1980’s, models with two layers were being explored. Theoretically, it is possible to approximate any mathematical function using two layers of artificial neurons. However, in practices, these networks were too big and too slow. While it was demonstrated that adding additional layers improved performance, this insight was not acknowledged, and the second AI winter began. In this past decade, with increased data availability, and improvements in computer hardware (both in CPU performance but more importantly in GPU performance), neural networks are finally living up to its potential.
- What is a GPU?
GPU stands for Graphics Processing Unit (also known as a graphics card). Standard computers have various components like CPUs, RAM, etc. CPUs, or central processing units, are the core units of all standard computers, and they execute the instructions that make up computer programs. GPUs, on the other hand, are specialized units meant for displaying graphics, especially the 3D graphics in modern computer games. The hardware optimizations used in GPUs allow it to handle thousands of tasks at the same time. Incidentally, these optimizations allow us to run and train neural networks hundreds of times faster than a regular CPU.
- Open a notebook and execute a cell containing: 1+1 . What happens?
In a Jupyter Notebook, we can create code cells and run code in an interactive manner. When we execute a cell containing some code (in this case: 1+1), the code is run by Python and the output is displayed underneath the code cell (in this case: 2).
- Follow through each cell of the stripped version of the notebook for this chapter. Before executing each cell, guess what will happen.
To be done by the reader.
- Complete the Jupyter Notebook online appendix.
To be done by the reader.
- Why is it hard to use a traditional computer program to recognize images in a photo?
For us humans, it is easy to identify images in a photos, such as identifying cats vs dogs in a photo. This is because, subconsciously our brains have learned which features define a cat or a dog for example. But it is hard to define set rules for a traditional computer program to recognize a cat or a dog. Can you think of a universal rule to determine if a photo contains a cat or dog? How would you encode that as a computer program? This is very difficult because cats, dogs, or other objects, have a wide variety of shapes, textures, colors, and other features, and it is close to impossible to manually encode this in a traditional computer program.
- What did Samuel mean by “Weight Assignment”?
“weight assignment” refers to the current values of the model parameters. Arthur Samuel further mentions an “ automatic means of testing the effectiveness of any current weight assignment ” and a “ mechanism for altering the weight assignment so as to maximize the performance ”. This refers to the evaluation and training of the model in order to obtain a set of parameter values that maximizes model performance.
- What term do we normally use in deep learning for what Samuel called “Weights”?
We instead use the term parameters. In deep learning, the term “weights” has a separate meaning. (The neural network has various parameters that we fit our data to. As shown in upcoming chapters, the two types of neural network parameters are weights and biases)
- Draw a picture that summarizes Arthur Samuel’s view of a machine learning model
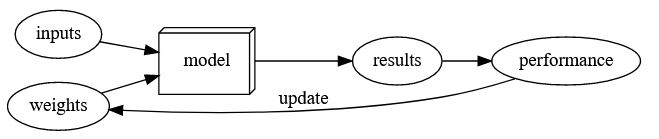
- Why is it hard to understand why a deep learning model makes a particular prediction?
This is a highly-researched topic known as interpretability of deep learning models. Deep learning models are hard to understand in part due to their “deep” nature. Think of a linear regression model. Simply, we have some input variables/data that are multiplied by some weights, giving us an output. We can understand which variables are more important and which are less important based on their weights. A similar logic might apply for a small neural network with 1-3 layers. However, deep neural networks have hundreds, if not thousands, of layers. It is hard to determine which factors are important in determining the final output. The neurons in the network interact with each other, with the outputs of some neurons feeding into other neurons. Altogether, due to the complex nature of deep learning models, it is very difficult to understand why a neural network makes a given prediction.
However, in some cases, recent research has made it easier to better understand a neural network’s prediction. For example, as shown in this chapter, we can analyze the sets of weights and determine what kind of features activate the neurons. When applying CNNs to images, we can also see which parts of the images highly activate the model. We will see how we can make our models interpretable later in the book.
- What is the name of the theorem that a neural network can solve any mathematical problem to any level of accuracy?
The universal approximation theorem states that neural networks can theoretically represent any mathematical function. However, it is important to realize that practically, due to the limits of available data and computer hardware, it is impossible to practically train a model to do so. But we can get very close!
- What do you need in order to train a model?
You will need an architecture for the given problem. You will need data to input to your model. For most use-cases of deep learning, you will need labels for your data to compare your model predictions to. You will need a loss function that will quantitatively measure the performance of your model. And you need a way to update the parameters of the model in order to improve its performance (this is known as an optimizer).
- How could a feedback loop impact the rollout of a predictive policing model?
In a predictive policing model, we might end up with a positive feedback loop, leading to a highly biased model with little predictive power. For example, we may want a model that would predict crimes, but we use information on arrests as a proxy . However, this data itself is slightly biased due to the biases in existing policing processes. Training with this data leads to a biased model. Law enforcement might use the model to determine where to focus police activity, increasing arrests in those areas. These additional arrests would be used in training future iterations of models, leading to an even more biased model. This cycle continues as a positive feedback loop
- Do we always have to use 224x224 pixel images with the cat recognition model?
No we do not. 224x224 is commonly used for historical reasons. You can increase the size and get better performance, but at the price of speed and memory consumption.
- What is the difference between classification and regression?
Classification is focused on predicting a class or category (ex: type of pet). Regression is focused on predicting a numeric quantity (ex: age of pet).
- What is a validation set? What is a test set? Why do we need them?
The validation set is the portion of the dataset that is not used for training the model, but for evaluating the model during training, in order to prevent overfitting. This ensures that the model performance is not due to “cheating” or memorization of the dataset, but rather because it learns the appropriate features to use for prediction. However, it is possible that we overfit the validation data as well. This is because the human modeler is also part of the training process, adjusting hyperparameters (see question 32 for definition) and training procedures according to the validation performance. Therefore, another unseen portion of the dataset, the test set, is used for final evaluation of the model. This splitting of the dataset is necessary to ensure that the model generalizes to unseen data.
- What will fastai do if you don’t provide a validation set?
fastai will automatically create a validation dataset. It will randomly take 20% of the data and assign it as the validation set (
valid_pct=0.2).
- Can we always use a random sample for a validation set? Why or why not?
A good validation or test set should be representative of new data you will see in the future. Sometimes this isn’t true if a random sample is used. For example, for time series data, selecting sets randomly does not make sense. Instead, defining different time periods for the train, validation, and test set is a better approach.
- What is overfitting? Provide an example.
Overfitting is the most challenging issue when it comes to training machine learning models. Overfitting refers to when the model fits too closely to a limited set of data but does not generalize well to unseen data. This is especially important when it comes to neural networks, because neural networks can potentially “memorize” the dataset that the model was trained on, and will perform abysmally on unseen data because it didn’t “memorize” the ground truth values for that data. This is why a proper validation framework is needed by splitting the data into training, validation, and test sets.
- What is a metric? How does it differ to “loss”?
A metric is a function that measures quality of the model’s predictions using the validation set. This is similar to the loss , which is also a measure of performance of the model. However, loss is meant for the optimization algorithm (like SGD) to efficiently update the model parameters, while metrics are human-interpretable measures of performance. Sometimes, a metric may also be a good choice for the loss.
- How can pretrained models help?
Pretrained models have been trained on other problems that may be quite similar to the current task. For example, pretrained image recognition models were often trained on the ImageNet dataset, which has 1000 classes focused on a lot of different types of visual objects. Pretrained models are useful because they have already learned how to handle a lot of simple features like edge and color detection. However, since the model was trained for a different task than already used, this model cannot be used as is.
- What is the “head” of a model?
When using a pretrained model, the later layers of the model, which were useful for the task that the model was originally trained on, are replaced with one or more new layers with randomized weights, of an appropriate size for the dataset you are working with. These new layers are called the “head” of the model.
- What kinds of features do the early layers of a CNN find? How about the later layers?
Earlier layers learn simple features like diagonal, horizontal, and vertical edges. Later layers learn more advanced features like car wheels, flower petals, and even outlines of animals.
- Are image models only useful for photos?
Nope! Image models can be useful for other types of images like sketches, medical data, etc.
However, a lot of information can be represented as images . For example, a sound can be converted into a spectrogram, which is a visual interpretation of the audio. Time series (ex: financial data) can be converted to image by plotting on a graph. Even better, there are various transformations that generate images from time series, and have achieved good results for time series classification. There are many other examples, and by being creative, it may be possible to formulate your problem as an image classification problem, and use pretrained image models to obtain state-of-the-art results!
- What is an “architecture”?
The architecture is the template or structure of the model we are trying to fit. It defines the mathematical model we are trying to fit.
- What is segmentation?
At its core, segmentation is a pixelwise classification problem. We attempt to predict a label for every single pixel in the image. This provides a mask for which parts of the image correspond to the given label.
- What is y_range used for? When do we need it?
y_range is being used to limit the values predicted when our problem is focused on predicting a numeric value in a given range (ex: predicting movie ratings, range of 0.5-5).
- What are “hyperparameters”?
Training models requires various other parameters that define how the model is trained. For example, we need to define how long we train for, or what learning rate (how fast the model parameters are allowed to change) is used. These sorts of parameters are hyperparameters.
- What’s the best way to avoid failures when using AI in an organization?
Key things to consider when using AI in an organization:
- Make sure a training, validation, and testing set is defined properly in order to evaluate the model in an appropriate manner.
- Try out a simple baseline, which future models should hopefully beat. Or even this simple baseline may be enough in some cases.
