In reference to your point about #16: From my understanding, it makes sense to separate the loss function and the optimizer. Before you can optimize and update weights, first you must know how good/bad the current weights are. Therefore, it’s important to recognize that we need a loss function in order to train a model. Point 24 is just following up and making sure we know what a loss function is.
I was wondering if it’s ok to create blogs answering the questions in the book?
I don’t see why not!
Yes I do 
1 Like

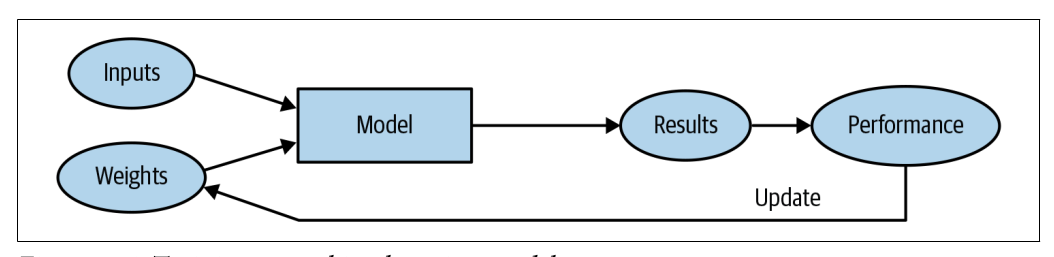
Where do we set the “loss” criteria for the actual optimization method? Is it hardcoded in the “architecture” ? In codes of chapter 1, only metric is set…
Hi,
I created this article from Lesson 1. It has the answers to the first set of questions. Thanks for the awesome course:
2 Likes
" Answers to all these questions are also available on the book’s website." is written in chapter 1 but I can see only your provided answers here in the forum. Do you know where the original answers are located on the book website?
These threads/wikis can be considered the answers
@jeremy would you happen to know if there are similar forum posts that post questionnaire solutions to the subsequent chapters. We have a study group for 2022 that we started and this would be a good resource to use.
Thank you for a wonderful MOOC. Best one I have ever taken!!!
Please find here the wiki thread that summarize all the solutions for each chapter Fastbook questionnaire solutions- MegaThread . And I think you should not @ jeremy except case that he is the only one who can answer the question.
Happy learning !!
2 Likes
Hi,
What is the Jupyter Notebook online appendix. in:
9. Complete the Jupyter Notebook online appendix.
I promise I gave it all in trying to find it ![]()
@tymtam I came looking for the same thing. Given the order in the questionnaire, I believe this may be the Jupyter Notebook online appendix.
1 Like
While browsing Twitter, I came across another example of the misuse of a random split.The tweet belongs to @svpino . x.com
For those who are not on Twitter, I will paste the tweet below.
"Andrew Ng is one of the most recognized researchers in the world.
In 2017, a team he led published a paper with a huge mistake. 11 days later, they had to publish a correction.
Here is what happened:
Their paper was about a model to detect pneumonia.
The team annotated every image showing pneumonia as positive and labeled everything else as negative.
Their dataset had 112,120 images from 30,805 unique patients. They randomly split it into 80% training and 20% validation.
Notice how they had around four times more images than patients.
This means that at least some patients contributed more than one picture to the data.
That wouldn’t be an issue, except when using a random split.
Imagine that one patient had a scar from a previous surgery. This scar would be visible in every X-ray image.
The random split could send some of these images to the train set and others to the validation set.
Do you see where I’m going with this?
The model may use the scar to label every image from the same patient the same way.
Assuming this patient had pneumonia, the model might conclude that any validation image with the same scar would also belong to the positive class.
The team created a leaky validation strategy!
A dataset with correlation or groupings between individual samples is not a good candidate for random splits.
If information leaks from the training data into the validation data, your validation score will look much better than it should be.
The team updated their paper a few days later. This time, they changed their training strategy.
They split the data by keeping images from the same patient together. This approach removed the overlap between the sets and fixed the issue.
Two lessons from this story:
-
Random splits can lead to a leaky validation strategy. Watch out for that!
-
Everyone makes mistakes. That’s the only way we can learn and make progress."
3 Likes
Future Research question GPU or CPU. Found an interesting article at mckinsey.
Hi @ilovescience , In your response to question 24, I think instead of ’ Sometimes, a metric may also be a good choice for the loss.’ we should say ’ Sometimes, the loss may also be a good choice for a metric’
Hi everyone, I’ve just started the course and thought of building a quizlet of all the chapters, starting from the beginning. You can refer to it to improve your understanding of the fundamentals of DL. I’ve used @ilovescience 's response to build this quiz. I’ll be actively learning from Fast.ai so it’ll be great to connect with peers who are interested in learning DL.
3 Likes
Thanks Arya, your quiz helps a lot!
Cheers Tanishq!