fast.ai Course Forums
CHAPTER 1 Fastbook Discussion
Part 1 (2020)
mdkhalid
(Khalid)
July 10, 2023, 10:34pm
8
image
821×396 21.6 KB
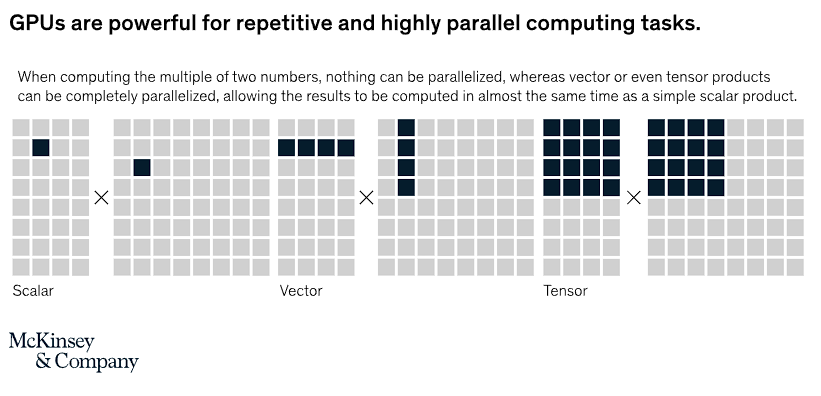
An interesting visualisation of cpu vs gpu by Mckinsey.
Link
Fastbook Chapter 1 questionnaire solutions (wiki)
show post in topic