<<< Wiki: Lesson 5 | Wiki: Lesson 7 >>>
Lesson resources
- Lesson video
- Video timelines for Lesson 6
- Lesson notes from @timlee
- Lesson notes from @hiromi
- The ppt presentation is in the github repo
- Optimization for Deep Learning Highlights in 2017 by Sebastian Ruder
- Entity Embeddings of Categorical Variables - Guo, Berkhahn paper
- Nietzsche notes! lesson 6 from @amritv
- Configure tags for code navigation in vim
Video timelines for Lesson 6
-
00:00:10 Review of articles and works
“Optimization for Deep Learning Highlights in 2017” by Sebastian Ruder,
“Implementation of AdamW/SGDW paper in Fastai”,
“Improving the way we work with learning rate”,
“The Cyclical Learning Rate technique” -
00:02:10 Review of last week “Deep Dive into Collaborative Filtering” with MovieLens, analyzing our model, ‘movie bias’, ‘@property’, ‘self.models.model’, ‘learn.models’, ‘CollabFilterModel’, ‘get_layer_groups(self)’, ‘lesson5-movielens.ipynb’
-
00:12:10 Jeremy: “I try to use Numpy for everything, except when I need to run it on GPU, or derivatives”,
Question: “Bring the model from GPU to CPU into production ?”, move the model to CPU with ‘m.cpu()’, ‘load_model(m, p)’, back to GPU with ‘m.cuda()’, ‘zip()’ function in Python -
00:16:10 Sort the movies, John Travolta Scientology worst movie of all time “Battlefield Earth”, ‘key=itemgetter()jj’, ‘key=lambda’
-
00:18:30 Embedding interpration, using ‘PCA’ from ‘sklearn.decomposition’ for Linear Algebra
-
00:24:15 Looking at the “Rossmann Retail / Store” Kaggle competition with the ‘Entity Embeddings of Categorical Variables’ paper.
-
00:41:02 “Rossmann” Data Cleaning / Feature Engineering, using a Test set properly, Create Features (check the Machine Learning “ML1” course for details), ‘apply_cats’ instead of ‘train_cats’, ‘pred_test = m.predict(True)’, result on Kaggle Public Leaderboard vs Private Leaderboard with a poor Validation Set. Example: Statoil/Iceberg challenge/competition.
-
00:47:10 A mistake made by Rossmann 3rd winner, more on the Rossmann model.
-
00:53:20 “How to write something that is different than Fastai library”
-
PAUSE
-
00:59:55 More into SGD with ‘lesson6-sgd.ipynb’ notebook, a Linear Regression problem with continuous outputs. ‘a*x+b’ & mean squared error (MSE) loss function with ‘y_hat’
-
01:02:55 Gradient Descent implemented in PyTorch, ‘loss.backward()’, ‘.grad.data.zero_()’ in ‘optim.sgd’ class
-
01:07:05 Gradient Descent with Numpy
-
01:09:15 RNNs with ‘lesson6-rnn.ipynb’ notebook with Nietzsche, Swiftkey post on smartphone keyboard powered by Neural Networks
-
01:12:05 a Basic NN with single hidden layer (rectangle, arrow, circle, triangle), by Jeremy,
Image CNN with single dense hidden layer. -
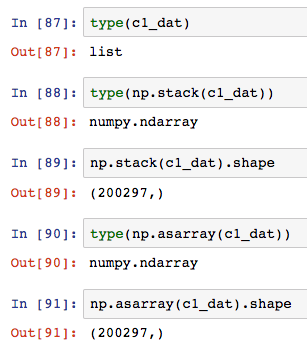
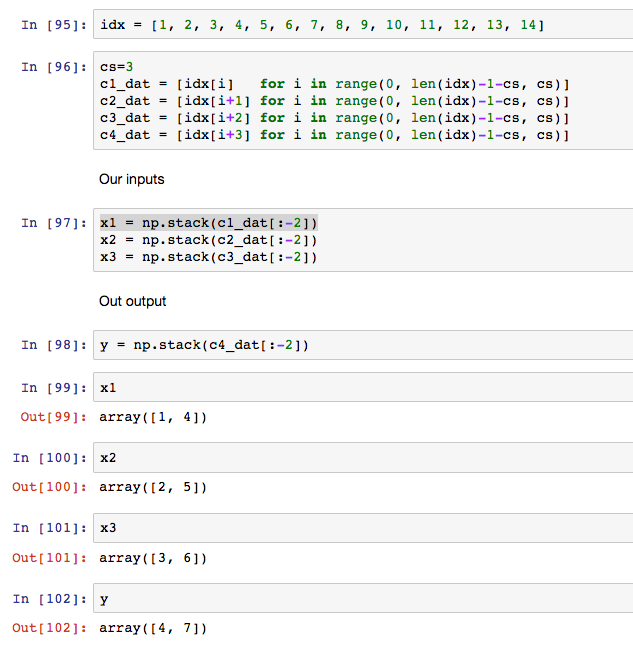
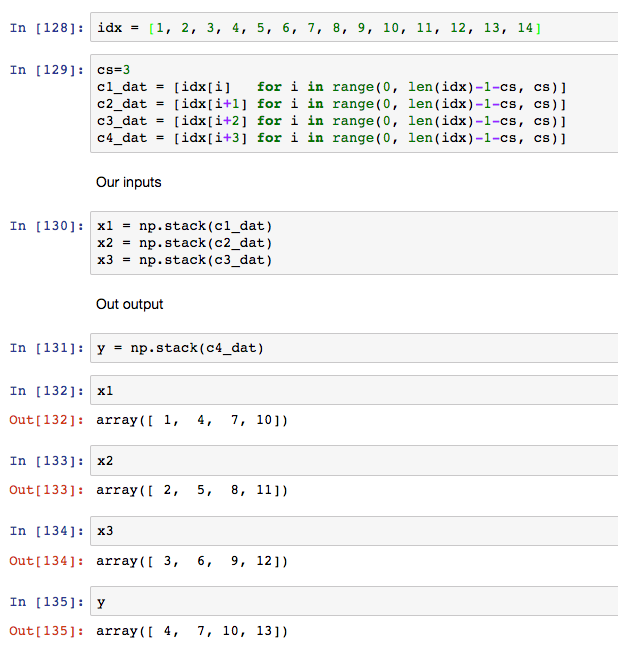
01:23:25 Three char model, question on ‘in1, in2, in3’ dimensions
-
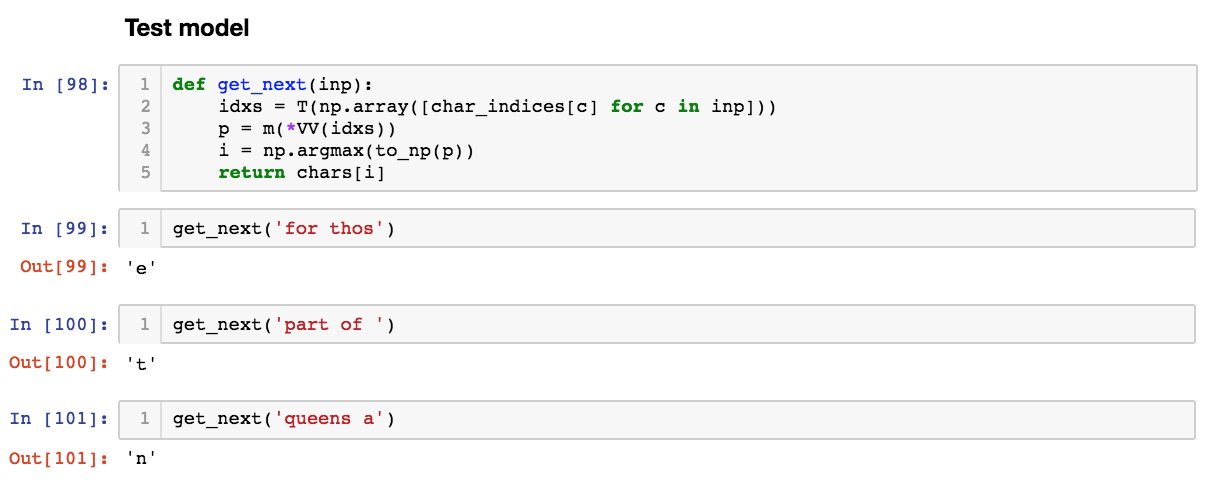
01:36:05 Test model with ‘get_next(inp)’,
Let’s create our first RNN, why use the same weight matrices ? -
01:48:45 RNN with PyTorch, question: “What the hidden state represents ?”
-
01:57:55 Multi-output model
-
02:05:55 Question on ‘sequence length vs batch size’
-
02:09:15 The Identity Matrix (init!), a paper from Geoffrey Hinton “A Simple Way to Initialize Recurrent Networks of Rectified Linear Units”



 Here’s the new stuff I learned:
Here’s the new stuff I learned: