I have a question regarding “unsupervised learning defined as fake tasks of supervised learning” which is strictly related to embeddings each categorical feature individually.
When you train an auto-encoder you have a very clear task which is reconstructing the original data thus it is supposed to be a good example of unsupervised learning without fake tasks. Augmentation is used for generalizing better e.g. denoising auto-encoders. Also the restriction of having smaller intermediate layers can be solved by using sparse auto-encoders or variational ones.
I see one advantage of auto-encoders is that we can have the middle layer (the code) as embedding of the whole datum. While it is obviously not efficient during inference because you need to feed-forward the first half of the network, it is a way to embed all of the numerical and categorical features in a single vector. This result would not be possible with standard entity embedding without going through one embedding layer for each feature before to mix them together? Wouldn’t it?
What advise do you have for using auto-encoders for embedding with respect to the matrix techniques taught in the course?
Seems that discussion in Lesson 6 is much lesser compare to other lesson? I have stuck in the last part and would really love some help…
I would love to ask what files are in the training path and validation path? i didn’t see any code in notebook try to produce these files. I did see in the lecture video there is a trn.txt in Jeremy’s directory. I have searched for quite a while and would love to know what is this file.
As earlier we create a validation set by doing get_cv_idx, I wonder how do we construct the validation set for the state model part with LanguageModelData.from_text_files(PATH, TEXT, **FILES, bs=bs, bptt=bptt, min_freq=3)
You probably got this before the post but for anyone else who finds his or her way here, just export the first 80% of nietzsche.txt as trn.txt in TRN_PATH and the last 20% as val.txt in VAL_PATH
Hey everyone, I have a problem with the ‘CharLoopConcatModel’ model from this lesson (I’ve been reimplementing it myself). Namely - it’s performance is a lot worse than the performance of the ‘addition’ model.
And I don’t really understand why. Especially given that if I literally copy the model code from the original notebook and paste it into my notebook and run it - it’s also experiencing the same performance problems. Which leads me to believe that problem may lay not in the model, but in the way I organize/preprocess data before. At the same time the ‘addition’ model and model that uses the nn.RNN layer perform ok (though not as well as in the original notebook)
I’d really appreciate the help with understanding where the problem lays.
As of pytorch 0.4.0, Variable is deprecated. Variable was merged into Tensor.
You can enable backprop or auto differentiation by set Tensor(data, requires_grad=True).
OK, so it looks to me like -1 is the right thing, given the tensor is torch.Size([8, 512, 85]), so that means it’s doing the softmax on the 85 features.
I guess my question is: how am I getting a smaller loss when using the wrong dimension? (And of course back to the original question, why aren’t we getting the original loss from when you recorded the video?)
details of how it works below:
If I use dim=0 or dim=None (the default value) it works gives these losses.
epoch trn_loss val_loss
0 1.11514 0.951215
1 0.833026 0.763225
2 0.709755 0.677634
3 0.644615 0.630919
torch.__version__
'0.3.1.post2'
Signature: F.log_softmax(input, dim=None, _stacklevel=3)
Source:
def log_softmax(input, dim=None, _stacklevel=3):
r"""Applies a softmax followed by a logarithm.
While mathematically equivalent to log(softmax(x)), doing these two
operations separately is slower, and numerically unstable. This function
uses an alternative formulation to compute the output and gradient correctly.
See :class:`~torch.nn.LogSoftmax` for more details.
Arguments:
input (Variable): input
dim (int): A dimension along which log_softmax will be computed.
"""
if dim is None:
dim = _get_softmax_dim('log_softmax', input.dim(), _stacklevel)
return torch._C._nn.log_softmax(input, dim)
File: ~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/functional.py
Type: function
And digging in to _get_softmax_dim it looks like it’s taking the our 3 dimensional input and returning a ‘0’.
def _get_softmax_dim(name, ndim, stacklevel):
warnings.warn("Implicit dimension choice for " + name + " has been deprecated. "
"Change the call to include dim=X as an argument.", stacklevel=stacklevel)
if ndim == 0 or ndim == 1 or ndim == 3:
return 0
else:
return 1
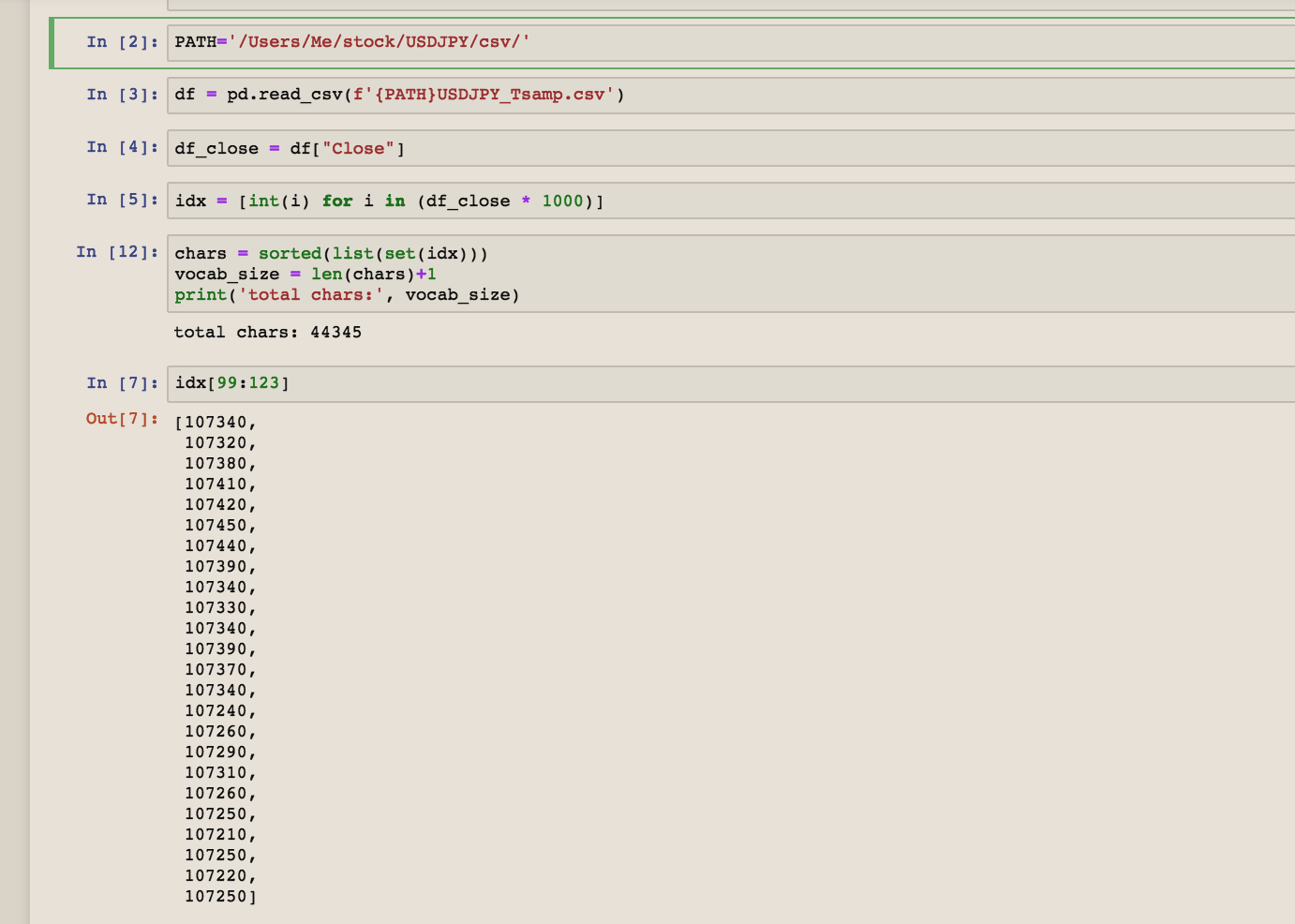
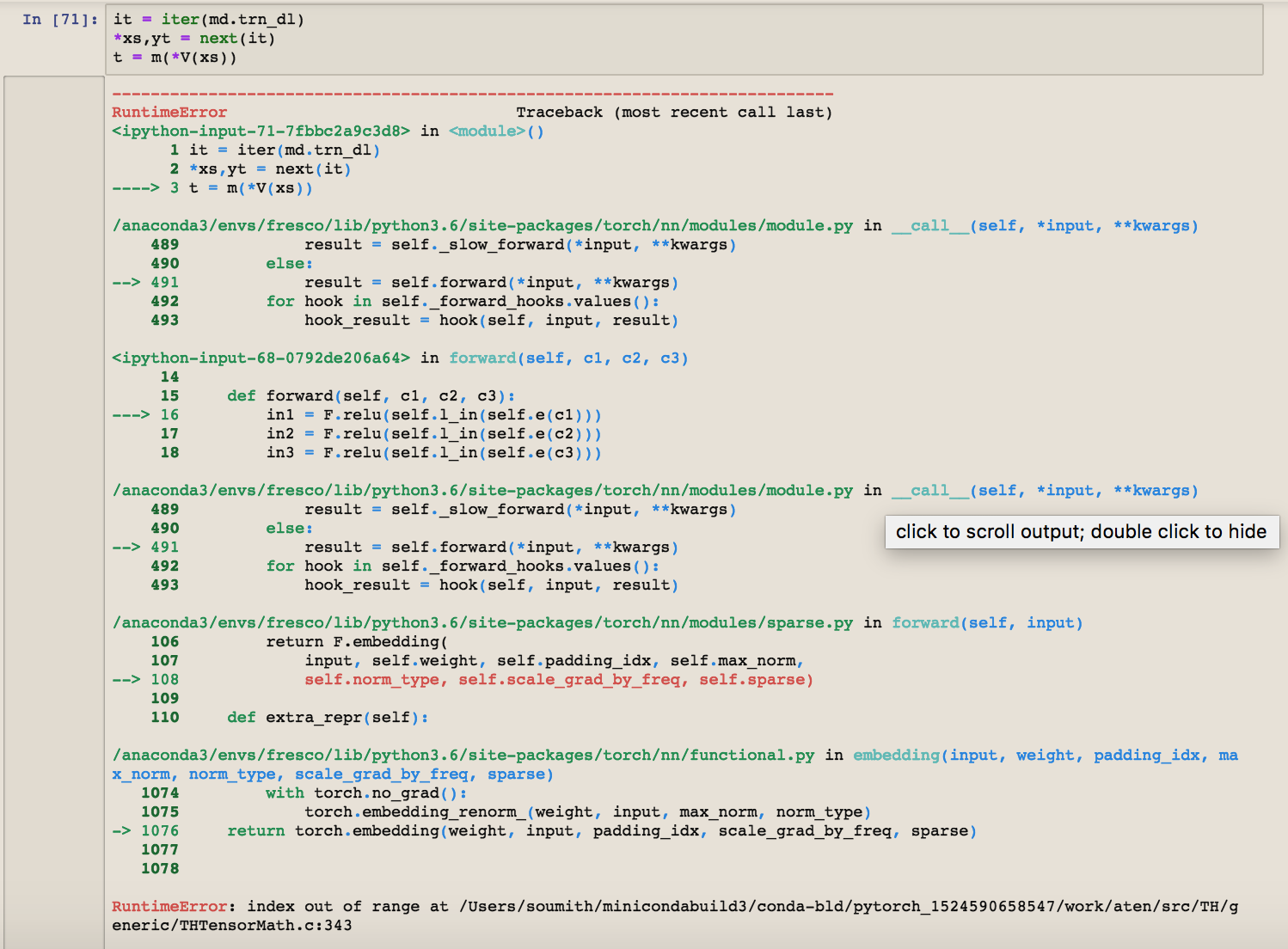
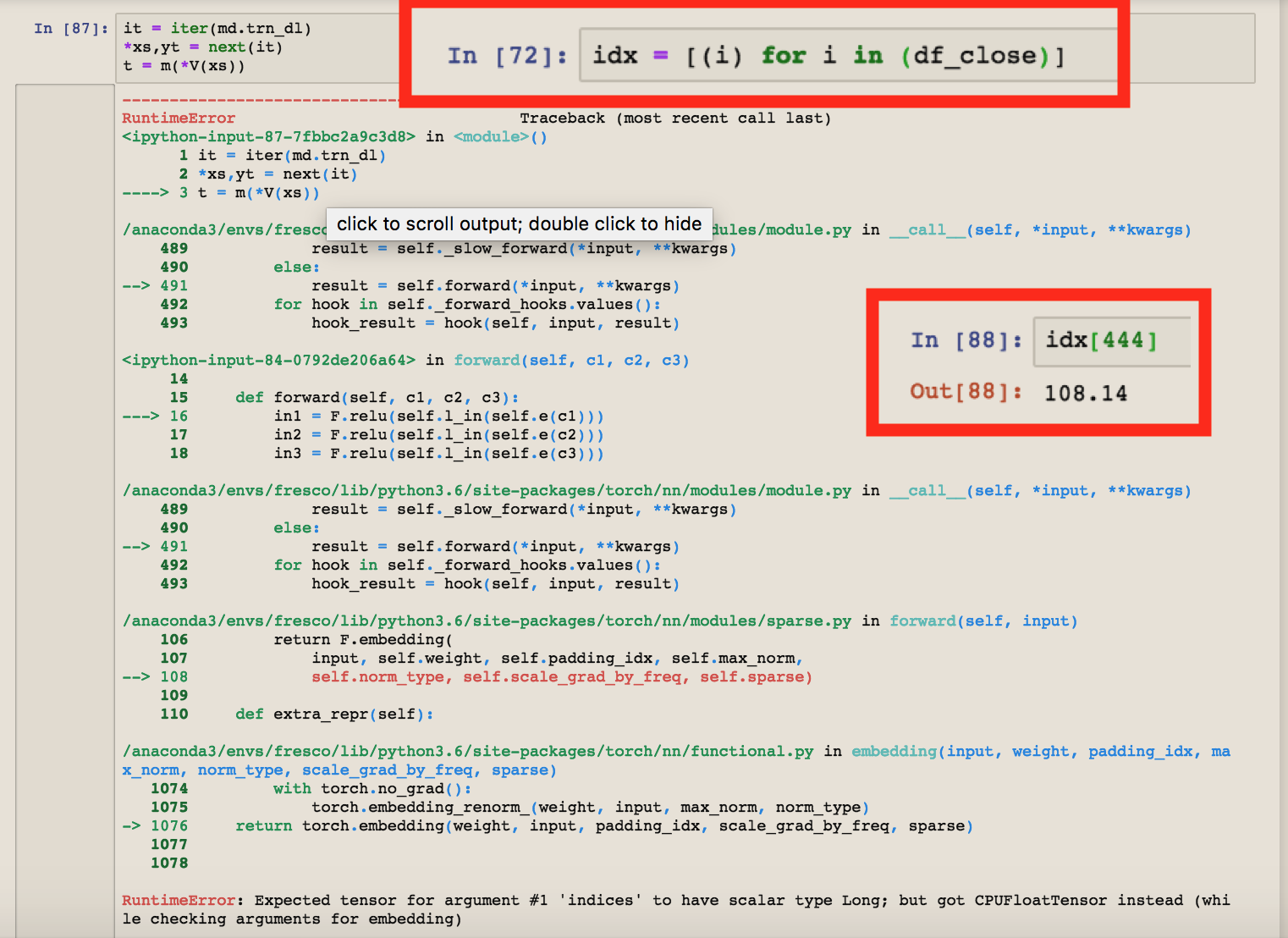
I tried modifying the lesson6-rnn notebook to take a sequence of Yen to Dollar price history instead of the Nietzsche text just to see what would happen, just to learn, and I’m getting two different errors depending how I try to pass in the sequence of numbers.
Changing the n_fac number to n_fac = 24733 returns this same out of range error.
If I leave the numbers as floats I get a ‘RuntimeError: Expected tensor for argument #1 ‘indices’ to have scalar type Long; but got CPUFloatTensor instead (while checking arguments for embedding)’.
I’ve tried converting out of this CPUFloatTensor and into something passable to know avail. I’m not clear on what exactly needs converting and how to do it. I mostly tried putting a ‘.long()’ on the end of everything.
Anyone think this second error here wouldn’t exist if I tried this on a GPU? I’m just using a CPU on a laptop. I know, not good. But the Nietzsche text to trained on the laptop pretty quickly.
This is regarding the CharLoopConcatModel class,
why are we still using self.l_hidden weights when we have already in a way assimilated in self.l_in.
ignoring self.e and self.l_out for now, Before we have 2 weight matrices l_hidden(size:(n_fac,n_hidden) ) and l_in(size:(n_hidden,n_hidden)) and we are using both of them to calculate the next hidden activations,
but in concat model , we have already essentially concatenated both of the previous l_hidden and l_in ,which if you do you will get a weight matrix of size :
inp = torch.cat((h, self.e( c )), 1)
inp = F.relu(self.l_in(inp))
perhaps we can do a tanh instead of relu here, but using l_hidden here again is not understood by me
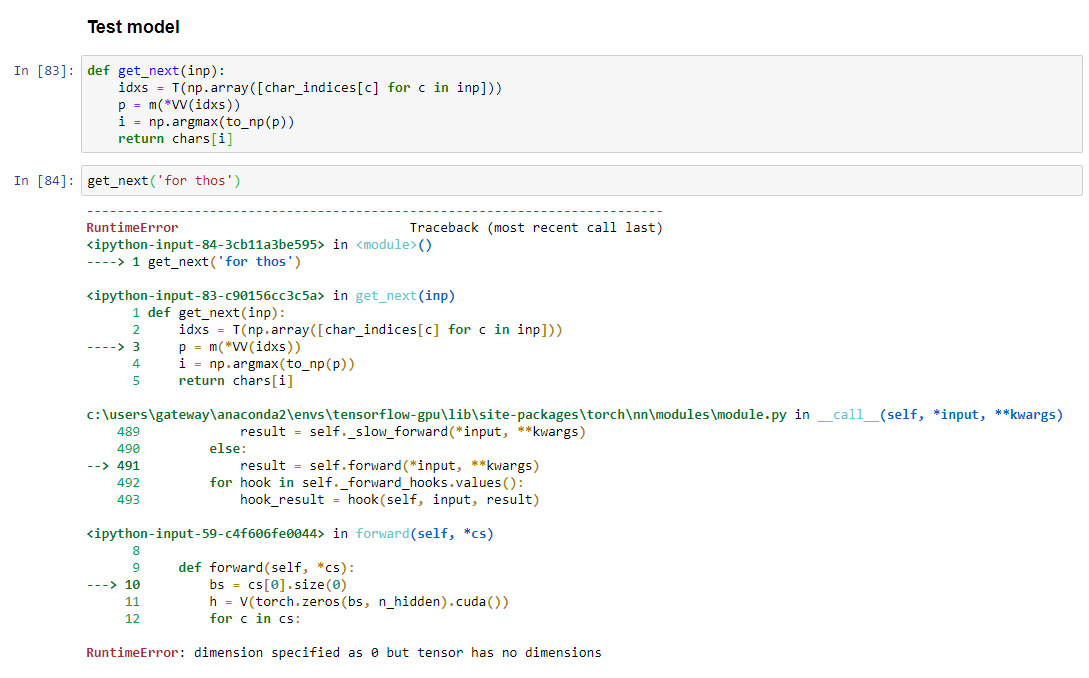
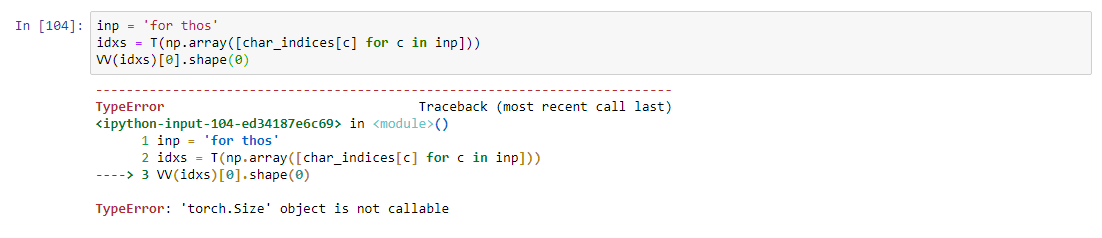
Ran into the following error on Lesson 6 RNN. It looks like the issue lies in whatever is passed to
bs = cs[0].size(0)
Using the get_next framework for prediction works fine with the previous models that don’t create a batch size from cs. Does anyone know the cause of this?
There is a slight misinterpretation of the term metric space at 30:00 for the embeddings in the Rossman competition. The points on the chart are the features, not the individual stores. The authors define a metric on the categorical fetures, which is a kind of averaging as defined in eq. (19) in their paper. The distances measured with this metric are shown on the x-axis.
It is pointed out that the metric defined above cannot be isometrically embedded in an Euclidean space such as the space of the embedding vectors. Nevertheless, there is apparently an upper and lower boundary, whose properties and existence is yet to be researched.
So in the first 20 minutes, the fastai video used the bias to see which was the worst and which was the best movie. Can someone explain why they used the bias? I thought it was just an extra vector for optimization but apparently we can use it to find the best movie?
Also at around the 30 minute mark, Jeremy talks about how the researchers got an interesting correlation by comparing how far away they were from each other and how far away they were on the embeddings. How exactly do you plot an embedding vector and what does it mean?
Also what does it mean to plot how far away they are on embeddings?