Nice project! Can you please share your notebook / kaggle kernels / github repository for this work?
@NathanHub and I recently participated in the Freesound Audio Tagging 2019 Kaggle Competition and received our first bronze medal (95/880).
We used FastAI and XResNet in our model. I’ve written up a more complete description here: https://joshvarty.com/2019/07/23/freesound-audio-tagging-2019/
Our repository with notebooks: https://github.com/JoshVarty/AudioTagging
10 Likes
Fastai Active Learning
tl;dr First attempt at active learning for fastai library. Includes random, softmax, and Monte Carlo Dropout std calculations to measure the uncertainty of an example for a machine learning model.
I recently came across a paper called BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning and the following blog which was a segway to explore active learning.
I thought it would be cool to have active learning as a part of the fastai library. I am not an expert on active learning but thought it would be a great way to learn about the field and different algorithms. P2 of the fastai lessons has been very helpfuf in implementing the gist.
The implementation separates the uncertainty measurement from the active learning selection process. There are two options for selection:
- Select x most uncertain examples from the entire dataset
- Select x most uncertain across all batches in dataset.
I hope to continue working on the gist and fully implement different papers. If anyone wants to contribute or finds bugs feel free to pm me.
Shout out to @mrdbourke for implementing Monte Carlo Dropout in fastai.
7 Likes
Hi everyone,
I’m happy to present v1 of a comprehensive intro tutorial to geospatial deep learning (focused on building segmentation from drone imagery in Zanzibar) using fastai v1, the latest cloud-native geodata processing tools, and running fully self-contained on Google Colab for ease of learning (and free GPUs!):
Announcement:
Conceptual overview:
Colab notebook (previewed in nbviewer):
https://nbviewer.jupyter.org/github/daveluo/zanzibar-aerial-mapping/blob/master/geo_fastai_tutorial01_public_v1.ipynb
More info & highlights over on the geospatial deep learning thread: Geospatial Deep Learning resources & study group
Given there’s a lot covered here, I’m sure that I missed many things (bugs, mis-assumed knowledge, janky code, bad links). I appreciate any and all of your feedback to make the next versions of this tutorial (and next ones) even better so thank you in advance!
Dave
20 Likes
I watched the Part 1 video last year, with fastai v0.7, and just i was amazed to see how much better fastai performs in comparison to other deep learning libraries. I then wondered how would it perform against itself, and needless to say, the library did not let me down. I found a paper written by one of my college senior in early 2019, using a thermal image dataset. At the time, they got a best case accuracy of 97.08% and a validation loss of 11% using resnet101 and fastai v0.7.1, which was achieved after multiple parameter modifications and model tuning.
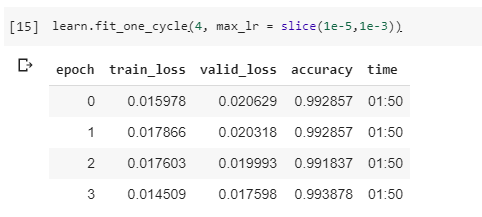
In July, 2019, I present, fastai v1.0, resnet50 and 10 minutes of coding:
Model Accuracy: 99.38%
Training Loss: 1.4%
Validation Loss: 1.7%
Original Paper: https://www.sciencedirect.com/science/article/pii/S1319157818312837
My respect to fastai - destroyer of scientific papers (RIP) since 2017
Cheers,
Wonderful project!
What did you use to develop/deploy your webapp? I made something very similar with Flask and was just curious as to what you used.
Cheers!
Hello everyone
I recently wrote a medium article on building an Image Similarity search model using Fastai, Pytorch Hooks and Spotify’s Annoy.
Results of this project was simply outstanding and I was blown away by how easily we can implement this.
Here is one base image for which we need to find similar images:

and the model returned following images which it thought are similar to the base image:

Please read through the article wherein I posted the link for Kaggle Kernel as well.
BR
Abhik
7 Likes
After taking the first two class of part 2 of 2019, I was able to get how autograd works and how it was used in pytorch. And to be sure I grasp the concept, I created a simple autograd in javascript and also create a pytorch like implementation in javascript.
It was implemented in obsevablehq js interactive notebookhere
and also you can help me check this medium post draft explaining the basic concept here
Thanks, fastai and the whole family
2 Likes
Thanks! It’s a Starlette app that I deployed to Render.


1 Like
Hi everyone, after complete the lesson 1 I have create my own dataset to predict the Felidae. You could find the blog from my personal website.
1 Like
For my last Part 1 mini-project I decided to have a go using the tabular learner to predict Fantasy Premier League player scores. I’ve written a blog about it! https://medium.com/@sol.paul/how-to-win-at-fantasy-premier-league-using-data-part-1-forecasting-with-deep-learning.
Spending some time applying the approach really helped me understand the concepts more deeply, although I’m still not sure I fully understand how the time series aspect works with regards to trend. I noticed that in the Rossmann notebook there are no ‘recent trend’ type variables i.e. something that describes the days and weeks leading up to each observation. Of course, this information is still there in the other observations, so I’m guessing that the ‘date’ (day, month, year) embeddings encompass this in the network e.g. October’s embedding encodes in some way that September is ‘nearby’, meaning that the model can account for recent trend (assuming it is predictive).
Loved the first part of the course so going onto part 2 now!
1 Like
Created a web app and deployed to Heroku. Despite an okay confusion matrix (see the notebook), the model often gets confused (try images from the homepage, which are in the training set, or Google). Need a bigger dataset?
1 Like
@nkaretnikov how many images did you have in total?
Hi,
I wrote a blog post on using fastai text as the classifier in the rasa chatbot framework. I would love any feedback. Thanks!
4 Likes
210 images. Here’s the dataset:
(I wanted to get started quickly, so I essentially picked one that’s good enough.)
Hi everyone! I just started ths course and I’m super pumped!
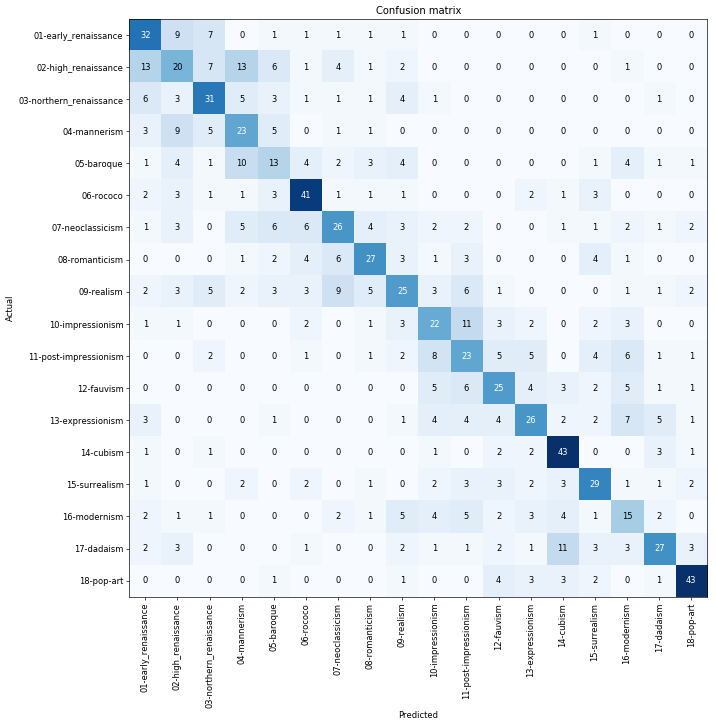
Following the suggested practice for lesson 1, I built a classifier of paintings into their art period. I used 300 google image search results for each of the 18 classes. My model has ~50% accuracy. I am not entirely sure how good this is so I would appreciate any hints or insights into the work.
The blog post is in https://fedebarabas.github.io/projects/paintings/ and the jupyter notebook is in here.
Thanks fastai and the whole community!
1 Like
Hi @henripal,
I’ve just finished part 1 of the 2019 course and I am going through your web app to better understand how the different pieces work.
Any reason why you chose to use Go as the backend language?
Hi @champs.jaideep,
I took a look at your kernel and studied the paper. From what I understand, Arcface loss might be applicable to problems other than computer vision.
Does replacing Linear layers from other models (a text classifier for exmaple) with ArcMarginProduct make sense?
What do you think?
well i havent tried on the models other than the classification model. It produced fantastic results for kaggle whale identification form hump back which had 5000 classes plus. You are welcome to try it out for other models.Arc face is also useful for face detection by learning deep features.