Hey all,
Made a little app referring to fastai bear classifier, mine is pigeon species classifier wherein the trained model identifies the species of the pigeon analyzing the picture. Error rate is too high (30-33%), training sample was too less, still working on gathering more data and covering maximum species. Taking a look at the data, clearly there are species looking too similar to each other, just different names, hope more data will increase the accuracy…none the less…got to learn a good deal building the app. Please take a look here …excuse the typo.
3 Likes
We now have a way to evaluate the model on a new dataset.
@quan.tran implemented single data point prediction.
Have a look at predict_one_item here
2 Likes
hi all,
I started fast.ai course recently and I love it. Since I’m an iOS developer and I develop mainly in Swift I decided to do some extra work. Here is gradient descent (taken from Deep Learning 2019 Lesson 2), implemented in Swift for TensorFlow for simple linear regression https://gist.github.com/jkrukowski/882d19091756881604a428b45560a761
Any feedback is welcome, thanks!
1 Like
Hi, if I remember correctly the problem is not with evaluating one row of data (if I understood your code well and that’s what predict_one_item do  ), we can do it with, for ex.
), we can do it with, for ex. learner.predict() method, but it works very slowly if we try to predict with it one by one a set (1000+ records) of new data. That what I was trying to achieve in my functions (I needed this for implementing partial dependency, feature importance and other similar things).
Now there is a way to predict batch with .get_preds() and some hackery with substituting test set with new data. But I had some misconsistencies when I was trying this approach.
That’s a really nice project, and thanks for the acknowledgement! I don’t know if you tried this before but training different models (xgboost, NN) and stacking them can also help boost the performance, but I guess it would complicate the deployment process…
1 Like
I was also thinking of assigning new data as test set + call get_preds() for evaluating new dataset, but you already investigated this. I sometimes got inconsistent result from pred_batch and get_preds too. I will take a look at what you have in the other thread for some experiments.
1 Like
Nice! In Part 2 of the course, most of the fastai library is re-implemented in S4TF. Luckily, you won’t have to worry about learning Swift! 
1 Like
I trained a classifier to discriminate between Chanterelle mushrooms and Jack-o-Lantern mushrooms to 85% accuracy.
Chanterelles are delicious. Jack-o-Lanterns are poisonous!
Great course, thank you for all of it
1 Like
@quan.tran @joshfp FYI the article just got featured in Towards Data Science:
3 Likes
Using Google Images, I created a dataset of handguns, namely glock, revolver and desert eagle. I trained a classifier and it got 96% accuracy!
Here is the link:
Handgun classification
Excellent job, I have been thinking of doing a regression example with a Dataset I could understand easily, it’s a perfect example.
Many Thanks mrfabulous1 
I’ve taken Lesson 3 CamVID image segmentation, and Planet’s image classification lesson, to create an image segmentation to detect building footprints from satellite images.
There is a lot of training data (tens of Gb of high-resolution images) from the Spacenet competition, but mostly I wanted to do one project on my own, so I took ~6k chips of images in Rio de Janeiro.
The hardest part was to convert the .geojson footprints into images (I used parallel rio rasterize), and then fiddle to avoid running out of memory. Overall I’m quite happy, here is the notebook, and the results:
left ground truth, right prediction.

7 Likes
I tried this code and it works for training with .fit_one_cycle(). However, when I try to run the learner in .get_preds() mode, the callback is not being run for some reason. Is there a way to make it run in prediction mode, and not only for training?
Update: I am trying to collect predictions for a pre-trained model, so I am avoiding changing weight, this is why I am using .get_preds(). Would using .fit_one_cycle() with learning rate of zero effectively achieve the same result?
.get_preds() expects an argument of what you want to get predictions for. Are you passing it a data object?
Yes, I am passing data.train_ds to .get_preds(). The problem is that the callbacks are not working as I would expect with .get_preds() as opposed to working well with .fit_one_cycle(). For now what I am doing is setting learning rate to zero and using .fit_one_cycle() to record activations without training the network.
Hello everyone
I recently wrote a medium article on the integration of Fastai with BERT (huggingface’s pretrained pytorch models for NLP) on a multi-label text classification task. After that I compared the performances of BERT and ULMFiT.
Here are few things which I did to integrate Fastai with BERT:
- Using BERT’s tokens and vocab
- Some modifications in BERT’s tokens for eos and bos parts
- Splitting the model for discriminative learning techniques
Here is the link:
I was amazed by the level of accuracy using just 2 epochs:
- BERT - 98% accuracy
- ULMFiT - 97% accuracy
I would be glad if you have any feedbacks or comments on this.
BR
Abhik
10 Likes
Copy of the post from Share your work here (Part 2) :
Hi there!
Check out my recent blog post explaining the details of One-Cycle-Policy (fastai’s famous method .fit_one_cycle() ): The 1-Cycle-Policy: an experiment that vanished the struggle in training of Neural Nets.
Efforts have been made to make the entire things as simple as possible, especially explaining the codes. Hope you will enjoy it 
very cool! well done! A great test would be to see how it works with hurling
Hi everyone, from lesson-2 concepts, i created an emotion classifier, which jeremy talks about in the video.
Just by changing the wight decay, i was able to get around 66% accuracy, and the top values as jeremy says in the video are around 65.7%.
As i am using google colab i am not able to clean the dataset using the data cleaner,3rd party app, but still was able to get a pretty good accuracy.
Is there any other ways to clean the dataset which is supported by google colab?
Thanks,
Ajay
What Programming Language Is It?
Programming Language Classifier
After watching lessons 1-4, I decided to make a web app that classifies text according to the programming language. I searched the web, but couldn’t find much research on this topic. There was one example (https://arxiv.org/pdf/1809.07945.pdf) that uses a Multinomial Naive Bayes (MNB) classifier to achieve 75% accuracy, which is higher than that with Programming Languages Identification (PLI–a proprietary online classifier of snippets) whose accuracy is only 55.5%.
I was able to reach about 81% accuracy(according to fastai) (although I’m not sure I’m measuring it the same way as the paper) after following the same basic steps as the IMDB example. This was done with the dataset I found from the author of the paper, here: https://github.com/Kamel773/SourceCodeClassification. I noticed that the dataset is pretty messy and a lot of the css/html/javascript is misclassified as another one in that group. That is apparent in the confusion matrix:
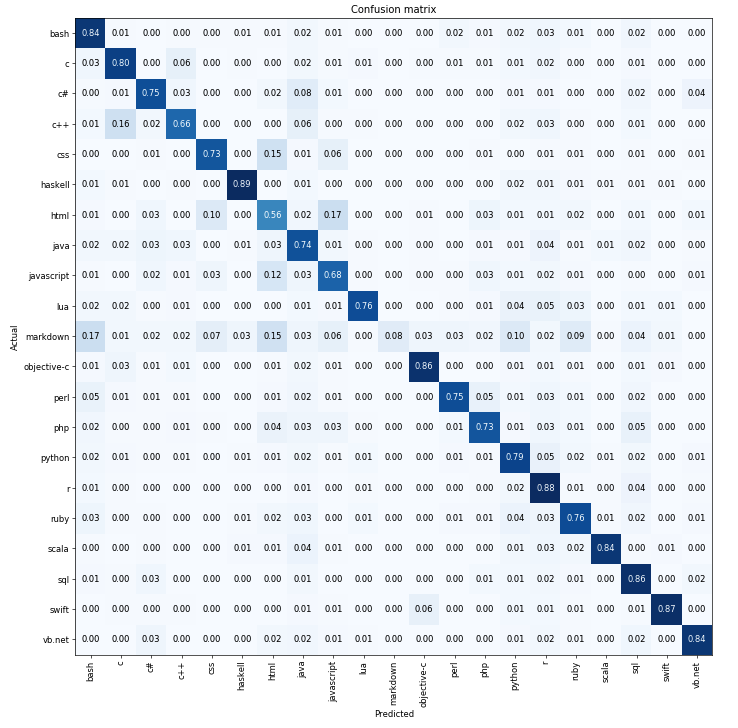
But, regardless, I made a web app, which is currently here: https://programming-language-classifier.onrender.com. It lets you paste in a snippet of code and it will tell you what language it thinks it is. Give it a try and see if you can confuse it! I created the web app based on the template here: https://github.com/render-examples/fastai-v3.
I did find another data set of classified code on Kaggle, which is way bigger (called “lots of code”) (and hopefully has less misclassifications) that I am going to try to use to improve the accuracy even further.
I am having way too much fun with this course. Thanks everyone!
11 Likes