Just saw the sample pictures of the panda on your github notebook. It all has the face in it - and we know that the two black patches around its eyes is a distinctive feature ( at least for the human eye )
Here’s an easy way to check if it is over fitting. My 2 cents
Collect all pictures of panda ( not just its face ) , take the back side –
Test your model on these images
See which all panda pictures it fails ( but you are sure they are panda )
Add these into your training set ( as label = panda )
Repeat . This will make your model more robust and generalized.
eg: This is also panda ( even if does not show its face )
on a lighter note ,
panda + panda = python library.
Hey everyone,
I am a French architect and I just finished the first lesson of Fast.ai. Can’t hide that I’m very excited about this course! The material is great the community seems very positive and creative.
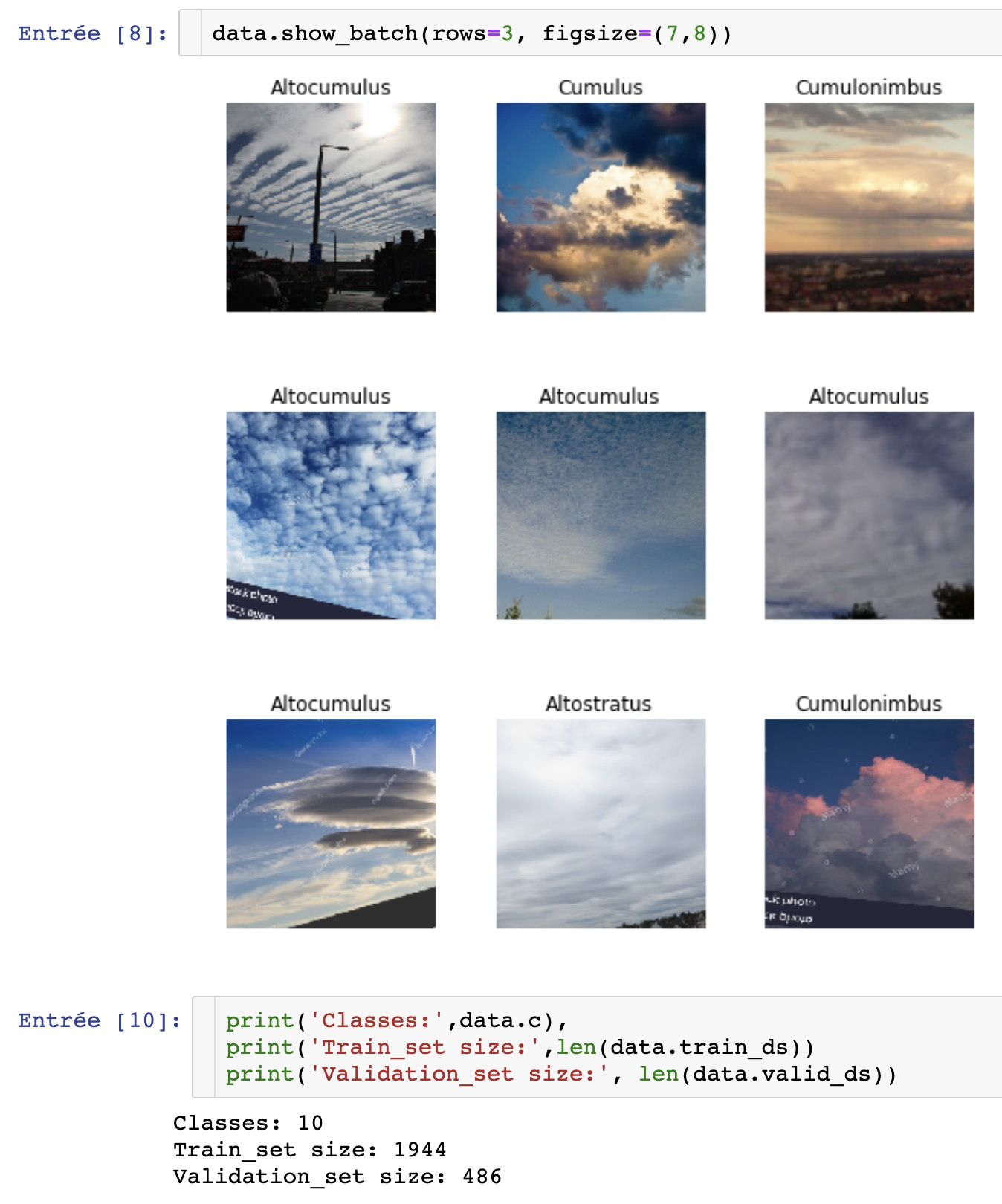
So for my first project I tried to train Resnet34 to recognise the different types of clouds.
Yes, .35 of error_rate is very far from the .04 in lesson 1.
My model not good at all to recognise clouds !
Here are my guesses for the reasons of this poor results:
It’s all in the Dataset building : Even searching for very specific types of clouds in google image often gave me results with other types of clouds.
So much that I decided to gather large quantities of urls for each types and then use python to remove automatically all urls not containing the specific name of the cloud. Which reduced largely the size of the dataset.
For example, the “Cumulus” name is often poorly used to name whatever could is in the picture so the dataset for this type might have been particularly noisy.
AI need human! : I am a human that cannot help the model when an image is poorly labeled because I can’t differentiate clouds So for the data cleaning widget I could only filter images that were not clouds.
So maybe I’ll restart from scratch my dataset with another gathering method. Maybe there is out there a good dataset for this task.
To cheer me up I went to Kaggle to play with one of their datasets.
I took the HAM10000 skin cancers dataset
I train the Resnet50 model to recognise the type diagnostic categories:
Actinic keratoses and intraepithelial carcinoma / Bowen’s disease (akiec),
Basal cell carcinoma (bcc)
Benign keratosis-like lesions
Dermatofibroma (df)
Melanoma (mel)
Melanocytic nevi (nv)
Vascular lesions (vasc).
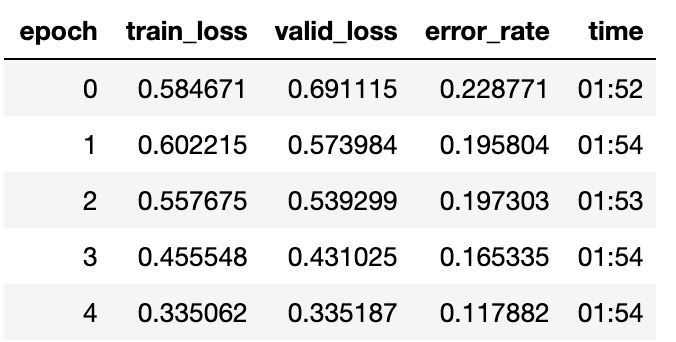
And got some pretty good results:
No far from the best kernel I found achieving .89 precision
And I was mainly training Resnet50 with the default parameters, I just played a little bit with the LR after unfreeze.
So the Fast.ai is indeed very powerful!
Thanks a lot to the team!
TL:DR
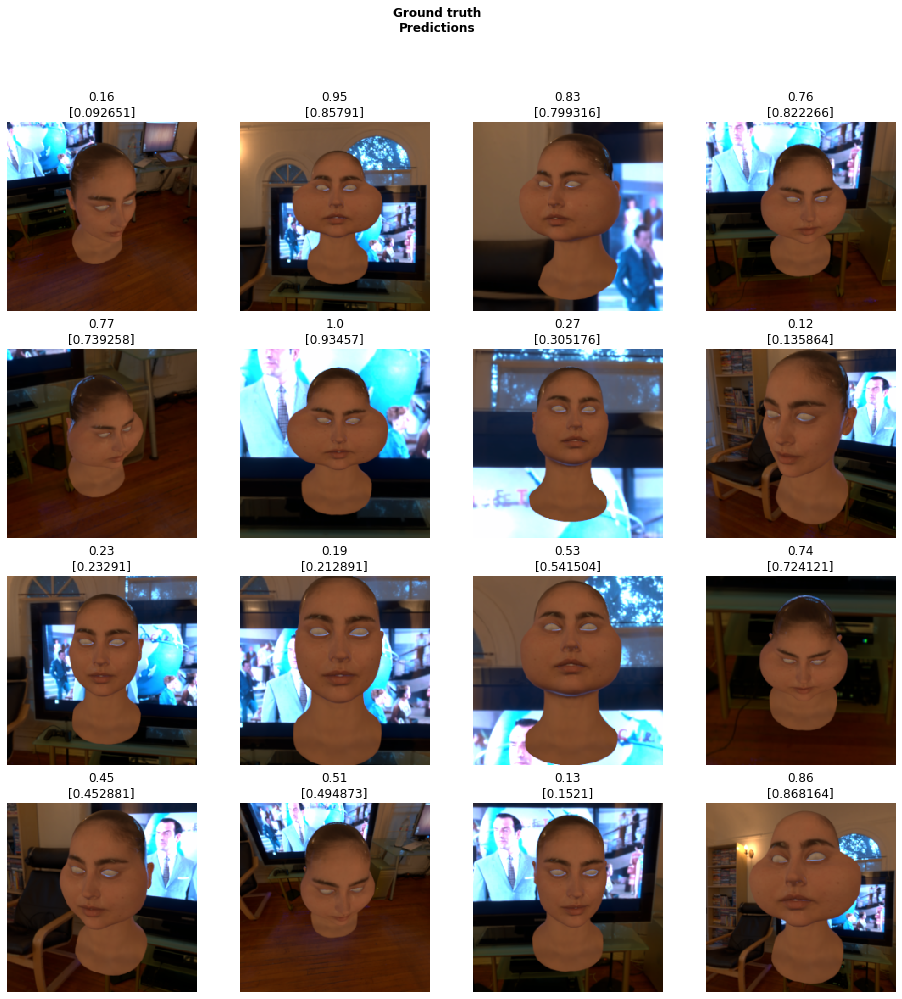
Blender randomises shapekeys -> renders to a np.array -> creates a list of floats for shapekey values -> passes to a panda dataframe (optionally pickles) -> passes to FastAI for a simple resnet50 MSELossFlat as sum
What features would you like to see in blender?
Hey guys, ZoVoS here,
This is just a quick Request For Comments on what I have been working on for the last few days.
So I wrote a little python to integrate FastAI into my Blender install so I can train networks based on renders without program hopping. Currently they are only designed to regress data for shape key predictions, I estimate if I use enough HDRI backdrops and varied textures it should generalise to the real world.
I have only been looking into the topic for a week or 2 so I’m only up to video 8, I’ll save an in depth post until I’m done as I have no doubt there is tons left to learn. Just looking for comments or any tips that people think would benefit the test project
Currently I’m using a simple resnet50, eventually I’ll need some form of U to estimate the textures.
Before I clean up the code and make it fit for human consumption, I was wondering if you were to see FastAI incorporated into blender what features would you want access to?
I’m thinking with blender I should be able to calculate pose estimation if I feed the http://mocap.cs.cmu.edu/ data set into it and render it to a puppet using the bone rotations as training labels.
Also I should be able to knock up some form of single/parallax camera depth calculator using blender depth data in the alpha channel.
Anyhoo all comments are welcome. Thanks for your time.
So created an image recognition model using my friends and mine images(5 labels). I took 25 images from each of them and used it to train the model and achieved an accuracy of 87%. Can’t share the images of them but I do share my github repo link.
The input folder in kaggle is read-only. Fastai stores some files about the model you’re using. Easy fix:
When creating the learner, tell it to store the model information somewhere else.
When calling cnn_learner, use this as an additional argument:
model_dir=’/tmp’
Hey guys! Excited to finally be able to contribute my piece here. Over the next few weeks I’m trying to really dig into the Fast.AI curriculum from all angles, and so as Jeremy and Rachel recommend, I’ve started a blog where I will be keeping track of what I learn, the challenges I face, etc. Currently this will include the new Part 2, the Matrix Calculus course, and the Linear Algebra course, and will include the NLP course once it is released. Let me know your thoughts on it when I get further along (I just made this and have never done a blog before)
Hey guys, working on getting all of my articles written I need to, but here is one I’m most proud of! For a competition at my university, I utilized ULM-FiT to help people navigate trustworthy articles, which won us first place! I know that the metric could be improved greatly, I have not had the time to revisit it with fresh ideas, but I plan to do so after the summer. Let me know your thoughts!
Hey everybody!
Just published an article about my work in reply.ai the last couple of months.
We extended fast.ai’s implementation of ULMFiT to take additional categorical and continuous metadata into account. This would not have been possible without the awesome work of @quan.tran and @joshfp !
I took a bit of a detour after lesson 4 in an effort to gather Twitter data for an NLP project relating to bitcoin. While this isn’t technically related to the course, I think a lot of the data scraping techniques can be used for a variety of domains. As a current CS student at Penn, a lot of my CS work is very theory oriented so I forgot how much I love to code and work on exciting projects from the ground up. Hope you enjoy the article and message me if you’d be interested getting access to the database. Also, if you’d like tweets relating to a different keyword and didn’t want to recreate the project I’d be happy to scrape them for you for the cost of the servers (~$1 per 10 million tweets).
Hey all,
Made a little app referring to fastai bear classifier, mine is pigeon species classifier wherein the trained model identifies the species of the pigeon analyzing the picture. Error rate is too high (30-33%), training sample was too less, still working on gathering more data and covering maximum species. Taking a look at the data, clearly there are species looking too similar to each other, just different names, hope more data will increase the accuracy…none the less…got to learn a good deal building the app. Please take a look here …excuse the typo.


 I think at this point It would have been far quicker to learn it myself! ( minus the fun of trainning a CNN)
I think at this point It would have been far quicker to learn it myself! ( minus the fun of trainning a CNN)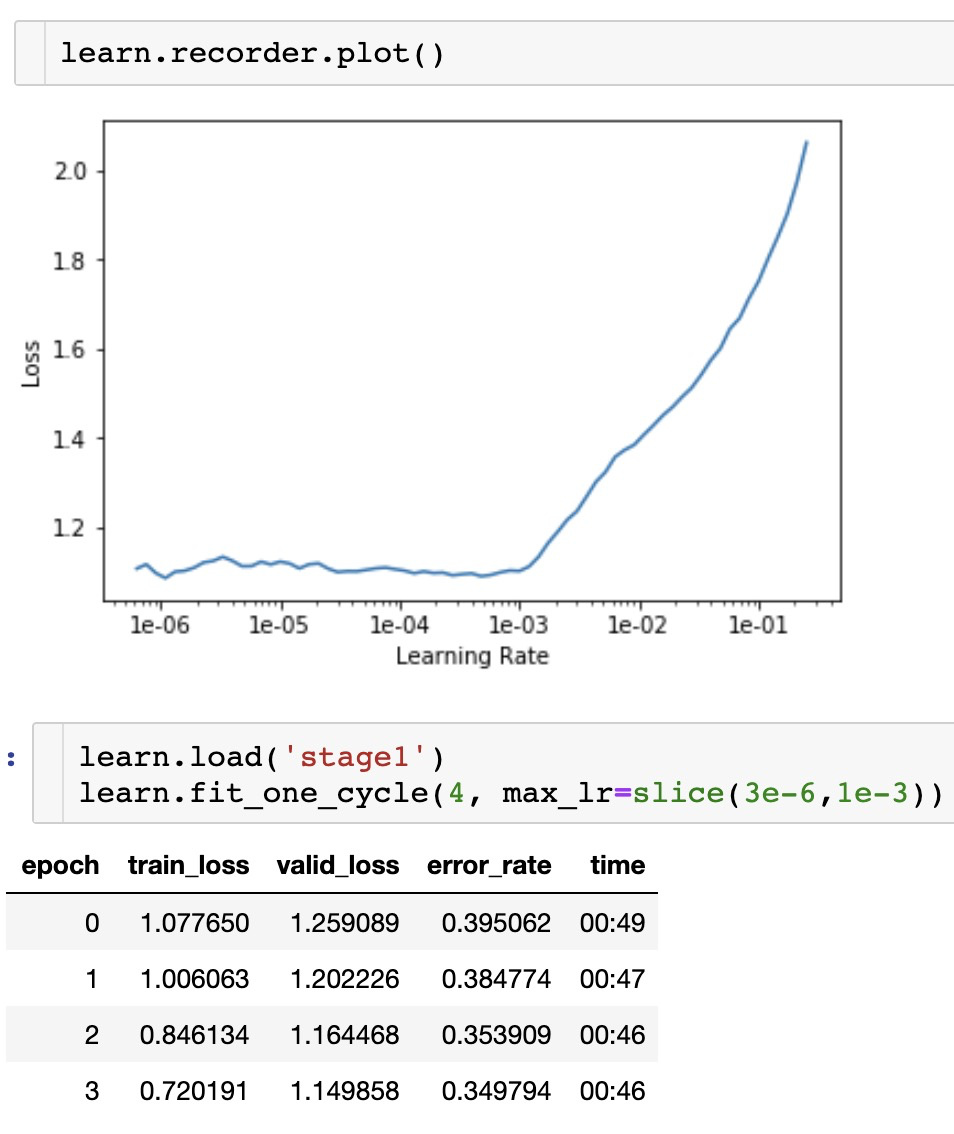

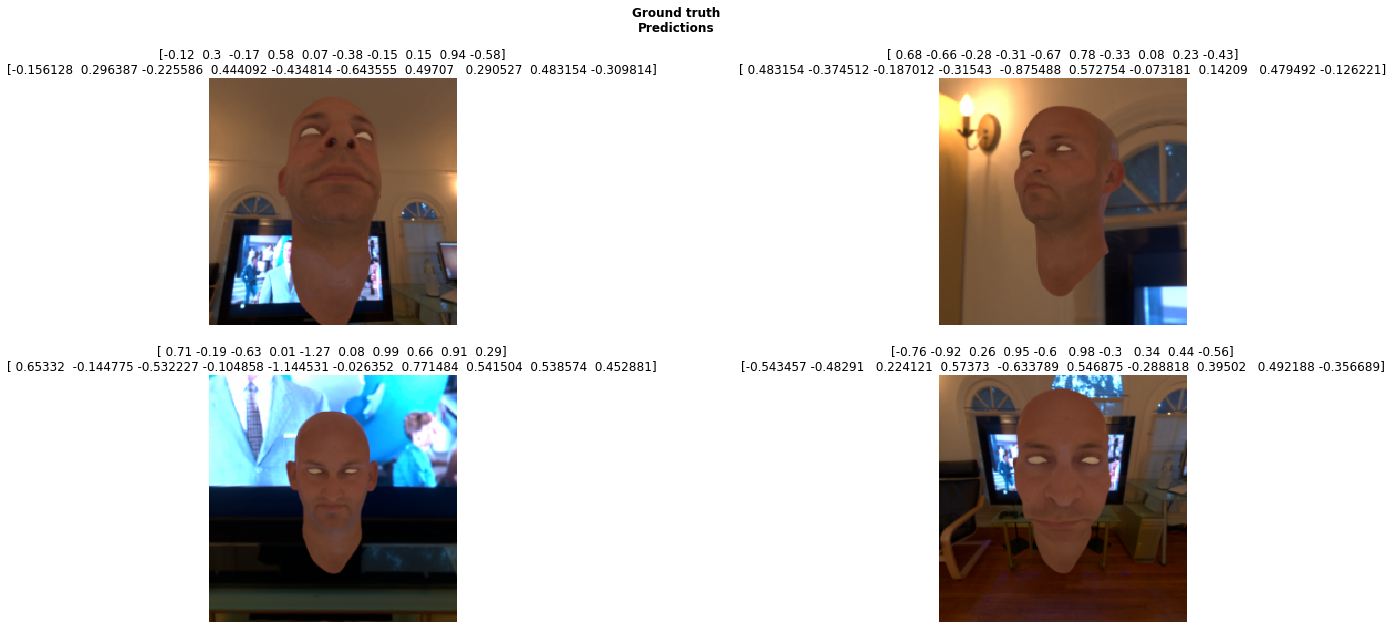
 Let me dive into these !
Let me dive into these !