Great work! Especially the “multi_cross_entropy” loss approach.
Hey everyone, this work is a continuation of the suggested practice given in Lesson 1 for downloading images and running classifier. I have created a dataset in Kaggle - Martial_Arts_Classification and the kernel link is - https://www.kaggle.com/nanda1331/using-fastai. Please give some reviews for the kernel and the dataset. If you like the kernel and the dataset please upvote them as well.
1 Like
Thanks! Unfortunately that approach wasn’t very effective…
1 Like
Good job  I’ve run into something interesting. Think your model may also predict based on something else than facial features, because my linkedin photo was rated as 37 years old and my casual photo as 24 years old, me with makeup and dressed mmore partyish 30 years old (the actual truth). Have you tried training it on same people in different setting or possibly same people at different ages?
I’ve run into something interesting. Think your model may also predict based on something else than facial features, because my linkedin photo was rated as 37 years old and my casual photo as 24 years old, me with makeup and dressed mmore partyish 30 years old (the actual truth). Have you tried training it on same people in different setting or possibly same people at different ages?
1 Like
I haven’t had a chance to look at this in a while but yeah you are right there are a lot of ways to improve it.
1 Like
Want to do fancy Data Sciencing with Twitter data?
I created an interactive Google Colab that walks you through an end-to-end analysis of what’s trending on a selected Topic. Colab is an awesome (and very under used) tool and its Form feature lets you create a great UX experience similar to an App while giving the option to dig deeper into the underlying code.
I use Seattle as my example in the notebook but it is setup to be used for any topic. You can scrape twitter data, parse out tags (NER), do sentiment analysis, and visualize all that good stuff with plots and Word Clouds.
Link to notebook: https://lnkd.in/ghKzQV4
What a shame! btw it’s an interesting idea and a good starting point for new experiments.
Hey everyone,
I wanted to share 2 Medium articles I wrote. The first one I created after lecture 1 and attempts to predict whether the stock market will move up or down.
The second article follows from lecture 4 where I use embeddings for the Store Item Demand Forecasting kaggle competition.
4 Likes
So after lesson 3 and some trouble working with the data, I created a landmark detection model for cat facial features using this cat dataset from kaggle. And I am pretty satisfied with my work, guess I could do better, but I think I must move on with the lessons haha
I would like to take this opportunity and point out some things that I came across along the way:
-
Applying any kind of transform worsened the performance of my model by quite a lot. I guess that makes some sense since when you are taking the picture of cat you are mostly putting its face on the center of the picture, so rotating and mirroring shouldn’t improve.
I have my doubts about this hypothesis, and is something I might try to understand further later. -
Basically running more epochs did a lot of the trick, but not too much. Very few (less than 15) my model ended really bad, but a lot (More than 30) made things worse. There was a lot of trying and error
Anyway, here is the repo with the notebook:
Thanks!
2 Likes
92.77!!! Acc on stanford car dataset with resnet152 with
progressive resizing 448 sizes
1 Like
Really enjoyed the image recognition article, an interesting approach to stock prediction
I assembled 1965 images of company’s logos and info from the Russell 2000 stock index and put in 6 classes based on how well the stock did.
I used notebook 1, lesson 1. It overfit horribly but sharing anyway just because it took so long to build the dataset (maybe somebody will offer me a job based on my scraping and dataset building skills - (I’m a full stack MERN dev as well)) …AND I still think there is something correlated to executive names, company names, and logos and the company’s success. Maybe I could try putting the 1965 companies in different classes and try different models, but I don’t feel like sinking anymore time into this project right now. Maybe there is something obviously wrong with it you can spot. Now wondering if the images were ‘RGBA’ but should be ‘RGB’ or there is a technical hang up keeping it from training properly.
Tried sorting into classes by profit margin as well. Overfit again.
Maybe I need a different sort of model.
The Resnet models overfit pretty quickly.

Hi Everyone,
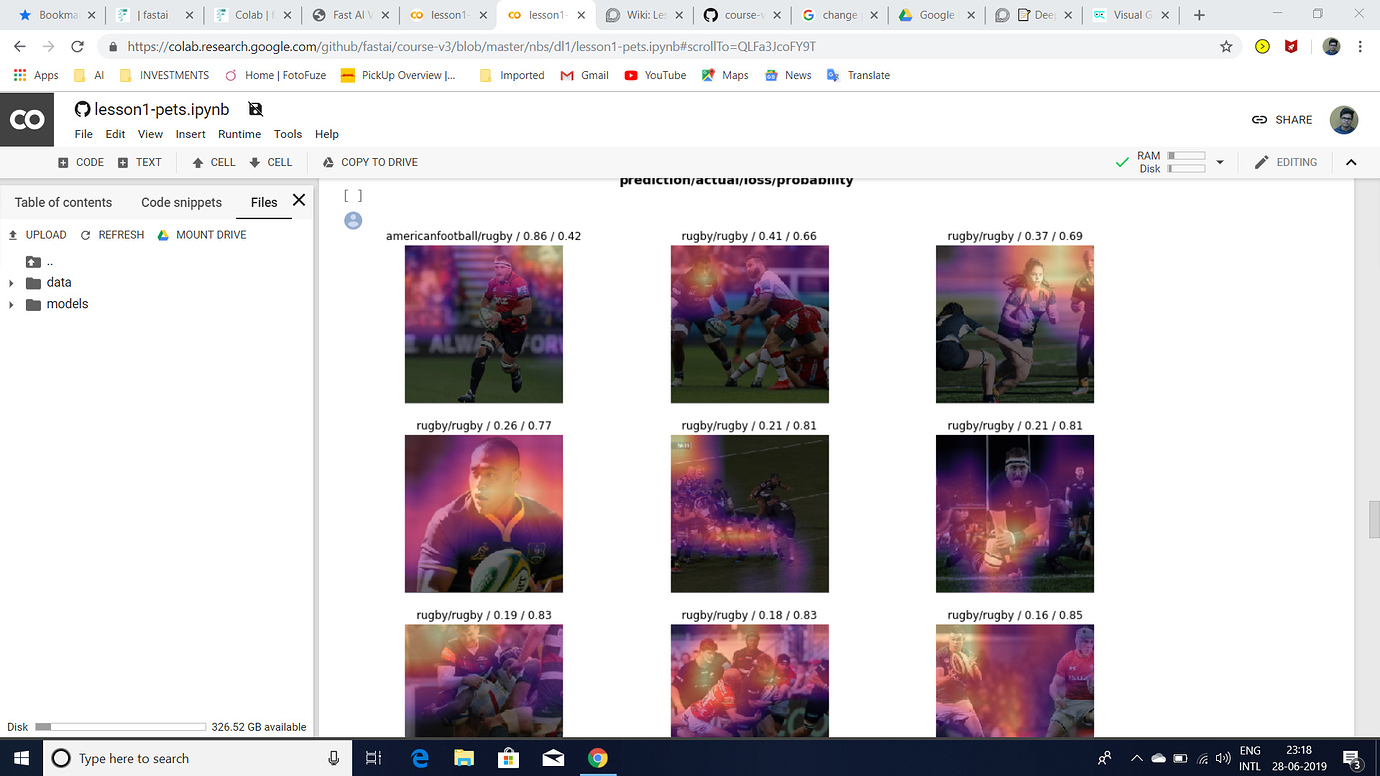
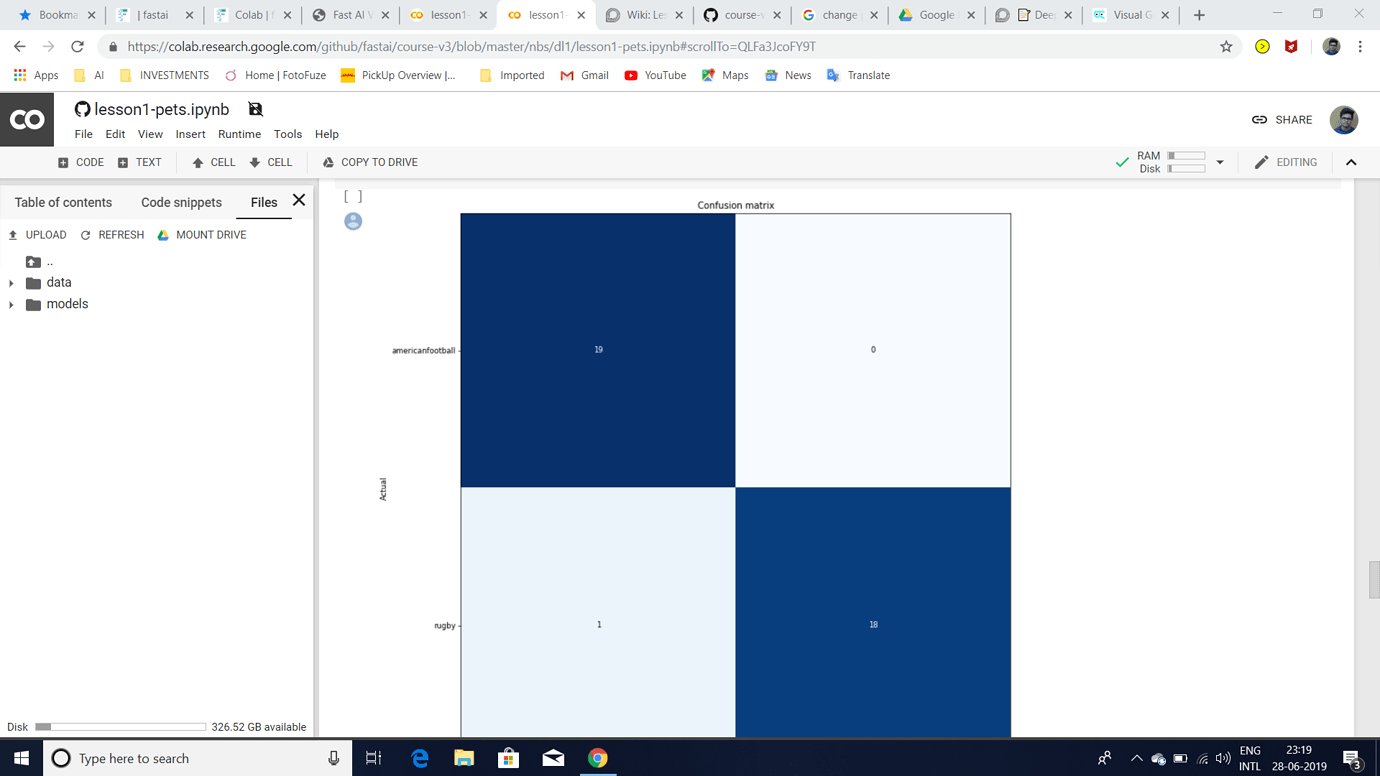
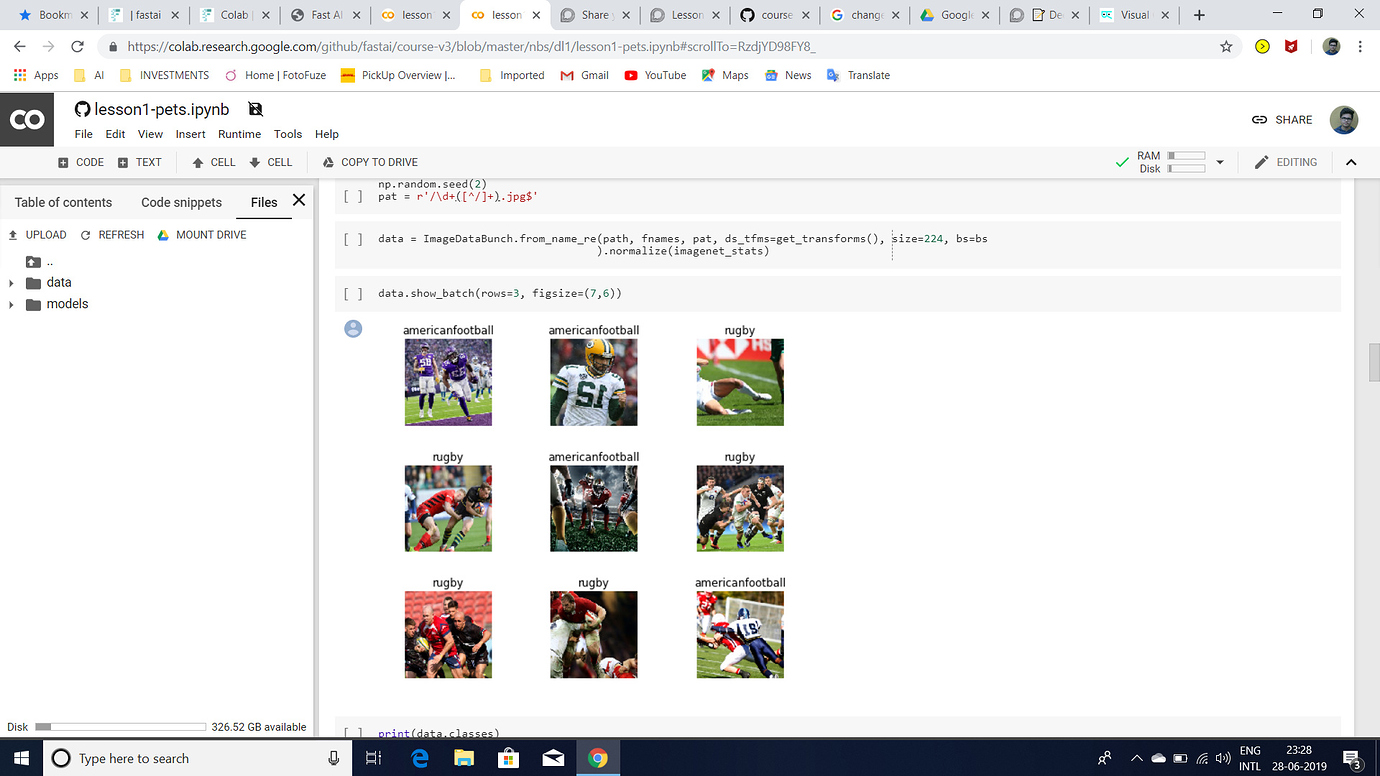
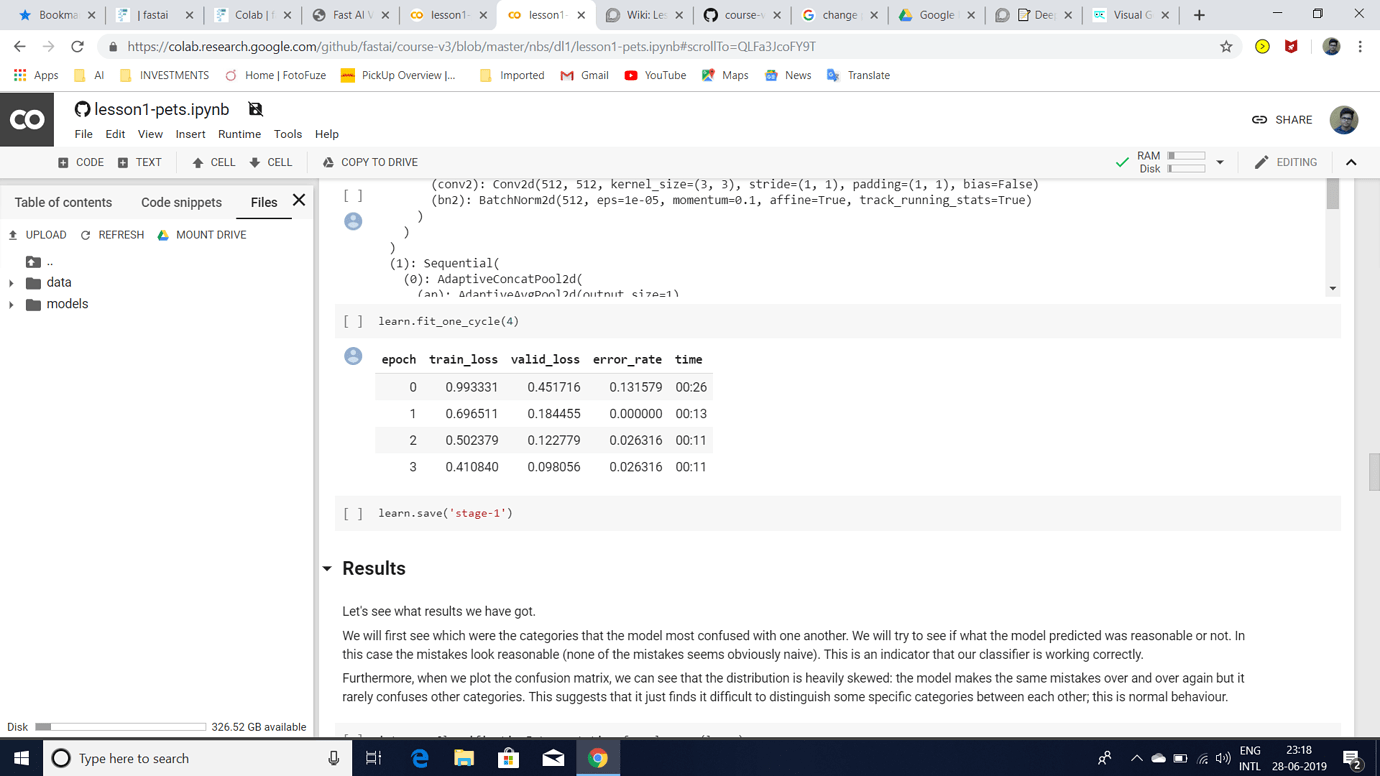
I was trying to build an Image Classifier to classify rugby vs american football images after watching Lesson 1 2019 video.I am getting an error rate of 0.02 but I have the following doubts:
1.I have stuffed around 100 images each of American Football and rugby into a google drive folder and used the Path() function to specify the path of that folder as the path of my images.Is that the right way to specify a dataset?
2.The most confused images(as attached) show that the model predicts rugby less confidently but actually it should have predicted rugby with a higher probability.Can someone please explain exactly what does that mean?
3.interp.most_confused(min_val=2) outputs [ ] .Is that the case for all datasets which have only 2 classes?
4.In the cricket vs baseball example(from the video),plot_with_title() was used but I am currently unable to use that function.Is the function still available?
If anyone could clear these doubts,it would be really helpful.
Thank You!
I’ve managed to get pretty decent results on PlantClef (error around 13% for 1k classes).
Blog: https://medium.com/@maria.preyzner/app-for-checking-plant-toxicity-for-pets-part-2-learning-on-plantclef-2016-839b61d2f58d
Notebook: https://github.com/Mpreyzner/deep_learning_experiments/blob/master/PlantCLEF-v5-public.ipynb
Hi! I used fastai to train a model that can generate bird images from text description, and made a web app:
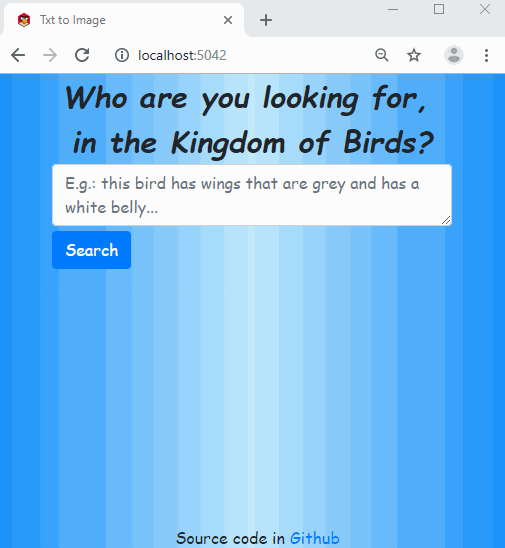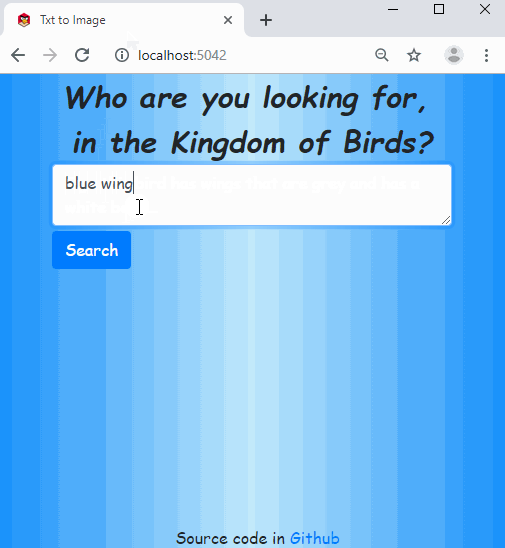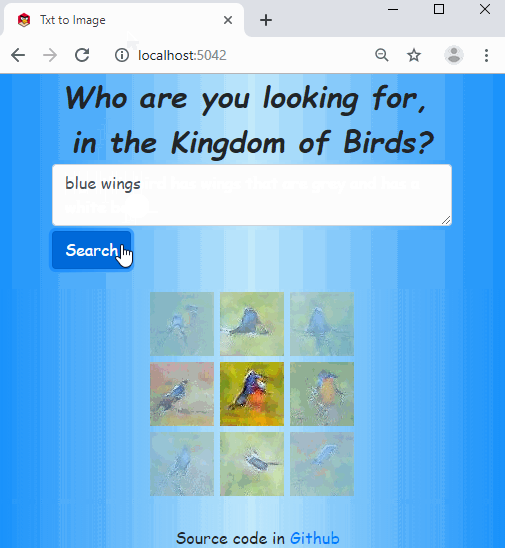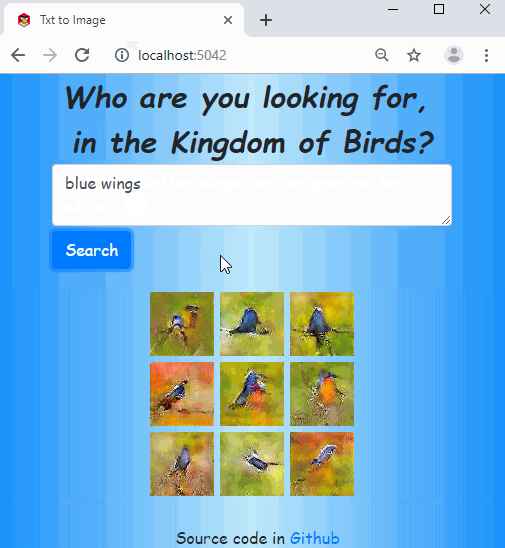
The code is in this repo. The idea is based on this paper, but I used fastai with some customizations for all the works.
There’re a lot of things to improve, but I’d like to share and discuss with you. Thank you for checking out!
9 Likes
Created a flower classifier with resnet (based on Lesson 1: Image classification).
1 Like
I have a question about your dataset. Doesn’t it need some pre-processing? I mean the images look very different on the preview: one vs. multiple players, face close ups vs. legs, etc.
Thank you for your reply.I will try to implement your idea and get back to you.Even I have my fair share of Doubts as I am a newbie.Only if these forums had mentors to answer our Doubts…
Used the exact same code to build a classifier of pandas and bears with an accuracy of 98.98%. Is this overfitting? I’ve never seen a number above 95 until now.
Just saw the sample pictures of the panda on your github notebook. It all has the face in it - and we know that the two black patches around its eyes is a distinctive feature ( at least for the human eye )
Here’s an easy way to check if it is over fitting. My 2 cents
- Collect all pictures of panda ( not just its face ) , take the back side –
- Test your model on these images
- See which all panda pictures it fails ( but you are sure they are panda )
- Add these into your training set ( as label = panda )
Repeat . This will make your model more robust and generalized.

eg: This is also panda ( even if does not show its face )
on a lighter note ,
panda + panda = python library.
