Thanks a lot @MicPie . Now I will continue with my old approach first and move to autoencoder if it does not work out  . I always want to contribute to fast.ai so if I decide to work with autoencoder, I will definitely join you.
. I always want to contribute to fast.ai so if I decide to work with autoencoder, I will definitely join you.
Regards,
Hoa
Thanks a lot @MicPie . Now I will continue with my old approach first and move to autoencoder if it does not work out . I always want to contribute to fast.ai so if I decide to work with autoencoder, I will definitely join you.
Regards,
Hoa
Interesting! Thanks for sharing ![]()
Will be interested to hear feedback from anyone who tries this out.
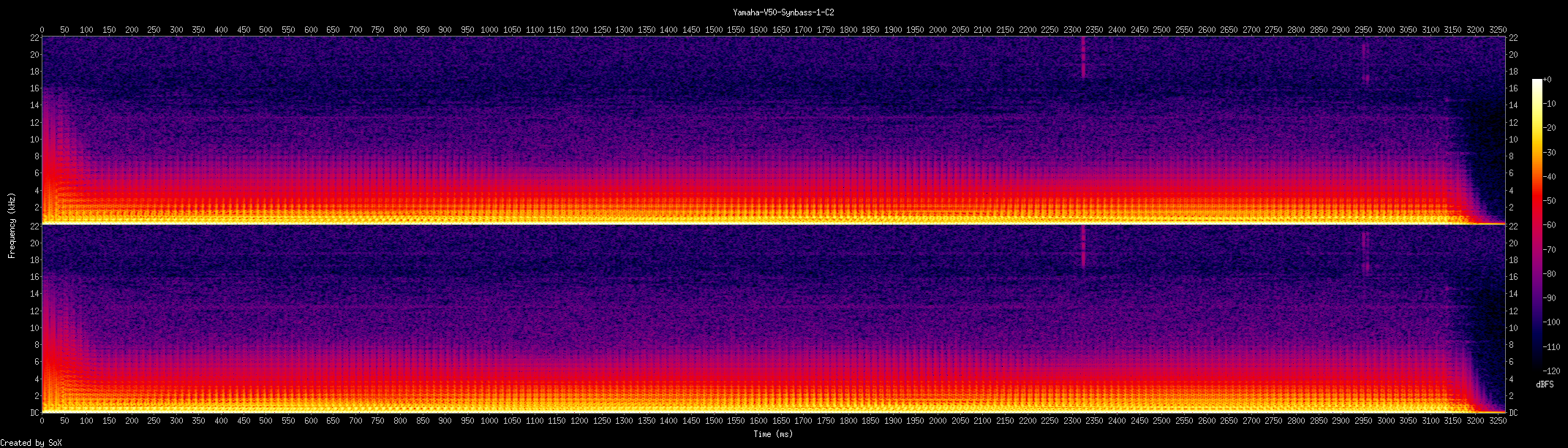
First we do the conversion to *.wav files from mp3
from pydub import AudioSegment
print("Converting...")
arr = [2,3,4,5]
for x in arr:
sound = AudioSegment.from_mp3("{0}.mp3".format(x))
sound = sound.set_channels(1)
sound.export("{0}[WAV].wav".format(x), format="wav")
print("Converted.")
or Even this
from pydub import AudioSegment
sound = AudioSegment.from_mp3("KY.mp3")
sound.export("KY.wav", format="wav")
And then from *.wav to Spectograms
for file in *.wav;do
outfile="${file%.*}.png"
title_in_pic="${file%.*}"
sox "$file" -n spectrogram -t "$title_in_pic" -o "$outfile" -x 2000
done
My friend had used this bash tool and this is a small script from his partially completed project… (There’s Librosa Module also, you can have a look…)
PS These aren’t mine(belongs to my friend); I have very little knowledge wrt music
Edit Added Working Demonstration -
I created an Age Predictor App 
Basically used a pretrained Resnet-50 and trained it on IMDB-Wiki dataset (details in Github repo).
Maybe I am just being dumb but I am still not quite sure how to interpret the valid loss (MSELoss). It seems high but my predictions are not that far off…
Github: https://github.com/btahir/age-detector
Also gave a face lift to the Zeit front-end which you can see in the app. Feel free to use the index.html/style.css files for your projects.
You can check out the app here: https://age-predictor.now.sh/
Great work.
One application of this can be in Hotel review websites like Zomato, which categorizes user uploaded pictures as indoor, outdoor ambience and food.
Most probably they are already using similar ML technique.
Can you share your notebook?
You’ve just made enemies with half of the world’s population.
Hi All,
Inspired by fast.ai Deploying web app to Zeit Production guide, I have created an updated starter packs that supports AWS Beanstalk, Google App Engine, also. Plus I have updated statics file with additional CSS & JS to handle big camera file uploads. Plus, These is started package for Keras image models also.
Then I also wrote a detailed guide to build & deploy these starter pack as a web app on 4 Cloud services, including AWS Beanstalk, Google App Engine, (Plus Azure Website & now.sh).
I hope to keep updating this guide with other Docker hosted Cloud web app services like Digital Ocean, Heroku, etc.
Plus more starter packs for NLP, Text or Collab Filtering.
Oh and This article is picked up by Towards Data Science Publication, so please let me know, your feedback, comments and thoughts here.
Download your starter pack app repository for Fast.ai here:
git clone https://github.com/pankymathur/fastai-vision-app
Download your starter pack app repository for Keras here:
git clone https://github.com/pankymathur/fastai-vision-app
Please do let me know your questions & feedback.
Thanks,
Pankaj
Wonderful work… Pankaj 
Thank You Vishal, let me know, if you face any issue during deployment.
Yeah sure…!
Thanks for this. I will try this soon…
After some effort, I got it partially working. It reached 92.1% accuracy (0.3% bellow my previous model). Some remarks:
Edited: I managed to set the layer_groups properly. In addition to minor tweaks (increase wd and dropout), I reached 92.3%).
I’d love to get some feedback and possible improvements.
Hi All,
Yet another update on my satellite project. Yesterday’s lecture about PCA got me thinking about latent space representations for urban characteristics of cities as seen from space.
I tried doing PCA on the later layer’s vector representations of cities, but the results were a little disappointing, so in the end I used U-MAP to do my dimension reduction. It’s much faster than T-SNE and I thought the results were pretty cool.
I also flattened the U-MAP representation to a grid using the lapjv python package which finds the grid representation of distance maps using some fancy algorithm.
Here is the result:
The actual image is 80MB so here are some interesting higher res areas:
Ochre roofs and twisty roads:

Big backyards:

Dense and arid:

Grids:
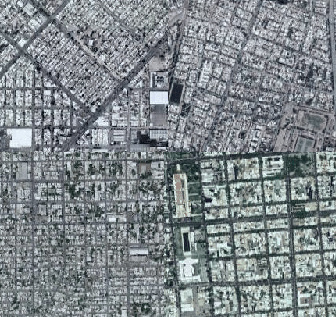
You can check the notebook out here
Very interesting!
Thanks for sharing the notebook and the data plus the scrapper as well
PS 37MB Jupyter Notebook!
Biggest of all I have seen till date
Nbviewer Link Of the Same Notebook https://nbviewer.jupyter.org/github/henripal/maps/blob/master/nbs/big_resnet50-pca.ipynb
Using this we can now detect Roof Top Swimming Pools maybe…
Just saying!
Sure Amit, let me know if you face any issue during deployment.
@flavioavila particularly interested in how you did the preprocessing/padding etc
Hi everyone,
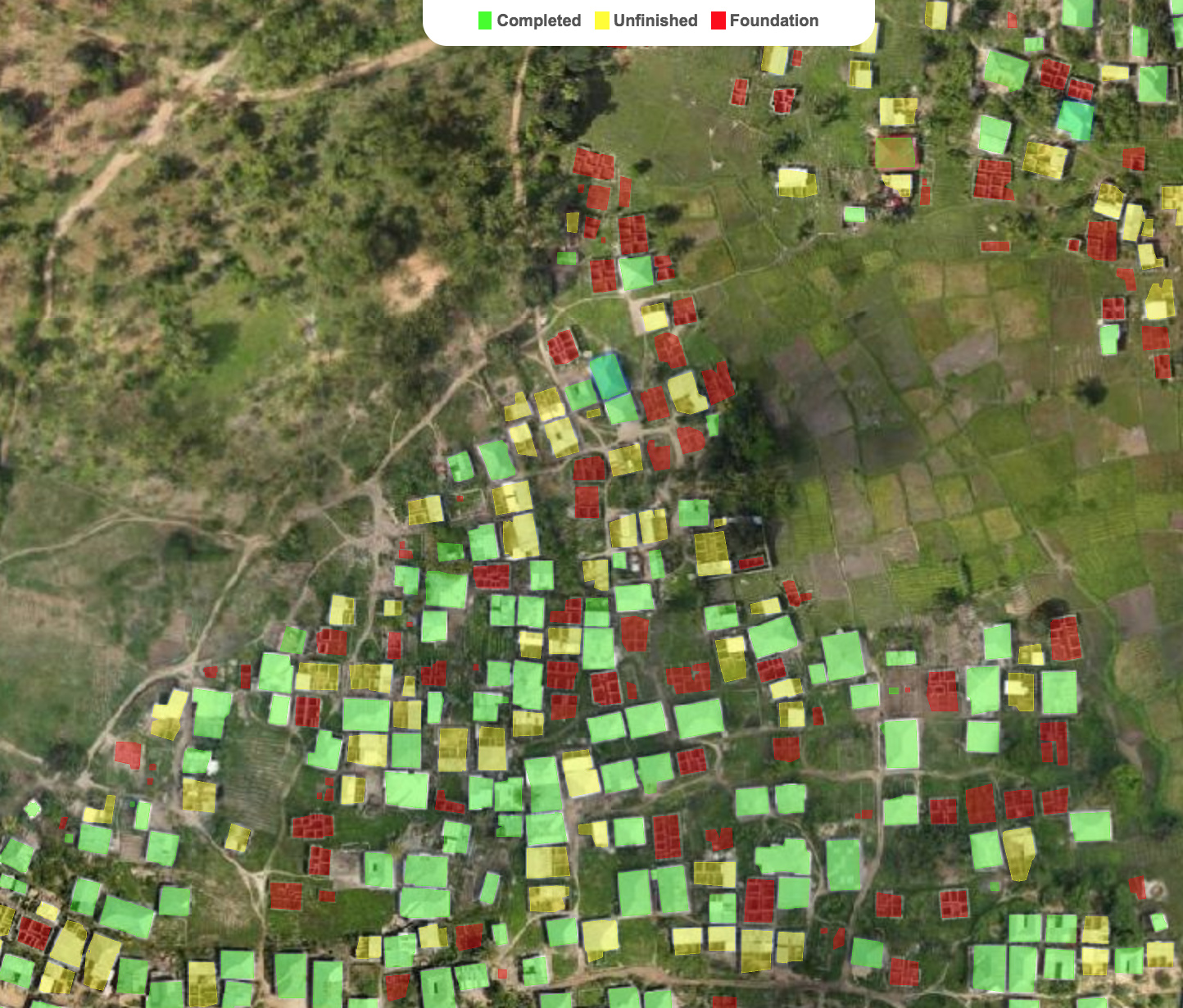
I’m excited to share new developments on segmentation & classification of buildings from drone/aerial imagery in Zanzibar, Tanzania:
Updated building classifier to work with fastai v1.0.28 and trained the model to >94% accuracy. Looking at train/val loss, could keep training to get even better accuracy. Almost every top-loss prediction error is because of mislabeled ground truth data so some ImageCleaner action would definitely help:
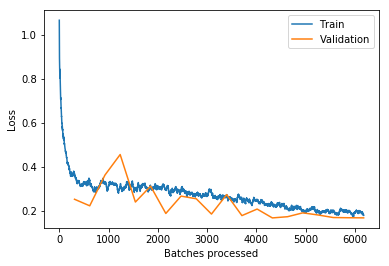
Added Grad-CAM code from @henripal (much thanks for the discussion & notebooks!) to aid in model diagnostics and interpretability. Exploring under the hood to see what insights and ideas for improvement we can get about the model’s behavior.
Here’s looking at individual feature map channels ranked in importance as the sum of gradients for that channel calculated by back-propagating from the one-hot-encoded class prediction (a “Complete” building in this case). In other words, what specific feature maps (out of 2048 channels in my case) are most important to classifying this image as “Complete” and what are they looking at (activating on):

I’ve also created a new segmentation model based on lesson-3 camvid which handles the first part of the overall task (segment every pixel as building or not building). As mentioned in my 1st post, I originally used the old fastai v0.7 library so I’m bringing everything up to v1 now. Performance is not up to that of my old model yet but I’m haven’t done any optimizations. Off-the-shelf fastai v1.0.28 for binary segmentation using a pretrained resnet34 encoder already gives pretty satisfying results (pixel-wise accuracy > 0.98, dice score > 0.85):



Here are both notebooks:
I’ve also open-sourced my pre-processed training data for both models so anyone who wants to work with these notebooks can have ready-to-train data without going through the somewhat-niche data prep to convert geoJSON polygons into binary masks or crop individual buildings into images. For anyone interested in those steps, I will post them as well in future notebooks. Data download links and more info at the repo here:
Much thanks to the Commission for Lands, Govt. of Zanzibar and WeRobotics via the Open AI Tanzania competition for the original drone imagery and training labels. They are made available under Creative Commons Attribution 4.0 International license.
My overall project goal is to keep improving these models and publish notebooks showing the DL model development as well as all the intermediary geospatial data processing steps to make this:
Dave
Awesome @flavioavila! glad to hear that I was somehow helpful 
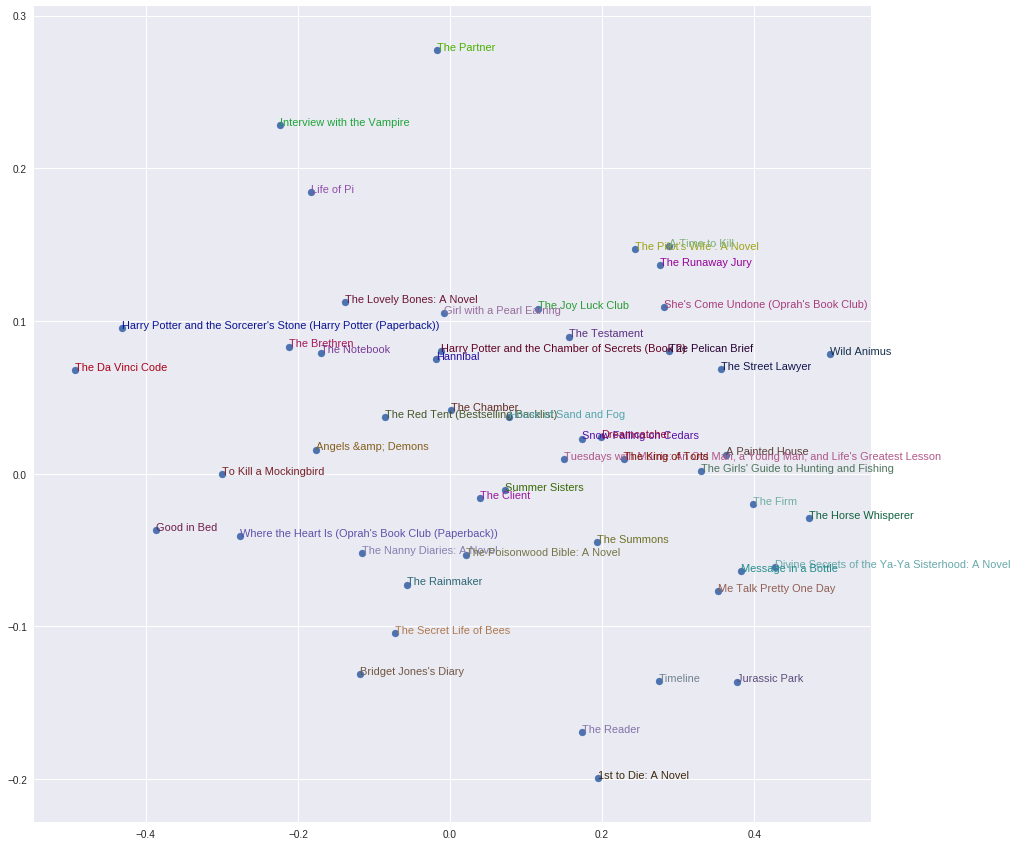
I tried on the Collaborative Filtering from class 5, on this BookCrossing dataset. I barely copy-pasted jeremey notebook, it’s insane how copy-paste work so well in DL lol
My problem though, is I’m not sure what learning rate to pick when looking at the following plot:
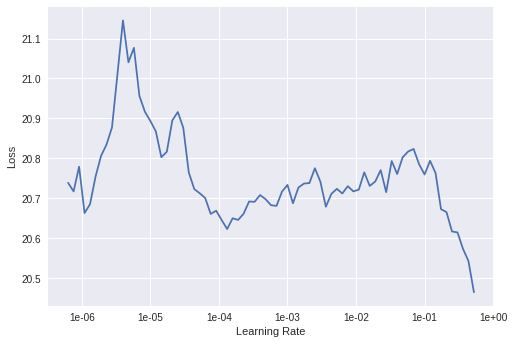
I choosed learn.fit_one_cycle(5, 1e-1) but 0.1 seems to high to me, no?
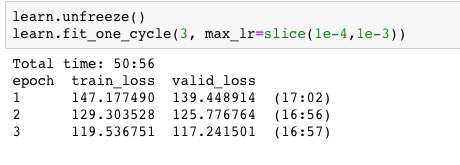
Now the first results are no so good:
Total time: 19:53
epoch train_loss valid_loss
1 15.048554 14.940901 (03:58)
2 15.467329 15.421408 (03:58)
3 14.969577 14.875525 (03:59)
4 14.105888 13.993391 (03:58)
5 13.375766 13.295375 (03:57)
I need to make my head around this, I am not sure how I could interpret the following diagram yet
What are the x and y axis? in the class they were not detailed enough! Here is the notebook https://github.com/dzlab/deepprojects/blob/master/collabfiltering/Collaborative_Filtering_Book_Recommendation.ipynb