wow, thanks! Will take a look and ask more questions!
I don’t think our normal convnets will work well for that. You’ll need to use object detection, which we should be covering in lesson 6.
8 Likes
Ah ok thanks thats good to know!
Regarding music spectograms, can’t we do something like this to perform data augmentation
- We can split the thirty seconds(let’s say 30 sec audio files) into 10 chunks, 3 seconds each… Each window of the song will be tagged with the same genre of the original thirty seconds.
- If a song had rock as genre, then all 10 windows that came out of the splitting will have rock as genre. This trick gives 10x more data than the original dataset.
3 Likes
That sounds like a good plan. I haven’t tried it myself, but I’ve read some papers proposing that with success.
1 Like
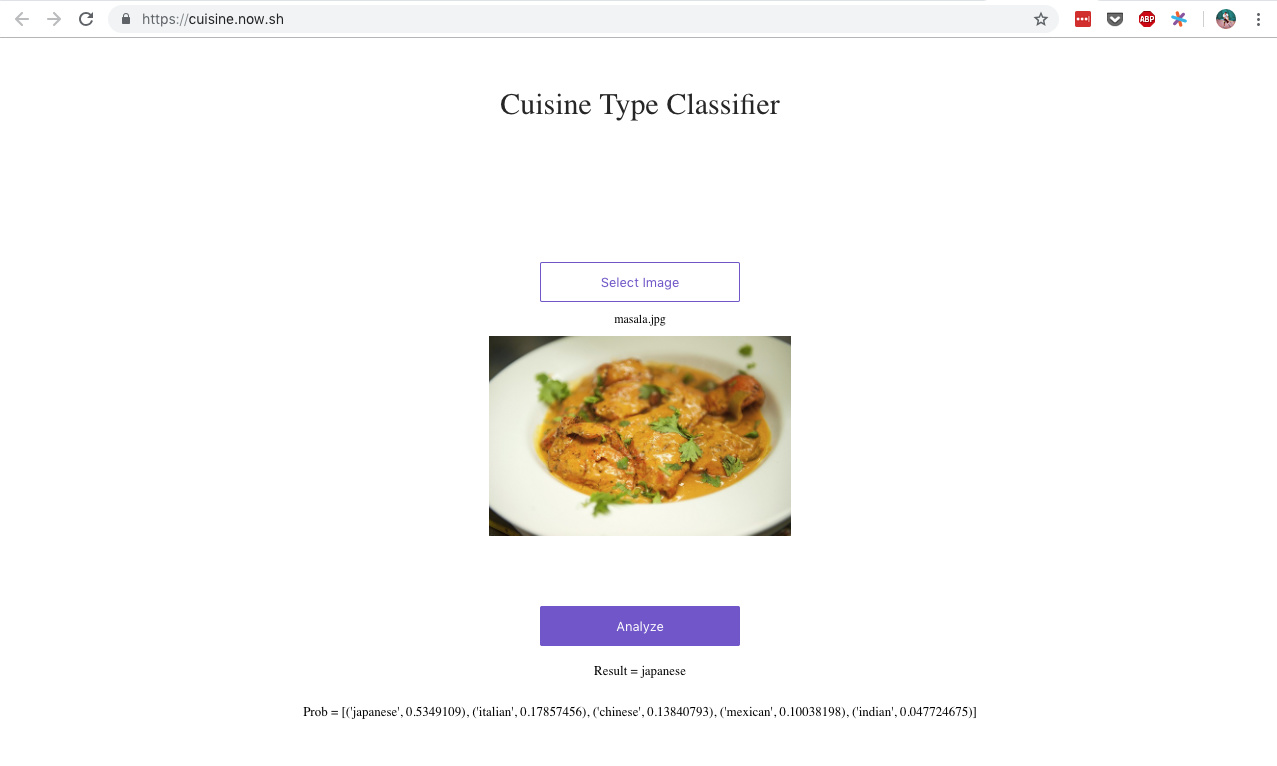
A little late to the game but here is my experiment with creating and deploying a cuisine-type classifier (5 cuisines, with ~200 images each in train+valid).
Learnings:
- Surprisingly only resnet50 was able to bring the accuracy to >70%. Struggled with resnet32 to get accuracy beyond 60% (tried changing lr, batchsize, image_size, data augmentations, ran more epochs until I saw some small sign of over-fitting)
- Increasing image size from 224 to 299 and using flip_vert=True in data aug and using resnet50, was able to bring the accuracy to 70%
Notebook: https://nbviewer.jupyter.org/gist/oostopitre/e5d0c075d5c5e116f890e47d7fb4ec0b
Web-app: https://cuisine.now.sh/
Next Steps:
- add other popular cuisines (french, italian, etc) and a ‘other’ category for non-food images and check the model performance
- web app: add some default sample images that the user can select and test, ability to pass a URL, add GradCAM activation maps, add class prob as a graph
Pro-tip:
If you haven’t already check out imgcat and imgls. Makes working with image files on a remote machine from a TERMINAL so much easier. See https://github.com/olivere/iterm2-imagetools
2 Likes
What do you mean by object verification? Are you saying you can have say 5 pre-trained categories A, B, C, D, E and given a new object you want to be able to classify it as A, B, C, D, E or neither? The method you are citing is an instance-based method and is used to find similar objects by comparing distances between a set of feature vectors extracted from the image. I am working on an image-similarity problem so maybe we have the same use case.
Yeah, kind similar. I want to check if an object with identity A is really A (double check). For example I have a package of apple and want to check if all items inside are apple and not mixing up with orange
But from time to time, I need to add new categories in my model as well, (F, G, … rather than just A B C D E) and because the new categories will be added regularly then I don’t want to retrain the model very often.
This method can be used to compare just the last feature vector to verify the identity (apparently, we should fine tune the model to represent the characteristic of this data set)
Fortunately, I think we are working in the very similar problem. I’m thinking on how to create a reference feature vector with the training set (at first I will just take the mean) and calculate the Euclidean distance. I will update the result when I finish but very appreciated if someone can shed some lights about this problem 
1 Like
So really you don’t trust the label of A and want to verify it.
I would try an unsupervised learner such as a CNN autoencoder and use a bottleneck layer as the feature vector for each image during inference.
First you will need to train it on A to E categories of images to produce a set of filters that can represent your dataset and then you can run inference on each image to obtain the feature vector.
Store these feature vectors in an approximate nearest neighbour search package like Annoy with the label.
Then given a new image you can run inference on it to extract the feature vector then search the AKNN for the K nearest images and obtain their labels and distances. From here you can rank which label is most likely given K nearest images and distances.
How to deal with new image categories?
For new categories you will want at least 3 images in the category. Run the images from the new category through the network using inference only to extract the feature vectors. Then add the feature vectors to the AKNN. Then for each image in the new category search for the K nearest images. If your algorithm ranks the 2 other images in the category as highest match you should be good to use the current network without fine-tuning. If there is a mismatch then you can fine-tune the autoencoder and recompute the feature vectors for the existing images.
There are probably more complicated things you could do to avoid having to fine-tune one network and recompute feature vectors such as have a seperate autoencoder per category.
3 Likes
Thank you so much for your suggestion @maral , it is very helpful for me. I was thinking about using autoencoder also but because I don’t have many experience on it so I first tried with an easy method that I know . I will read carefully your post and try it out.
P/s: By the way, do you have some example codes or a posts that I can read about CNN autoencoder ?
Hi, Do you have you notebook or gist available somewhere? would love to see audio to image conversion part.
Excellent one. i am doing a similar problem and stuck while creating web app. Could you please share some lights how you have deployed this as web app?
Thanks
Amit
1 Like
Hi @hkristen,
Great work and thanks for the link to the dataset.
I am also working on a similar model. I created a small model to classify plants from the picture of leaves. As starting point I trained model with 3 species with 94% accuracy. The dataset was images manually downloaded from google, with around 200 samples for each category.
Did you further worked on this project
1 Like
I am also interested in autoencoders, but for a completely different application.
If you want we can join forces for a fastai autoencoder setup?
Kind regards
Michael
5 Likes
Hi. I’m still cleaning the notebook, but you can check this notebook from Bashir which I used as a reference.
I just followed the deployment guide on course docs page: https://course-v3.fast.ai/deployment_zeit.html
Hi, everyone
I continued working with emotion recognition from speech using the database IEMOCAP but now using four classes (sadness, anger, happiness and neutral) which are the classes with more data. The accuracy dropped to about 64.5 %, which is lower than in this paper from one year ago which achieved up to 68.8 % using convolution layers and LSTMs.
The confusion matrix shows difficulty in classifying the “happiness” category:
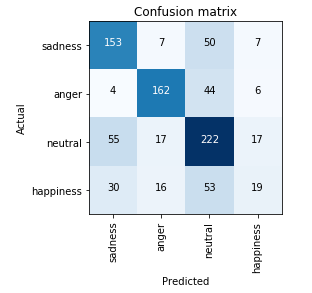
I believe there’s room for improvement using data augmentation, which should be performed directly on the waveform, before spectrogram calculation.
Cheers
3 Likes
The problem with synthetic data is that you will have training and test datasets from different domains. This requires, usually, a domain adaptation approach.
I have made an API based application to serve models in somewhat production settings.
Repo: https://github.com/gurvindersingh/mlapp
Provides following features:
Versioned APIs
Metrics (prometheus)
Ablility to run different version of models without unnecassary code changes
User friendly API documentations
Input data validation
Authentication
Inference device flexibility (CPU or GPU)
Scale up or down instances based on incoming traffic
Feedback is welcome. Hope someone will find it useful.
18 Likes