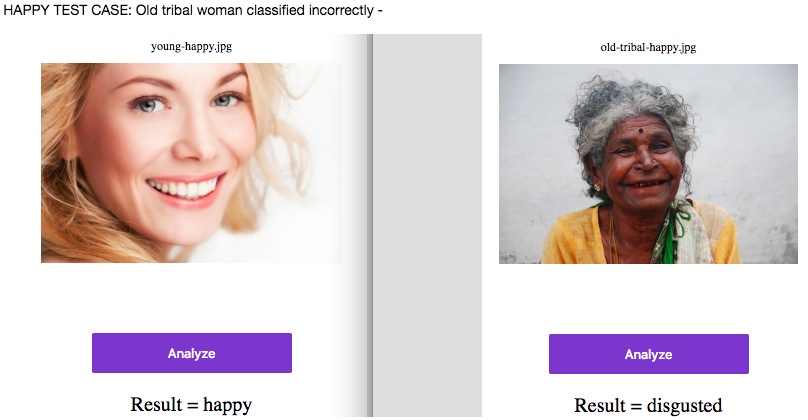
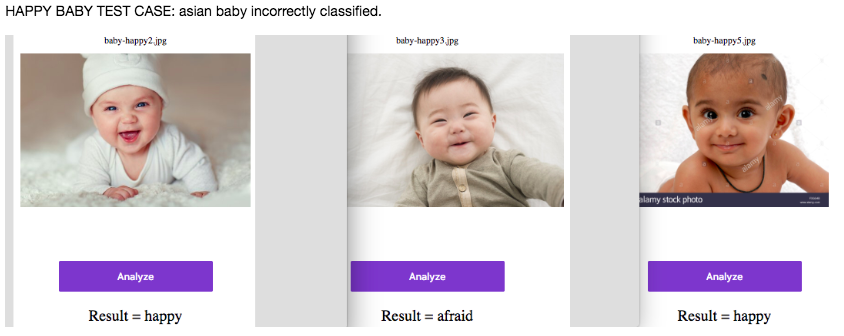
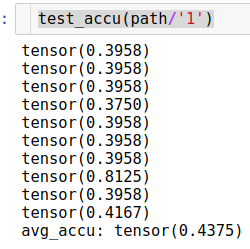
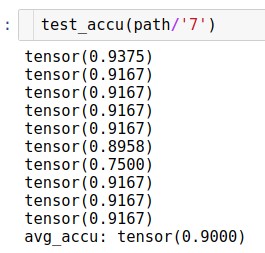
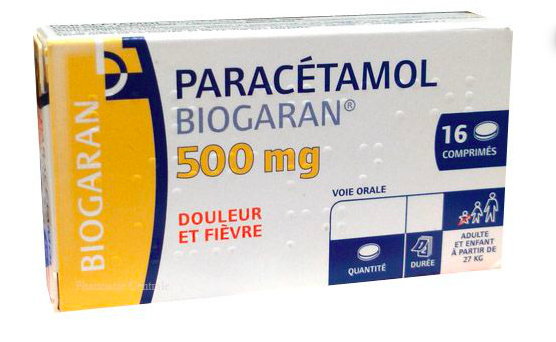
I’m still experimenting on image recognition and did some fun experiment to recognise the dosing numbers (‘500’, ‘250’ etc) on medical packages info like these:
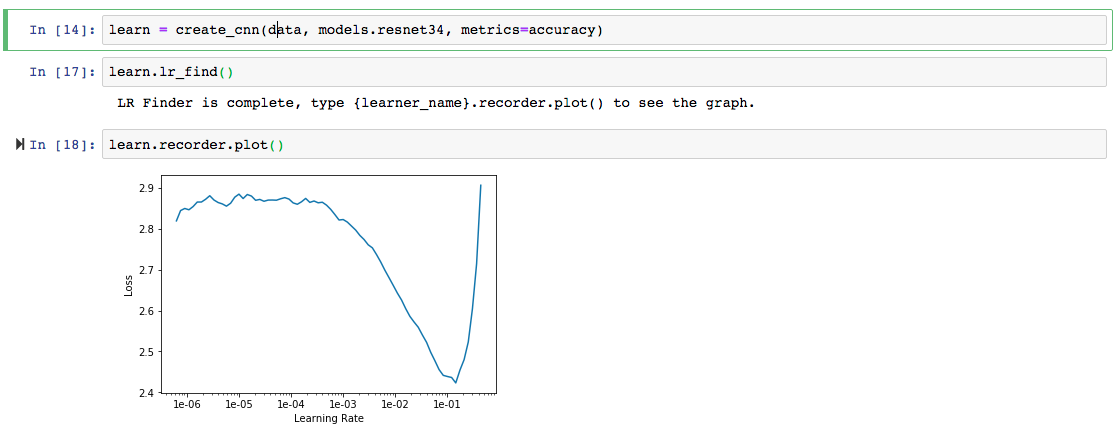
Instead of using a lot of package images, I tried to build a word generator. Inspired by the paper ‘Reading Text in the Wild with Convolutional Neural Networks’ (https://arxiv.org/pdf/1412.1842.pdf?))
Using 3000 free fonts of google it generates 1000 images per class like these:

Next to that I generated background/other images by cropping small parts from other package images:


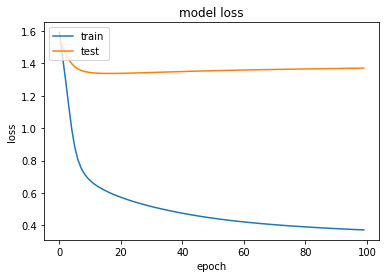
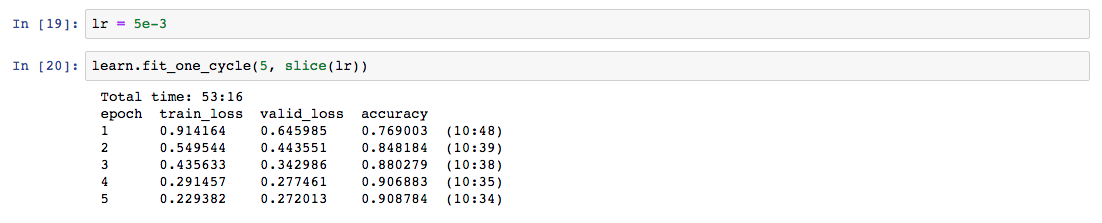
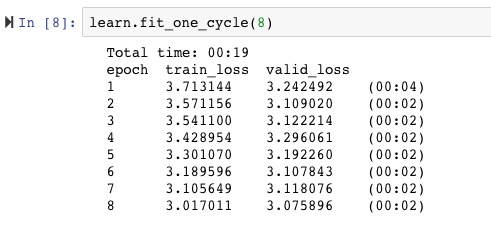
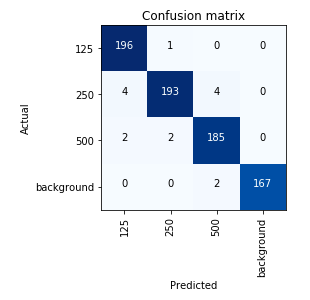
Resulting in a accurate enough classifier with a resnet34 and fit_one_cycle(2):
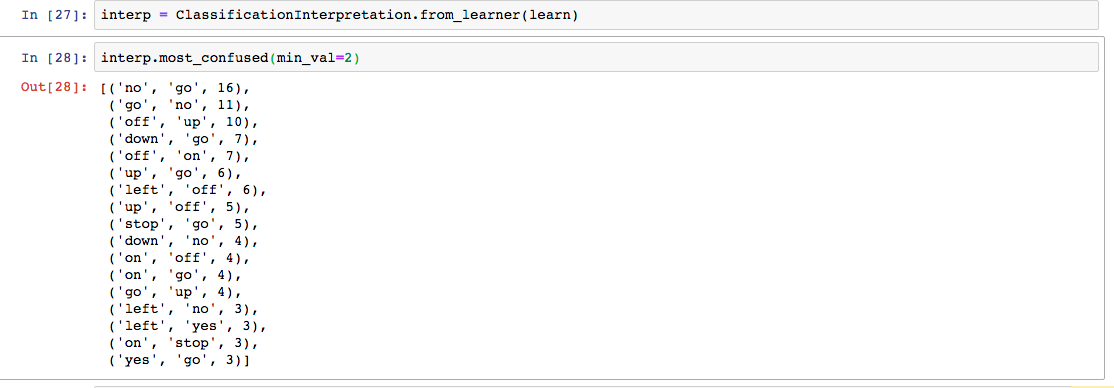
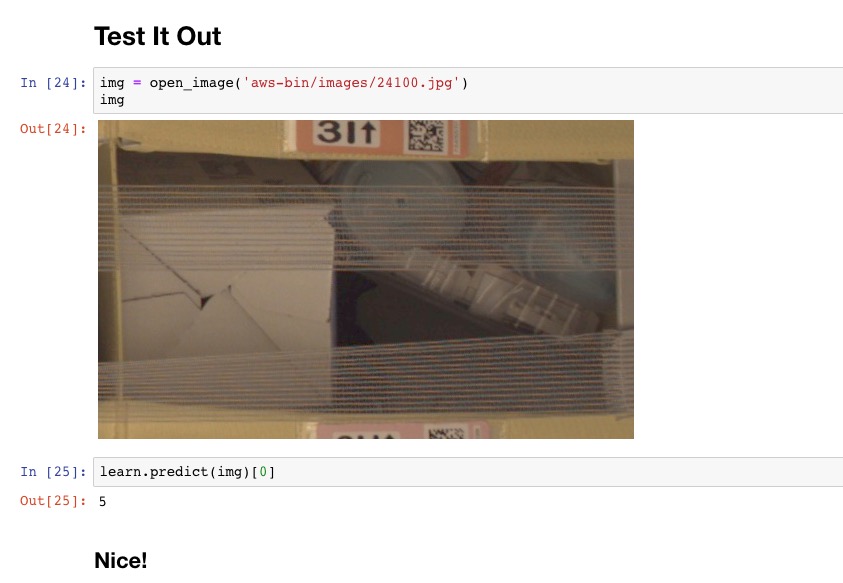
Finally I assess a test image by taking crops and checking each crop.
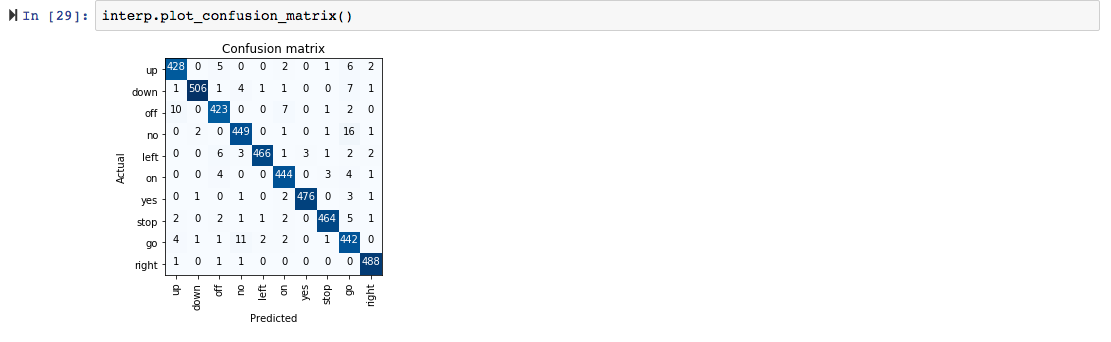
For the first image resulting in:
[(‘background’, tensor(0.9994)),
(‘background’, tensor(0.9972)),
(‘background’, tensor(0.9956)),
(‘background’, tensor(0.9983)),
(‘background’, tensor(0.9903)),
(‘background’, tensor(0.9669)),
(‘background’, tensor(0.9911)),
(‘background’, tensor(0.9783)),
(‘background’, tensor(0.9533)),
(‘background’, tensor(0.9616)),
(‘background’, tensor(0.9490)),
(‘background’, tensor(0.9971)),
(‘background’, tensor(0.9605)),
(‘background’, tensor(0.9728)),
(‘background’, tensor(0.9144)),
…
(‘background’, tensor(0.5990)),
(‘background’, tensor(0.8826)),
(‘500’, tensor(0.8235)),
(‘background’, tensor(0.8679)),
(‘background’, tensor(0.9674)),
…
(‘background’, tensor(0.9831)),
(‘background’, tensor(0.9468)),
(‘background’, tensor(0.9875)),
(‘background’, tensor(0.9906)),
(‘background’, tensor(0.9839)),
(‘background’, tensor(0.9891))]
Obviously this can be improved a lot by integrating a bounding box classifier instead, but it was quite fun to quickly test an idea. Thanks Jeremy and team!
And I would love to get input (like other papers, methods, experiments etc) !
 but finally created my first classifier to classify John Oliver(the comedian) from Steve Mnuchin(US Treasury Secretary).
but finally created my first classifier to classify John Oliver(the comedian) from Steve Mnuchin(US Treasury Secretary).