This is very cool. Nice work. Can’t wait to try it out.
Is there an API only mode? So, I can hook up this with a different frontend?
2 Likes
Currently it’s only the UI, but I’m working on API endpoints too.
3 Likes
Thanks @navjots my notebook is still messy I’m working with Colab and Google Drive, it isn’t that great the kernel kept dying. I still have to run the model on the test data. After I will clean it and push it on github.
1 Like
I have created my image classifer for indian man/ woman. I used a training set with 60 images each (man/woman). My validation set has 10 images each( man/woman )Training set has urban men/women pics. I tried having black and white rural faces in the validation set. I trained with resnet34. I also tested my model wth custom images. Here is my notebook.
How can i improve my accuracy ? These are the things that i think i can do
- One way is to add more black and white images of rural men and women in the training set.
- Add more images to the training set
What other ways can i try to improve the model?
Thanks
Hi everyone!
I’m currently working on a project to segment & classify the condition of buildings seen on hi-res aerial (drone) imagery taken over Zanzibar island, Tanzania. As a step in the workflow, I trained a classifier based on lesson1 notebook to distinguish between 4 types/conditions of buildings on a variety of images (different sizes, ratios, blurriness):
“Complete”, “Incomplete”, “Foundation”, and “Empty” (no building in image)

Using resnet50 pretrained backbone, this achieved 93% accuracy on the 4 classes. Performance is probably even better than the stated number because looking at predictions with highest losses, they’re either mislabeled or so small/ambiguous in appearance that I’m not able to tell what class they should be in either:

I also used the excellent t-SNE notebook/code from @KarlH (thanks! his original post is in this thread here) to visualize how the model is grouping representations. Very helpful diagnostics to understand what is very clearly separated (“Empty” images) and what characteristics make classification more erroneous (visual features like partially roofless rooms of buildings that confuse between “Incomplete” and “Complete”).
Look forward to exploring more how to use these techniques to diagnose model errors and improve training with less data (i.e. selectively train in later cycles on harder data that’s more similar to what the model is struggling on):


Here is my notebook: https://nbviewer.jupyter.org/gist/daveluo/8e9d60e597303b42dc36f926a3ece466
In it, I show training on resnet34 and resnet50, loading & predicting on a new external set of test images, packaging up the test predictions in pandas to csv file, and t-SNE visualization.
I load my train and validation data (data.train_ds & data.valid_ds) differently than what’s shown in the lesson by peeling the onion a few layers and using ImageClassificationDataset() instead of ImageDataBunch.from_name_re(). I did this to directly define which image and corresponding label files go into validation vs training. Because I’m working with geospatial image tiles that come from larger grids that are adjacent or sometimes overlapping, there’s the risk of data leakage if I’m not careful about keeping data from different grids cleanly and consistently separated. Defining exactly what files go into train/val also lets me do some hacky stuff to balance my classes: training on a half of the majority class for a cycle and then redefining the dataset with the other half of that class for another cycle of training. I’m sure there is a more elegant way to do this…still looking into it.
I mentioned upfront that this is a segmentation + classification task. The segmentation part I started working on first using the older v0.7 of fastai library so there’s some major duct-taping of workflows and data processing going on. I’m looking forward to updating the segmentation work to Fastai v1 and sharing it with everyone!
Here’s a preview of what the end product (segment + polygonize + classify) currently looks like:
(green = “Completed”, yellow = “Incomplete”, red = “Foundation”)

Dave
52 Likes
I downloaded a fun dataset of Traditional Decor Patterns from Kaggle.
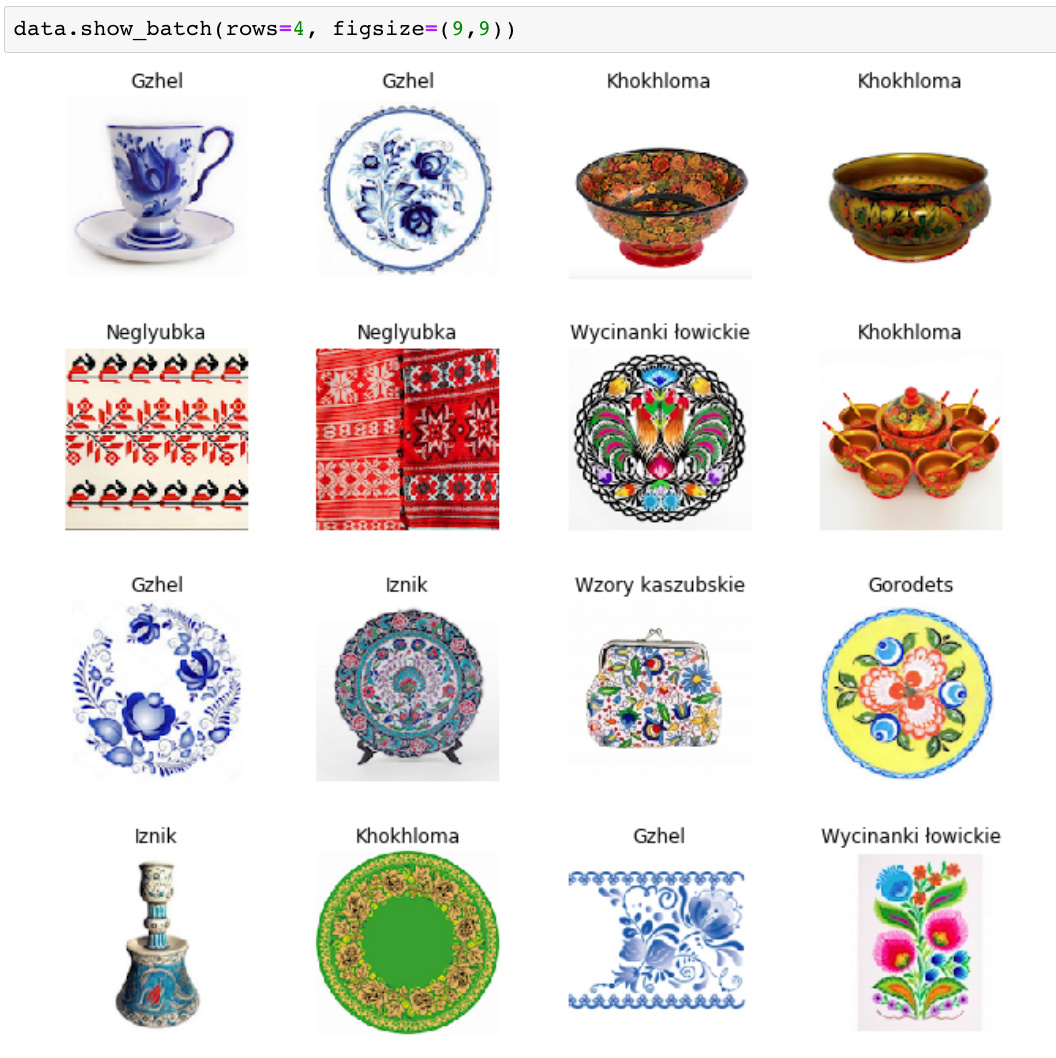

As you can see I first tried fitting the model without transforms. Training resnet34 I got an error rate of 12% for the data without transforms. After applying transforms I only had a 4% error rate in distinguishing between 7 different traditional decor patterns.
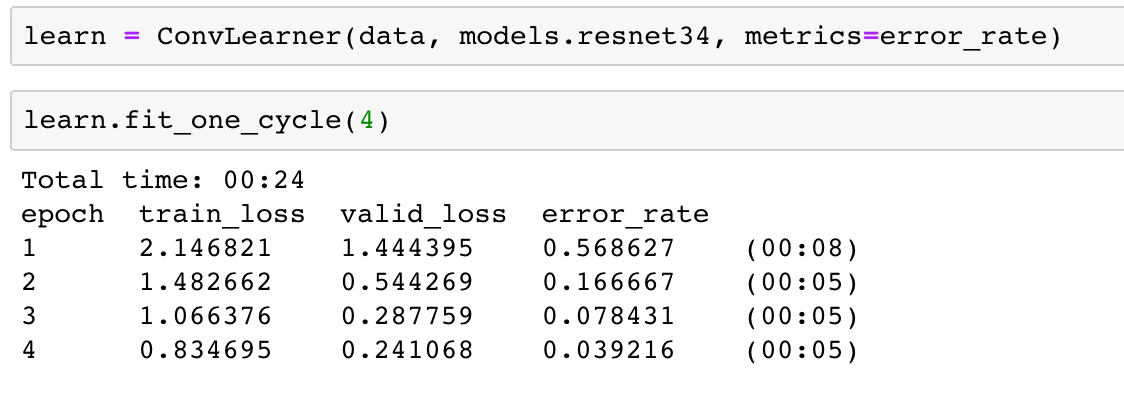
Considering the varied shapes of the objects on which the patterns are printed I think that’s pretty awesome! And the data set isn’t huge, just under 500 images.
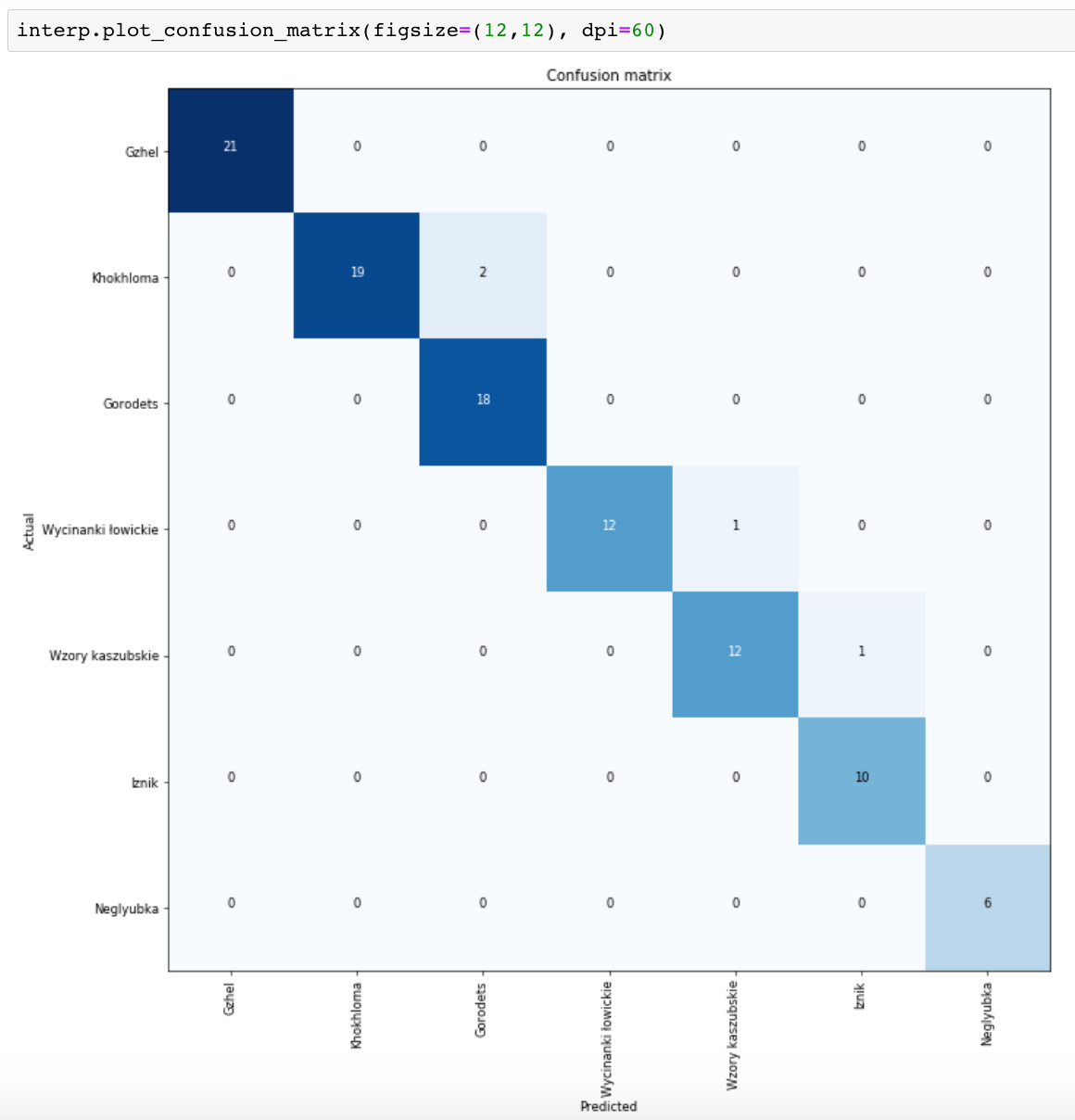
6 Likes
Hello all!
I was wondering how fastai library (using master branch, 1.0.16.dev0) handles a huge amount of data and I took dataset from kaggle competition from Google – Inclusive Images Challenge. There are 1.7+ mil images (0.5+TB) with 18k+ unique classes. Test set for this competition is 3.5GB or 32k images. The task is multi-label classification, meaning that each image can contain many classes simultaneously. It’s forbidden to use pre-trained models in this competition, but my first goal is to try to use “vanilla” fastai setup for this task and look how it goes. And maybe later I’ll try to retrain model from scratch (not sure how to set it up yet  ).
).
My findings so far:
- I was able to run this task with almost no custom setup – only data preparation. And fbeta loss function doesn’t seem work right on my data, so I was needed to add torch.squeeze to y_preds in fbeta before all calculations (didn’t dig deeper for the cause of that).
- fastai library works awesome with multi-label data from the box, but there are no actual docs how to run tasks like that. I found Planet example, which looks a bit outdated and without inference step. Also, I didn’t see examples of class threshold finding
- Performance of model after
fit_one_cycleon this task with 18k labels seems very bad. I think it can be because of such long epoch (almost 30k batches per epoch, 5 hours per epoch). Loss at the end of single epoch looks too small, 0.001-. - Performance could be bad also because of highly unbalanced labels – right now I’m experimenting with just 100 top classes (it reduced 1.7mil to 1.4mil images). Still bad though
- Time of training wasn’t so different for resnet34/50/152 with frozen layers – about 5h/epoch – I was surprised, but maybe bottleneck is not in architecture, but in images preprocessing (I have 1950x CPU with 32 threads and run experiments with 30 workers for data), not sure.
- With such big dataset, it’s critical to check the integrity of all data – my first experiment failed after 3h of training because of one missed image.
- You should try all pipeline on smaller set of data – I just copied 1000 images in train_small directory and then set up all things to save checkpoints, make predictions etc.
- Read manual! Always check required params for methods you use. My second experiment failed because I just called
learn.save()without checkpoint name param. And I have to retrain it again for 5h.
I like how optimal library uses all resources it needs:
9 Likes
I ended up using the very useful notebook to grab my data from Google Images. I grabbed pictures of 11 different galaxies and then did some slight hand pruning for getting rid of some of the junk images.
With resnet34, I was able to get about 68% accuracy and then with resnet50, that increased to about 75% accuracy.
Here is the notebook: https://github.com/mark-hoffmann/galaxy-classification/blob/master/Galaxy%20Modeling.ipynb
Example Images:

Ending Confusion Matrix:
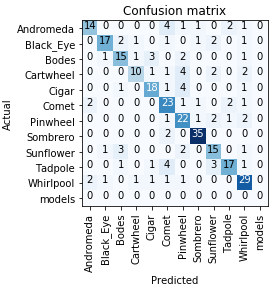
5 Likes
I’m glad you found the notebook helpful.
I’m curious how you’re polygonizing your segmentations. I’m working on a segmentation problem and I’m looking for a good method to turn blobby rectangles into pretty rectangles.
1 Like
I tried using the image model to identify the artist of a painting. My working hypothesis is that you should be able to identify artists by various visual idioms in their paintings. So rather than classify entire paintings, I chopped up high resolution images of the paintings into small blocks and attempted to classify the artist from just the small block. As a trial run, I choose 6 artists - 3 pairs, each pair of similar style (to make it a hard problem). The artists where Botticelli, DaVinci, Monet, Renoir, Demuth, and Lewandowski (renaissance, impressionist, precisionist).
I guess I was expecting too much - since the best I could do was about 26% error rate (128x128 blocks, using resnet18, the larger resnets did slightly worse). So what can you do with the trained model? To analyze a painting, I stepped through it using overlapping blocks and got the probabilities of each artist for that block position. Then I averaged all these probabilities (per pixel) and multiplied, pixel by pixel, the original image by each artist’s probability, The resulting images show the regions of the painting which it attributes to the given artist. It’s not going to change any art critic’s mind with the results, but they are fun to look at.
Below is a example. Using a contested DaVinci painting, what does my model think?
It turns out the model is good at identifying DaVinci hands, so it got that. Interestingly, it thinks that the gold pattern on the robe is more like Botticelli. And the face is assigned to Renoir. Note that Demuth and Lewandowski images were black (zero probability), so I didn’t include them here.
I think I can do better with the following ideas that I want to try out. If I use sigmoid for the final activations (similar to object detection), then the model can indicate “don’t know”. Also, I want to included different scalings (at least 3 octaves total) to generate the training/validation image blocks. Then the analysis phase would step through the image multiple times each with a different scale size.





14 Likes
Okay, so here’s an update. Just by using a better type of spectrogram, I was able to achieve 80.5% accuracy across the cross validation folds. That is with no kind of augmentation at all.
According to the latest publication on the dataset’s website, the state-of-the-art mean accuracy achieved was 79%. It should be noted that is with extensive audio specific augmentation, and without augmentation their top accuracy was 74% .
It’s pretty cool that fastai out-of-the-box can produce these kind of results even on images distant from the kind found in ImageNet!
7 Likes
Thank you! Look forward to seeing more of your work.
This kaggle kernel (specifically mask_to_polygons()) has worked pretty well out-of-box for me: https://www.kaggle.com/lopuhin/full-pipeline-demo-poly-pixels-ml-poly
Adjust epsilon to get more/less boxy polygons, min_area to filter small artifacts and then it’s mostly about how you threshold your activation map into binary masks. Occasional invalid geometry errors (I think mostly self-intersections) slip through which I either just discard if they’re rare or try to fix with shapely’s polygon buffer(): http://toblerity.org/shapely/manual.html#object.buffer
4 Likes
I used lesson 1 to train a classifier on a similar fine-grain classification problem, using the fisheries monitoring dataset on kaggle. I wrote a medium post about it.
Basically the post dwells on these concepts:
- the argument for fine-grain classification problems, considering that as Jeremy said, the Dog vs Cats kind of problems is now too easy.
- transfer learning
- training and validation sets
- fine tuning
I would be glad if you take a look and let me know your thoughts.
The project is available on github.
Also I want to say a big thank you to @lesscomfortable and @rameshsingh for proof reading the draft for me.
2 Likes
My project I’ve started from lesson 1 is facial recognition - more specifically distinguishing between family members of the same gender. For starters I have 20 photos of a dad and 20 photos of a teenage son.
My results from training aren’t that great and I’m wondering what I can do to improve results?
Here’s the output from resnet50 with 8 epochs. resnet34 has a higher error rate, so doesn’t work as well.
Total time: 00:37
epoch train_loss valid_loss error_rate
1 0.922177 0.831953 0.750000 (00:06)
2 0.825071 0.886139 0.583333 (00:04)
3 0.597994 0.902047 0.500000 (00:04)
4 0.455691 0.878664 0.416667 (00:04)
5 0.371805 0.862705 0.333333 (00:04)
6 0.312212 0.809088 0.250000 (00:04)
7 0.267372 0.755920 0.166667 (00:04)
8 0.232702 0.691001 0.166667 (00:04)
unfreezing the model and using a custom learning rate appears to be overfitting as shown by the super low training loss and an increased error_rate (though valid_loss is lower):
learn.fit_one_cycle(1, max_lr=slice(1e-4,1e-2))
Total time: 00:04
epoch train_loss valid_loss error_rate
1 0.024290 0.433804 0.333333 (00:04)
Should I do more epochs? For the frozen model, I’m not sure if I’d be over training/over fitting by using more epochs.
Should I use a deeper base model (e.g. resnet101)?
Do I need to get more data?
A little update – with just top 100 classes from 18k I was able to finetune resnet152 to ~0.6 F2 score on validation set. Without smart threshold finding (I just took 0.2 for every class) I was promoted to 41th place on LB with 0.277 F2 score.
Next steps:
- Learn how to do threshold search with fastai
- Learn how to do cross-validation with fastai
- Start training model from scratch – it need to be done to be able participate in next stage of this competition
A bit later I’ll compile my notebook from several different ones and post it here.
4 Likes
Great work @etown 
1 point - from a quick look at your notebook link you posted earlier - it looks like you are training and testing on each of the folds and then averaging the final accuracy.
I believe the dataset wanted a 10-fold CV on the 10 folds they had provided:
I think they meant using a split of 9 folds to train, and then measuring CV on the 10th fold - and repeating it 10 times with a different CV fold each time - and then averaging the scores.
Reference: BEFORE YOU DOWNLOAD: AVOID COMMON PITFALLS!:
Thanks, I thought that was what I was doing, but I might be confused.
For example:
Train on Folds 1-9 and test on 10
Train on 2-10 and test on 1
So on…
Then average. Is that not correct?
Did you manage to upload the 89 MB of the model with a free account?
I was thinking about this problem awhile back, but I was thinking to use seismic network to identify paintings (actually I was thinking about telling authentic ones from forgery) like how facial recognition works – just thinking and haven’t really done anything about it (at that point I can’t even setup my environment for any real work … not until lesson one now). Anyway, this is very interesting!
Yes - exactly.
Is that what you are doing?
(I might be wrong then, I just gave your notebook a quick scan)
isn’t the process_fold() function only taking data from 1 fold at a time - and then training and measuring CV accuracy on that?