Hi All, here is my work on applying transfer learning and fine-tuning from Fast.AI Lesson 1 to a problem of cancer class classification using genomic data encoded as images. My twitter handle is @alenushka if you need to find me outside of this forum. Thanks!
9 Likes
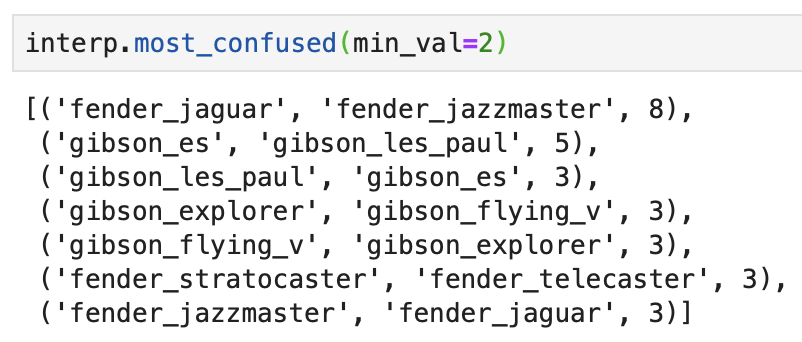
This links well to this post https://forums.fast.ai/t/share-your-work-here/27676/98 and my reply as well. We all got similar results I think, around 75% with pre-trained ResNet34 and above 80% with ResNet50 (a little more if training was done after unfreezing). What I like about comparing our works is not only the consistency of results (meaning I was following it correctly), but also our slight differences in preparing the data, which helps broaden my beginner’s knowledge of Python techniques for data preparation a bit. Thanks for sharing.
290 pictures. After manually checking what was downloaded, I had to abandon the idea of using google search, since:
a) there were a lot of data leakages (for example pictures contained text and the name of the Artist)
b) often google by mistake mislabeled the works
What i did was taking the screenshots from Google Arts and Culture project (https://artsandculture.google.com/) and then apply custom transform to crop images 70% to remove author signatures from each work.
xtra_tfms = zoom_crop(scale=1.3, do_rand=False, p = 1.0)
tfms = get_transforms(xtra_tfms = xtra_tfms)
What I planning to do is to cut each artwork in 50 tiles and train the network to classify a tile, instead of the whole masterpiece.
1 Like
Thank you - this solved it!
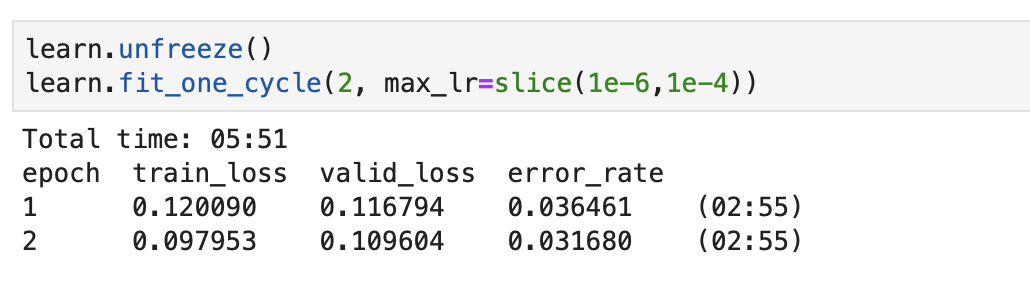
Update: It helped a lot - the error rate is around 9%, but there is some overfitting going on (the valid loss is much higher than the training loss):
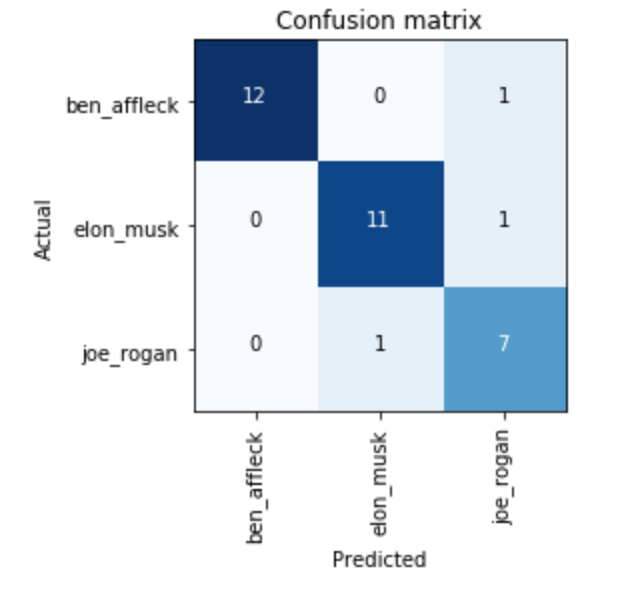
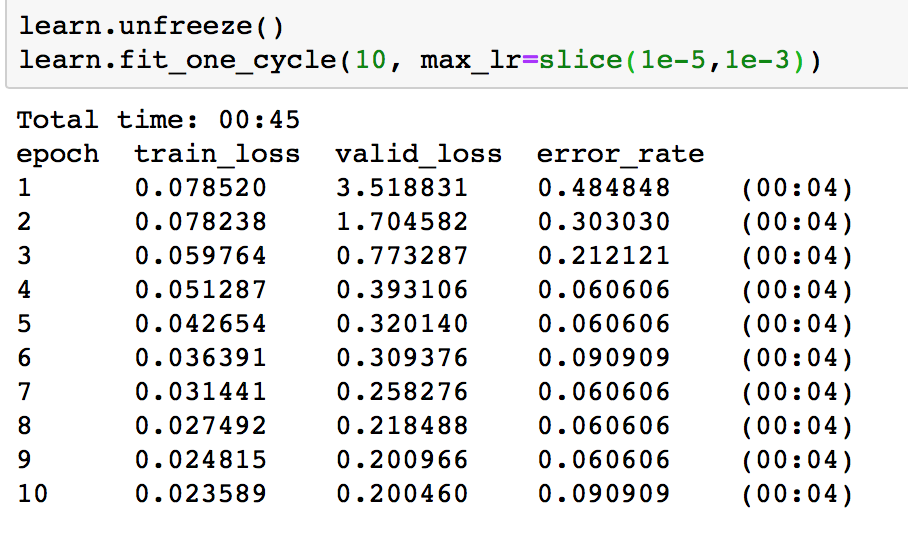
I had to play around with the learning rate (and unfreeze the model) a bit to get the error rate lower. I’m still not sure how it all works but am excited to learn about it in the coming lessons.
3 Likes
Great work and a very nice article! 
You mentioned several interesting data sources and tools I have to check out in detail.
Do you plan to share your notebook?
You’re not overfitting - your error isn’t really getting significantly worse.
1 Like
Here is a link to my Notebook that attempts to classify David Bowie personas. It is about 75% accurate based on the data set with resnet34.

The most immediate issue that I noticed is that the raw data quality from Google images is quite bad. In particular, there are a lot of mistags between the ‘Ziggy Stardust’ and ‘Aladdin Sane’ classes which likely leads to the high confusion levels.
I also ran into crashes when attempting to display the data and run the learner that appear to bad image files. Has anyone else run into this problem? I got around it by adding an extra post-download step to explicitly deletes any images that fail to open.
3 Likes
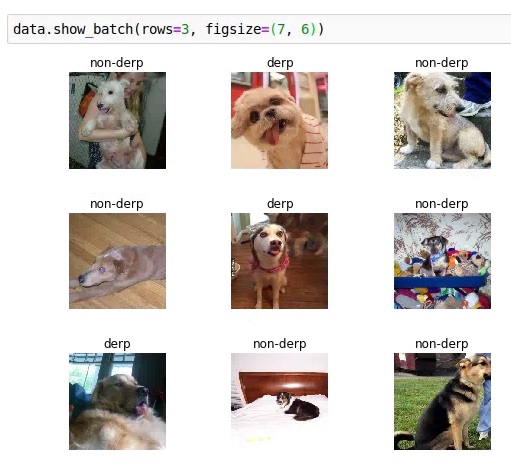
So, for fun, I decided to work on “DerpNet”… a network to classify “derpy” dog pics from regular dog pics
For my dataset, I scraped images from a Google Image Search for the term “derpy dog” and arrived at around ~ 200 images. I also grabbed all 25000 dog images from the dog vs. cat Kaggle dataset and selected around 650 images at random as the “non-derpy” class (I reviewed these manually to ensure none of them were “derpy” in nature)
Here is a quick look at some images:
Following along the lines of the Lecture 1 notebook, I trained a Resnet50 model and was able to achieve ~ 5% error rate in training, which seemed pretty decent.
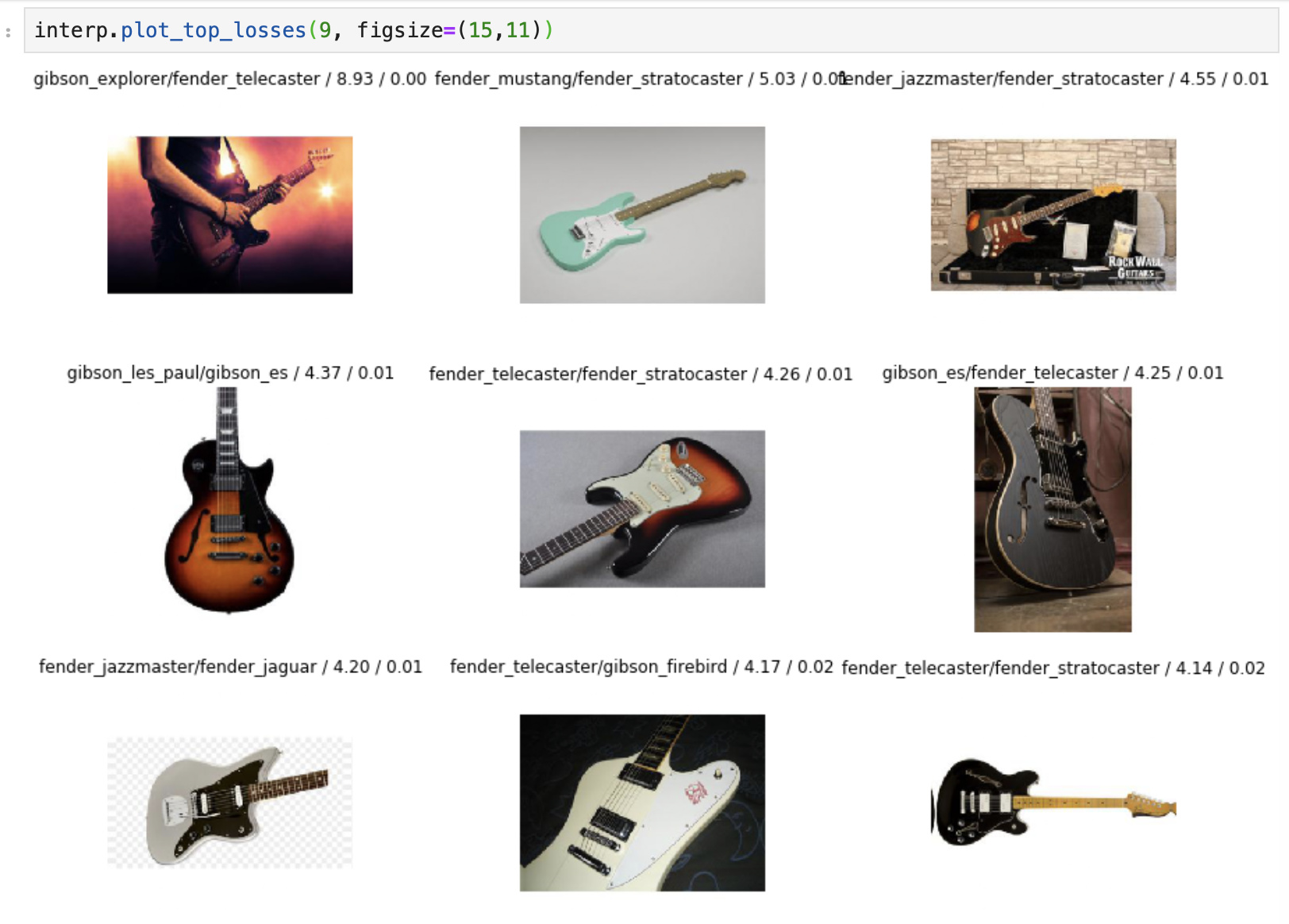
The real test though for me, was to see if I could use this model to actually find instances of derpy dogs in an unlabeled dataset. To test this out, I ran this trained model against all 25,000 dog images in the dogs vs cats dataset and then looked at the top-50 highest confidence “derpy” predictions made by the classifier.
As I expected, the generalization wasn’t too great. This isn’t too surprising given that “derpyness” is not well defined, and since I don’t restrict to a single breed of dog, there is a lot of variations in the “derpy” class of images and only 150 training images are unlikely to be sufficient. Still, I was quite pleased to note that there were some definite successes for my model as shown below (Ranks 1, 2, 13, 14, 37, 46)
Rank1:






Interestingly, the dogs dataset had the following (trick?) image within it that was labeled as “dog”. DerpNet ranked this pretty high (Rank 40 out of 25000), so clearly the model needs a fair bit of work, though, to be fair, the model was trained to output P(derpy | dog) and wasn’t really trained to handle rejecting images with no dogs in them at all.

I also reimplemented all of this from scratch using Pytorch only (largely based on code in this tutorial - https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html) and despite not using lr_finder or one_cycle_fit, I was able to achieve slightly better performance simply training over several epochs with an error rate of 4.4%.
9 Likes
Eating any other burger outside of an In-N-Out burger is almost considered blasphemy for us folks in Southern California. So what would you say if I told you there is an app on the market that could tell you if you have been offered an In-N-Out burger or not an In-N-Out burger?
Wonder no more!
The first public beta of the “In Or Out?” application is now available for Android (download the APK here).
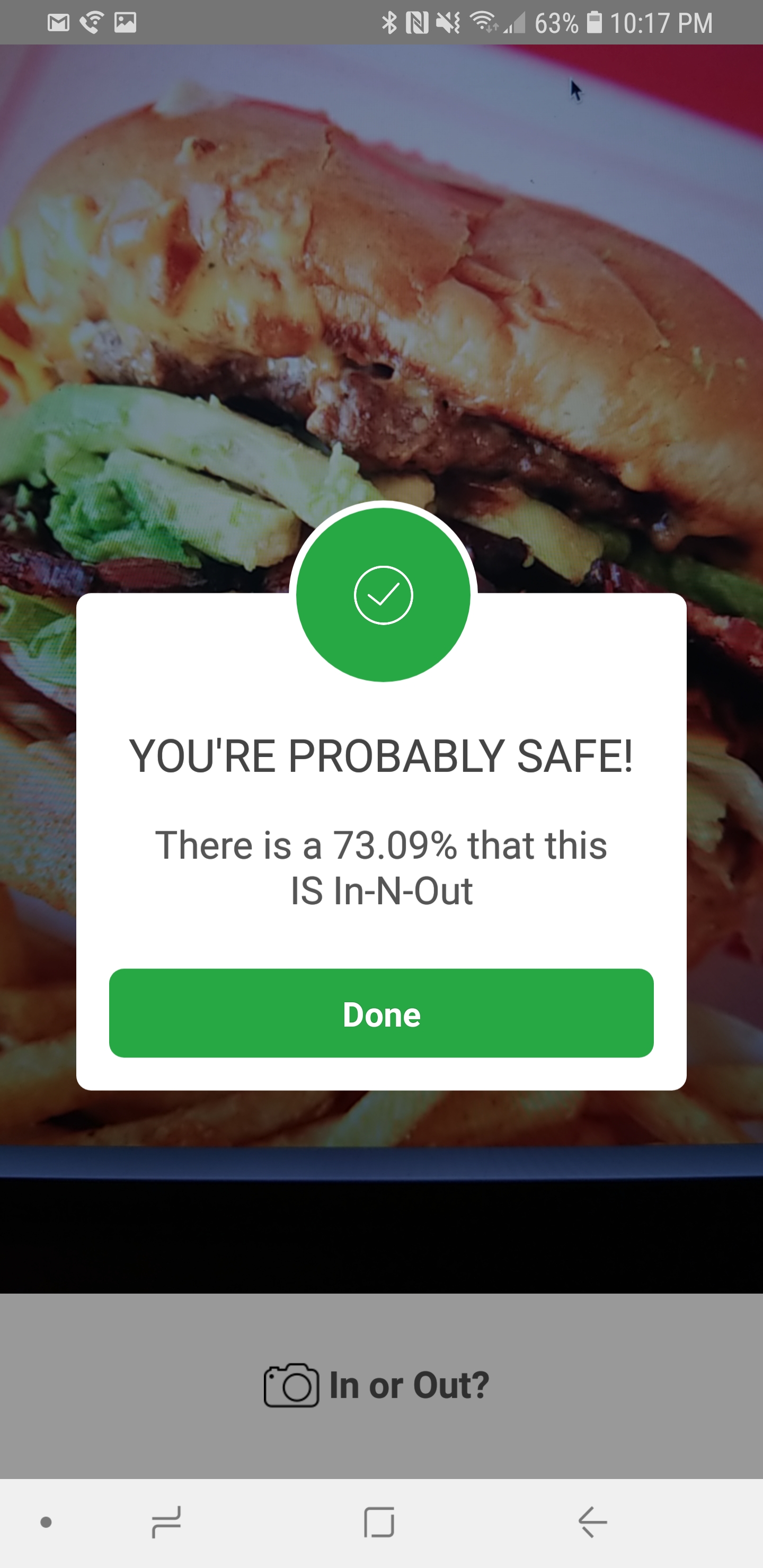

How it works:
- Use your phone to take a picture of your burger and the application will tell whether it’s an In-N-Out, and therefore safe for consumption, or if you should run for the hills.
Some highlights:
- Built using the latest build of fast.ai v1 following the lesson 1 notebook as a template
- Single image predictions served via a dockerized flask API hosted at ZEIT.co (H/T @simonw) using the code described here to run a single uploaded image through my trained model
- Android application developed using React Native
Note: Sometimes the API call times out because it takes ZEIT awhile to wake up my API if it hasn’t been used for a while. But keep trying, and I promise you that eventually it will work 
If you give it a try I’d love to know how it worked (or failed).
37 Likes
Hi all,
I worked on using the Stanford Cars data-set, to predict make/model/year from an image of a car. I reached about 80% accuracy by using the resnet50 model along with the unfreezing and varying learning rate. Looking at the most confused, it seems that much of the confusion is associated with the same manufacturer and model or different model year, though there are some other errors that may be worth investigating more.
The notebook is here:

or in this repository:
Thanks,
Devon
Hi all…
Finally managed to do my guitar model prediction model… The built of a dataset took heaps longer than anticipated (and I only used 11 classes for now)…
Results look pretty impressive I have to say… The differences in these models is pretty subtle…
I wonder if it could tell replicas from originals or differentiate between 60s and 70s Strats etc. …
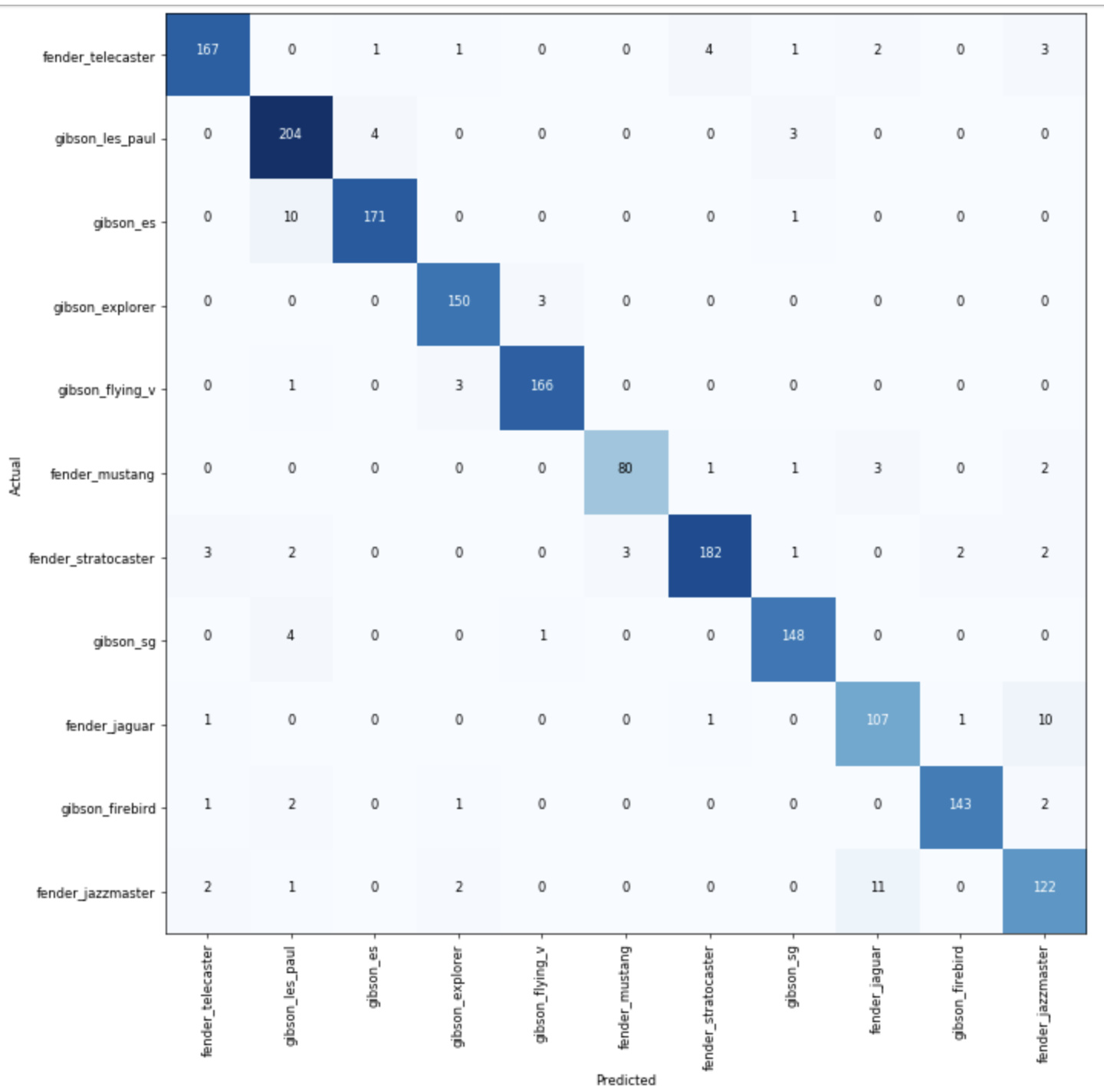
6 Likes
I had bad luck with birds and flowers, now I tried sounds and the results seems quite promising. I trained a classifier on spectrogram images generated from audio files that I downloaded from this Kaggle competition.
With a ResNet-34 and 4 epochs:
Total time: 36:42
epoch train_loss valid_loss error_rate
1 2.823842 1.935167 0.541053 (27:39)
2 1.968809 1.414007 0.408421 (03:00)
3 1.570557 1.216676 0.344211 (03:01)
4 1.380666 1.171882 0.330526 (03:01)
The top losses are

The confusion matrix looks OK
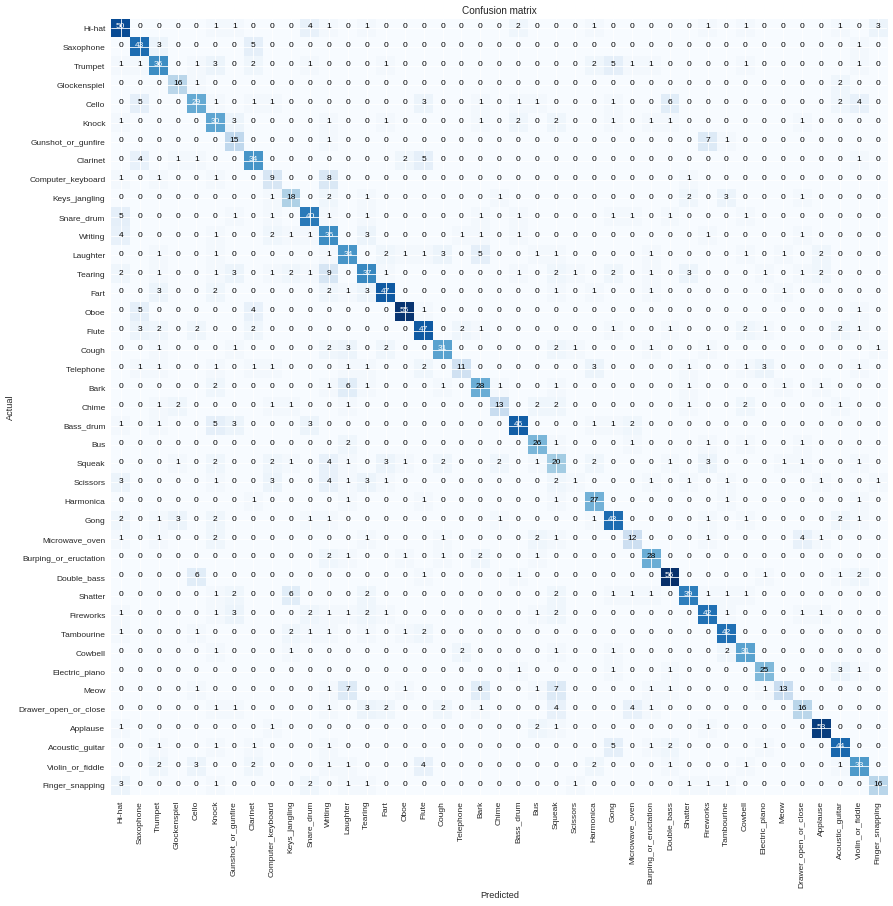
After unfreezing and choosing a good slice of learning rates, I got even better results:
Total time: 25:07
epoch train_loss valid_loss error_rate
1 1.272060 1.071349 0.293684 (03:08)
2 1.148295 0.994182 0.280526 (03:09)
3 1.040785 0.941049 0.264737 (03:08)
4 0.834645 0.837393 0.224737 (03:08)
5 0.664606 0.752477 0.205789 (03:08)
6 0.499639 0.716157 0.198421 (03:08)
7 0.399242 0.692799 0.188421 (03:07)
8 0.339768 0.671222 0.184737 (03:08)
Jupyter notebook - link
8 Likes
Hi All,
After a lot of pain and persisting through it, finally able to run a couple of experiments on the google audioset.
Here is the notebook to work on google audioset data. At a high level, audioset data contains human annotated labels (based on audio) in various youtube videos almost~2M. The annotation data has links to these videos, labels and the 10s clip in the video used. So we need to download the relevant youtube videos to prepare the dataset. This took a lot of time for me even with multiprocessing. Any suggestions on how to improve this are welcome.
Post download of data, below notebooks are used to convert audio clips to images of spectrogram images(thanks to @etown for the code) and run two experiments
-
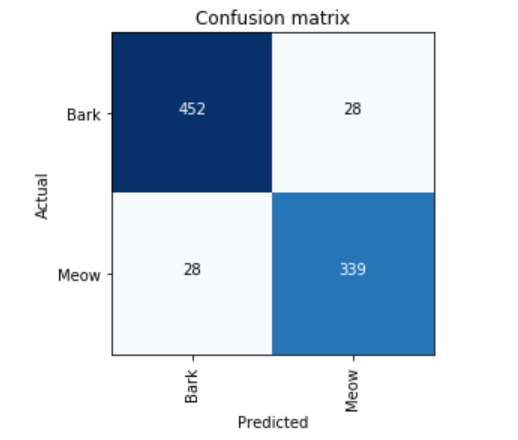
Dog Bark vs Cat Meow - Had close to 4.5k audio samples and ~5GB of data. Got an accuracy of 93%.
-
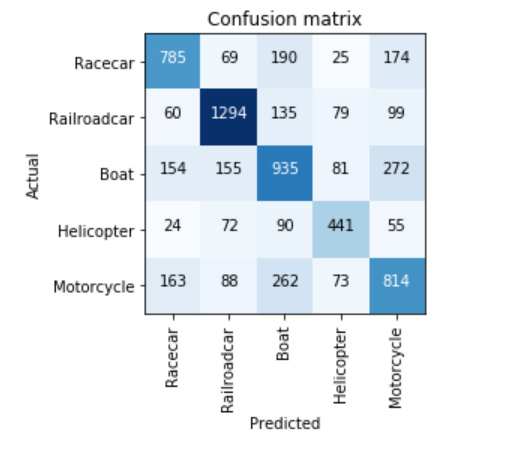
Boat vs Motorcycle vs Racecar vs Helicopter vs Railroadcar - Even for just five classes, this dataset turned out to be too huge with ~33k audio clips. Post downloading, the 10s audio clips turned to around ~45GB of wav files. So it was a bit challenging to download the data given the huge network overhead
Coming to the results, the accuracy is around 66% with both resnet 34 and 50.
Also the model is grossly overfitting when training all the layers.
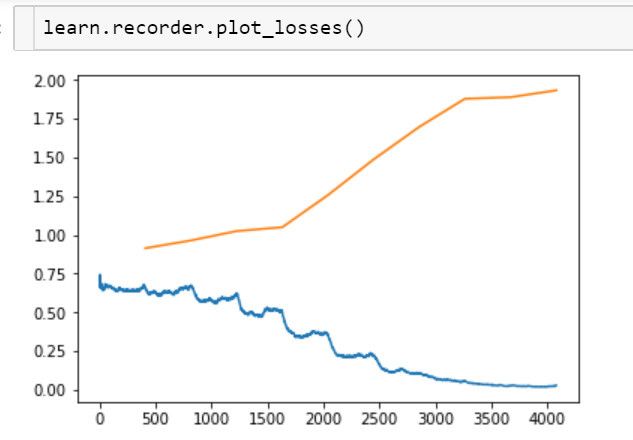
Will look to improve upon this and avoid overfitting based on the next lessons
4 Likes
I have started my Batik classification. Batik is Indonesia’s ancient dyeing technique for cloth. For the first attempt I use just a small batik dataset contains only 300 pictures split in to 50 types of Batik cloth. Each cloth is captured to as much as six random images and then resized to 128x128 pixels size in JPEG format.
It seems that this small dataset with 50 classes is not really a challenge, since both Resnet models achieved accuracy of 100% after just few epochs.


An here is the notebook: https://github.com/cahya-wirawan/FastAI-Course/blob/master/lesson1-batik-1.ipynb
The next step would be to find more comprehensive Batik dataset, which is maybe the biggest challenge it self
4 Likes
Following the examples of previous works with building web API, I am trying to create something similar using Quick Draw dataset.
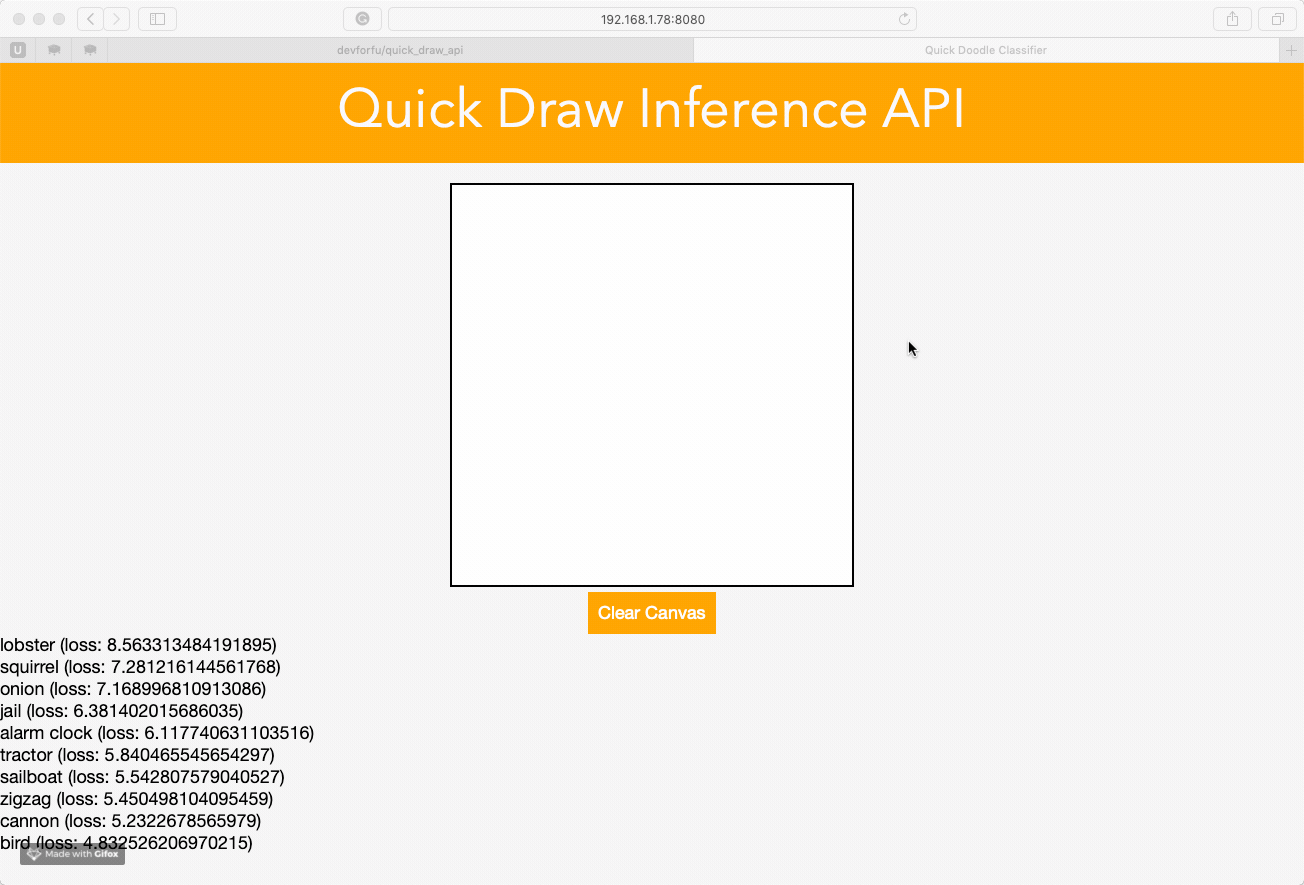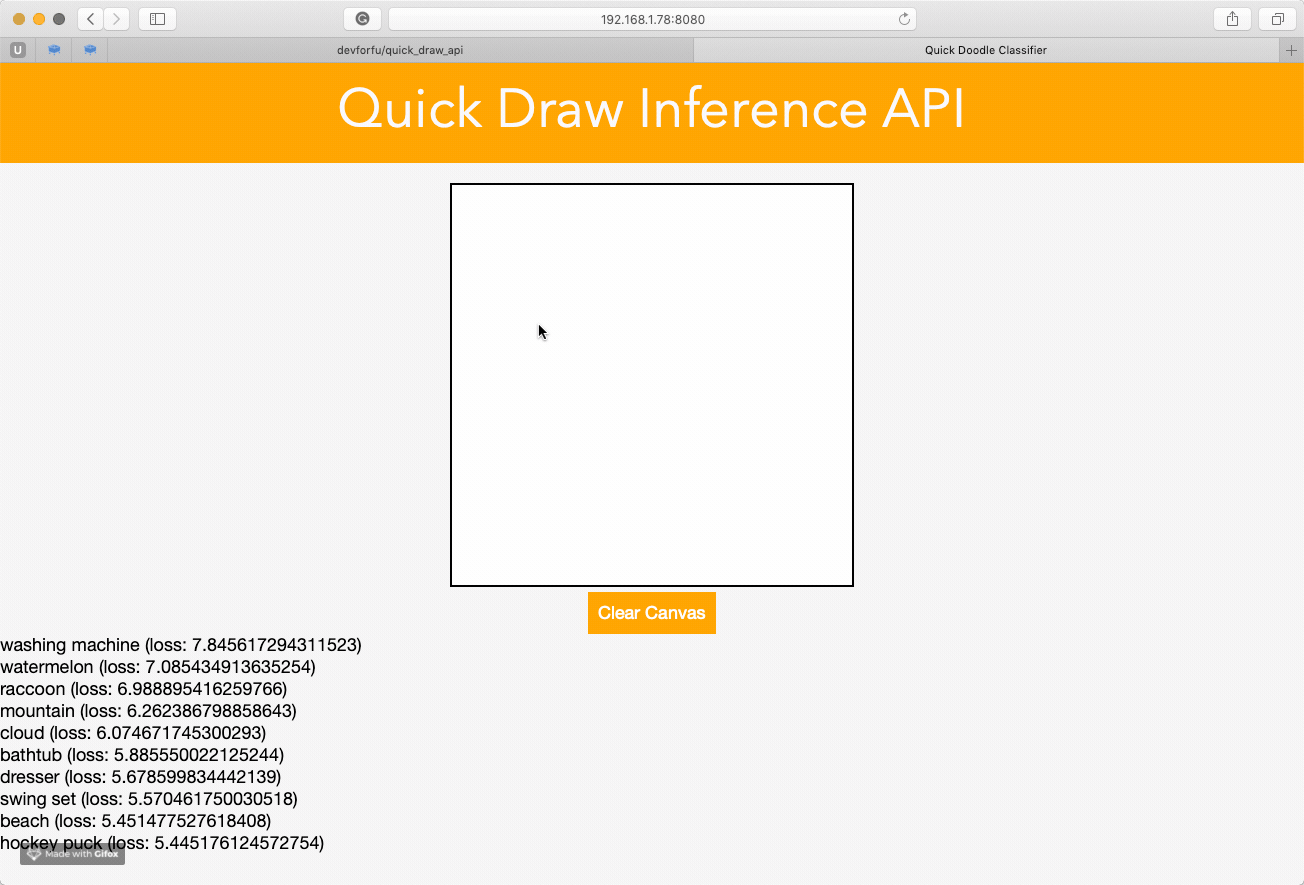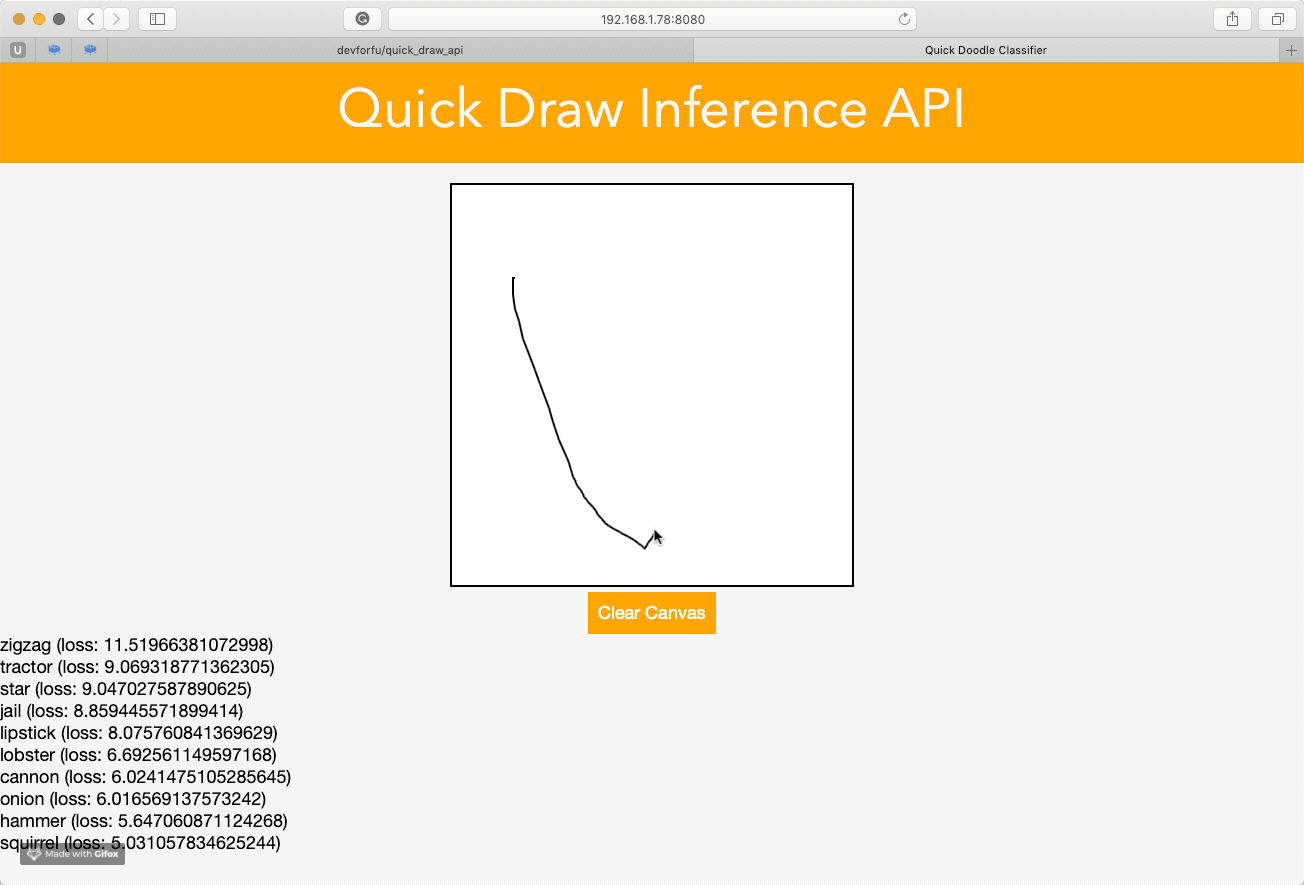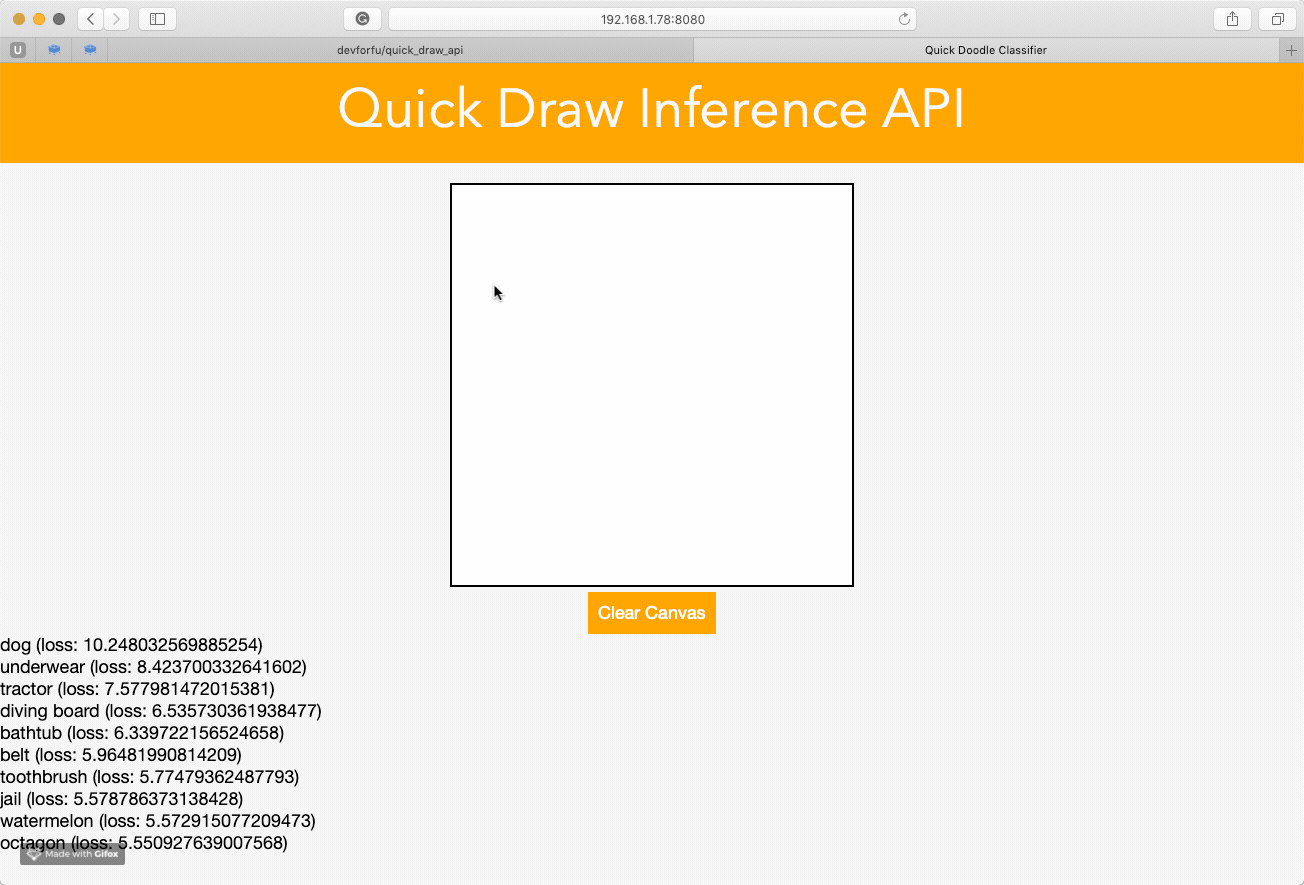
I’ve trained the model on a small subset of data during a couple of epochs, so the quality of predictions is rather pathetic: it works well in recognizing zig-zags only  However, I guess it is possible to do much better if train for a longer period and use more data, and deeper architecture.
However, I guess it is possible to do much better if train for a longer period and use more data, and deeper architecture.
Here is a link to the repository. In general, it just creates a Starlett app and serves a simple page with model waiting for an image. I guess I’ll deploy it using Now or something when having a better quality of the model.
28 Likes
Hi All
I tried the ConvLearner against the Stanford Car Dataset that consists of 196 classes. I used only the train folder and used the fastai library ImageDataBunch.from_csv for the labels. That was a good learning as I failed a few times before I got it right. I tried it on the Resnet34 model and got an error rate of 44% after running fit_one_cycle(4) two times.
Then I tried Resnet50 and ran fit_one_cycle(5) two times and then fit_one_cycle(15) once. I finally got an error rate of 18%. Not sure if this is good but wanted to try this on a dataset where the number of classes are plenty. The link to my notebook is here.
1 Like
Hi all,
I have trained a Resnet50 model on Fisheries Monitoring data.
This was a detection as well as classification competition, so from the very beginning, I knew that model will overfit and the obvious thing happened.
Experimented with the model, finetunned it, but ended up with train_loss: 0.143552 , valid_loss : 0.547791 and an error_rate of 9.76%
One question, I was getting different learning rate graphs in In [29]: and In [45]: (See my fisheries_monitoring notebook) , though I was running learn.recorder.plot() immediately after loading my resnet50_stage_1 model both the times. Why this unusual happening?
Thats pretty impressive results.
Audio classification shouldn’t be straight forward using the lesson1 model as the data is so different from the images ResNet saw in ImageNet - please share your notebook if you wish to, I m curious.
good work regardless 
1 Like
Hi guys,
While training image classifiers over the week, I found it a bit difficult to get my model’s prediction on a single image or a bunch of images. So, I created a small library which takes a FastAI Learner and creates a web-based UI where you can upload one more images and check your model’s predictions. Here’s how it works:
Install the library via pip:
pip install servefastai --upgrade
It just takes one line of code to serve a FastAI Learner:
from servefastai import serve
serve(learn) # learn is a FastAI Learner object
Then navigate to http://PUBLIC_IP:9999 in a new tab, where PUBLIC_IP is the external public IP of the machine where you are running
You’ll see a UI like this:
Once you select some files from your computer and press ‘Submit’, you’ll see a new page with the predictions:
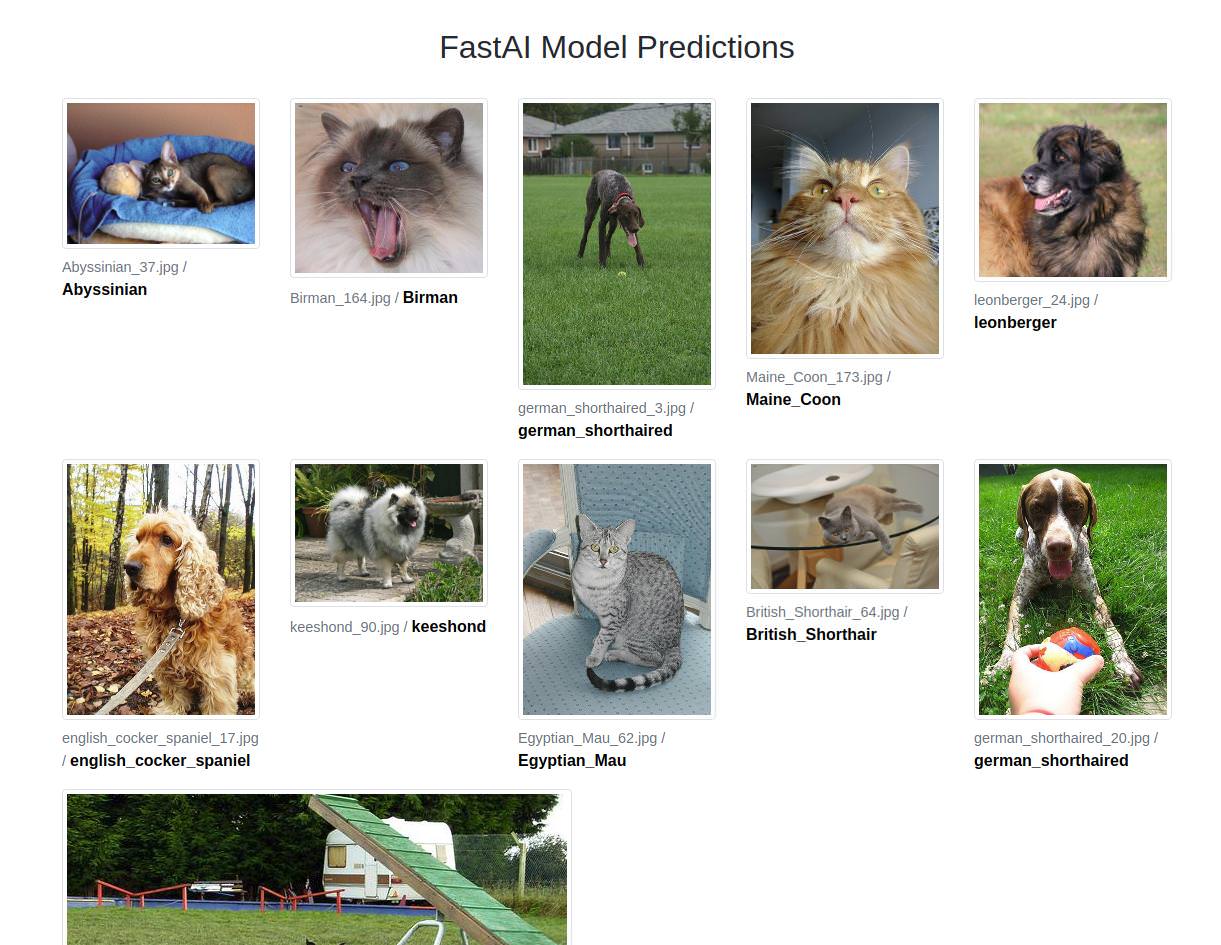
And that’s it! Hope it helps. The code is open source: https://github.com/aakashns/servefastai
Here’s a video demo if you need it: https://www.youtube.com/watch?v=xwN7arEgvBg
41 Likes
Here’s my work for the week:
I could be able to build a classifier to identify 10 different car models with an accuracy of 98%. This is using 100+ images for each car model.
Initial I got some accuracy between 80-90%.
Then I did a simple modification to my images. Have a look at below:

Usually an image of vehicle is a rectangle. Fastai does center cropping and that’ll hide some details from the classifier. So, I manually created crops for each and every original images as above.
After I used those images, the accuracy went really high.
Here’s the complete story behind this classifier( including how I download images, publish my datasets and key ideas behind this)
And here’s the notebook.
Anyway, I’m totally noob to this kind of work.
May be I might be doing something wrong.
If so, help me to figure it out.
6 Likes