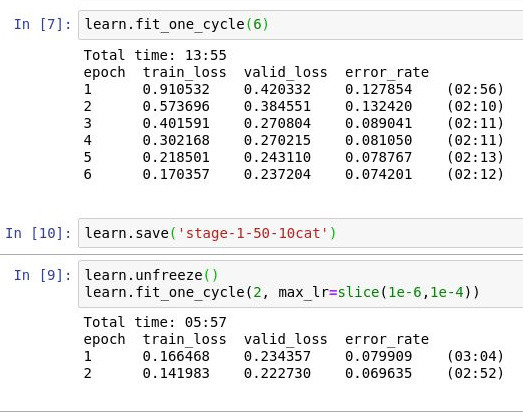
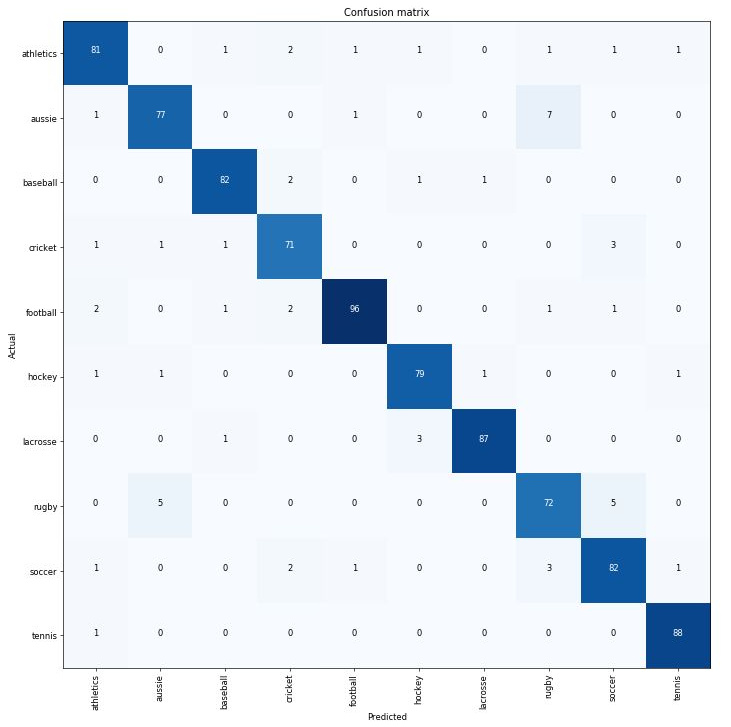
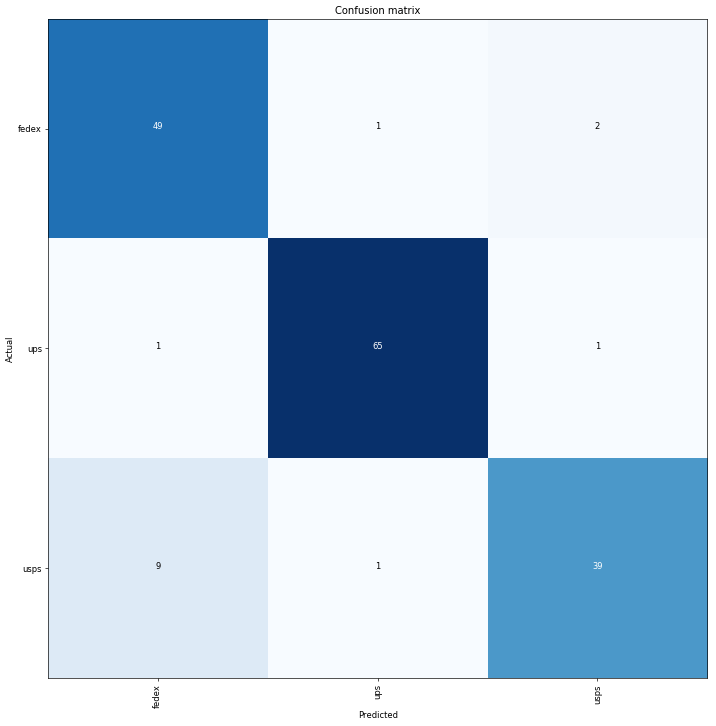
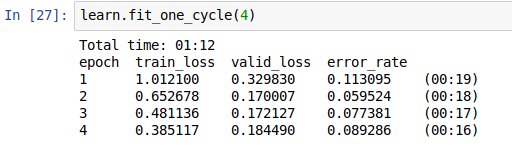
I’ve started working on Quick Draw competition dataset, here is a notebook with my attempt to train a simple classifier based on resnet34.
Here is a notebook with an analysis of a trained model. Or, I would say the first steps, I have out-of-memory errors (RAM) when trying to use model interpreter class. The training process is implemented as a standalone script in the same folder.
Nothing fancy I would say, the main interesting thing here is that I am generating images on the fly from strokes instead of saving them onto disk. The main reason is to save time because I am training the model on a small subset of the data (340,000 images, 1000 per category), and a huge bunch of images would occupy a lot of space on the disk.
Here is a fragment of the dataset class I’ve created:
@fastai_dataset(F.cross_entropy)
class QuickDraw(Dataset):
img_size = (256, 256)
def __init__(self, root: Path, train: bool=True, take_subset: bool=True,
subset_size: FloatOrInt=1000, bg_color='white',
stroke_color='black', lw=2, use_cache: bool=True):
subfolder = root/('train' if train else 'valid')
cache_file = subfolder.parent / 'cache' / f'{subfolder.name}.feather'
if use_cache and cache_file.exists():
log.info('Reading cached data from %s', cache_file)
# walk around to deal with pd.read_feather nthreads error
cats_df = feather.read_dataframe(cache_file)
else:
log.info('Parsing CSV files from %s...', subfolder)
subset_size = subset_size if take_subset else None
n_jobs = 1 if DEBUG else None
cats_df = read_parallel(subfolder.glob('*.csv'), subset_size, n_jobs)
if train:
cats_df = cats_df.sample(frac=1)
cats_df.reset_index(drop=True, inplace=True)
log.info('Done! Parsed files saved into cache file')
cache_file.parent.mkdir(parents=True, exist_ok=True)
cats_df.to_feather(cache_file)
targets = cats_df.word.values
classes = np.unique(targets)
class2idx = {v: k for k, v in enumerate(classes)}
labels = np.array([class2idx[c] for c in targets])
self.root = root
self.train = train
self.bg_color = bg_color
self.stroke_color = stroke_color
self.lw = lw
self.data = cats_df.points.values
self.classes = classes
self.class2idx = class2idx
self.labels = labels
self._cached_images = {}
def __len__(self):
return len(self.data)
def __getitem__(self, item):
points, target = self.data[item], self.labels[item]
image = self.to_pil_image(points)
return image, target
def to_pil_image(self, points):
canvas = PILImage.new('RGB', self.img_size, color=self.bg_color)
draw = PILDraw.Draw(canvas)
for segment in points.split('|'):
chunks = [int(x) for x in segment.split(',')]
while len(chunks) >= 4:
line, chunks = chunks[:4], chunks[2:]
draw.line(tuple(line), fill=self.stroke_color, width=self.lw)
image = Image(to_tensor(canvas))
return image
I’ve tried to make dataset class compliant with fastai but I am not sure if it works as expected. I guess that some learn methods could fail on my dataset class.
The work is still in progress. Next, I am going to take a bigger subset of data, and probably convert strokes into images files. Do you think that reading files from SSD could be performed faster than generating b/w 256x256 images dynamically?
Also, I am trying to play with iMaterialist Furniture dataset, and getting a lot of image downloading faults. I am using this script to download a single image. It uses concurrent workers, VPN proxy, and requests lib but still has a lot of faults. I guess it is not a big deal to skip some files from the training dataset but would like to have all samples from the test.