This is a wiki post - feel free to edit to add links from the lesson or other useful info.
I tested some image augmentations on my HaGRID Classification 512p no_gesture 150k hand gesture dataset using miniai. I decided to try the TrivialAugmentWide transform mentioned in this lesson as well. I found the results interesting.
I used a random (same seed for all) subset of 63,000 images for the training set and 7,000 for the validation set. I fine-tuned the pretrained resnet18d model from the timm library for five epochs.
I first tested the random square copy from lesson 18.

I then tried a different approach that instead copied random pixels.

Next, I tried combining the two transforms.

The random pixel transform ended with the highest validation accuracy (barely). The trivial augmentation transformation might have caught up eventually. However, it ended well behind the others after five epochs. That is not surprising, given its random augmentations can be extreme.
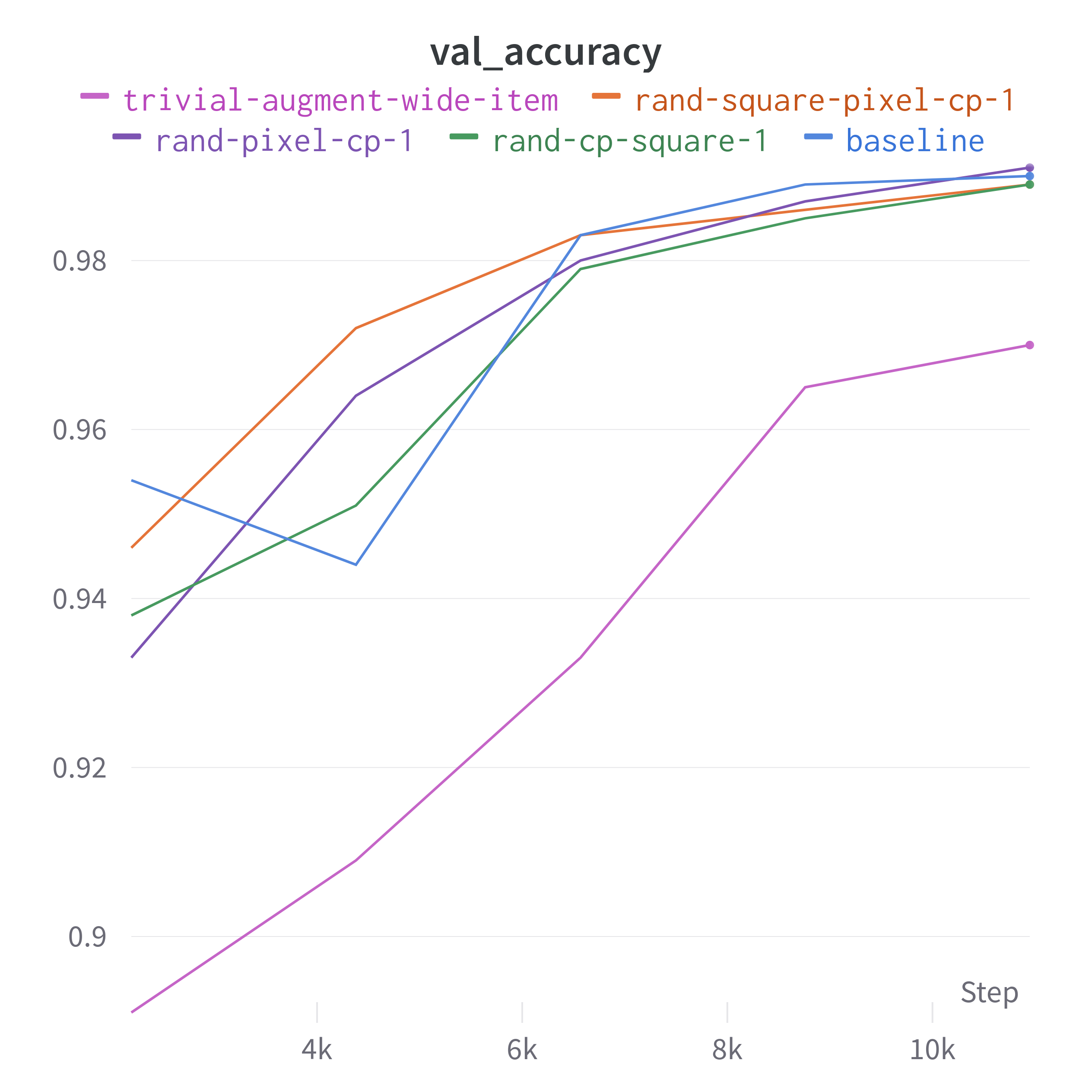
What did surprise me was how it performed on the remaining 78,908 images from the dataset I used as a test set (no augmentation inference). The random pixel copy transform only did better than the no augmentation baseline, while the trivial augmentation did far better than the others.
| Augmentation | # Wrong | Accuracy |
|---|---|---|
| None | 768 / 78908 | 99.0267% |
| RandomSquareCopy (Batch) | 698 / 78908 | 99.1154% |
| RandomPixelCopy (Batch) | 733 / 78908 | 99.0710% |
| RandomSquarePixelCopy (Batch) | 722 / 78908 | 99.0850% |
| TrivialAugmentWide (Item) | 597 / 78908 | 99.2434% |
4 Likes
Might be worth comparing the augmentations per class. Possibly not so much in this dataset as the images are similar between classes. But in the case of ImageNet etc the benefit of certain augmentations vary between classes.
1 Like
Hmm, I might check that tomorrow. Here is the class distribution for the missed test set images for the trivial augmentation model.
| Class | # Wrong |
|---|---|
| peace | 63 |
| no_gesture | 59 |
| one | 52 |
| like | 48 |
| four | 40 |
| palm | 39 |
| three | 35 |
| ok | 33 |
| fist | 30 |
| dislike | 27 |
| stop | 24 |
| stop_inverted | 24 |
| two_up | 22 |
| three2 | 21 |
| peace_inverted | 21 |
| call | 20 |
| rock | 18 |
| mute | 11 |
| two_up_inverted | 10 |
The no_gesture class has about 4x the number of sample images compared to the other classes in the dataset. It’s also worth noting the sample images vary significantly in quality, ranging from perfect samples to a small number of “I can’t even tell what it is”-quality images.
I forgot to save checkpoints for the random square copy and random pixel copy models, so I’ll need to rerun those.
1 Like
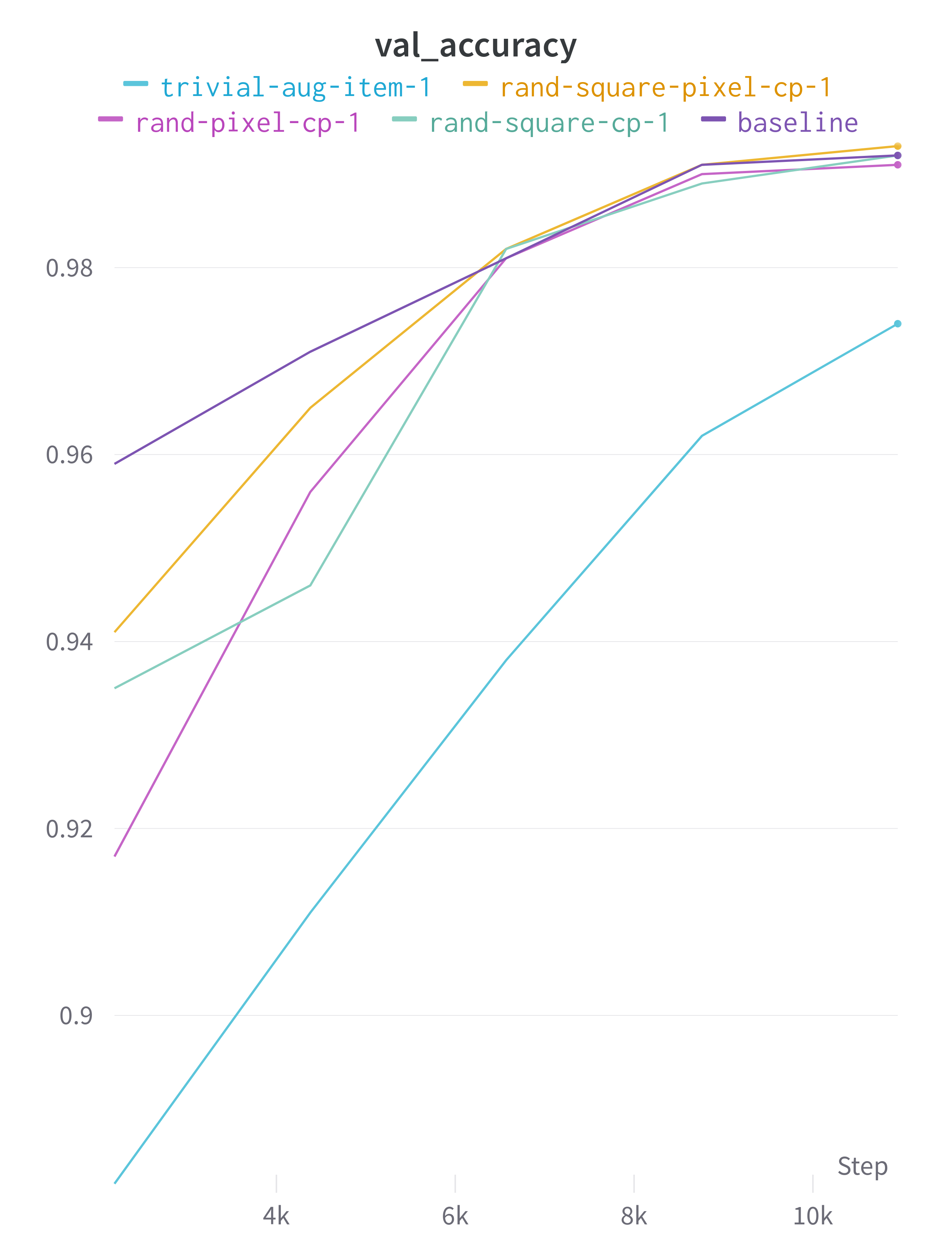
So, the trivial augmentation transform is not the best performing for all classes, despite having a decent lead overall.
| class | baseline | rand-pixel-cp-1 | rand-square-cp-1 | rand-square-pixel-cp-1 | trivial-aug-item-1 |
|---|---|---|---|---|---|
| call | 52 | 57 | 41 | 34 | 38 |
| dislike | 26 | 30 | 25 | 23 | 25 |
| fist | 50 | 38 | 30 | 43 | 29 |
| four | 56 | 51 | 36 | 32 | 39 |
| like | 55 | 49 | 50 | 45 | 37 |
| mute | 17 | 30 | 17 | 30 | 12 |
| no_gesture | 50 | 28 | 51 | 42 | 63 |
| ok | 38 | 49 | 39 | 52 | 38 |
| one | 58 | 54 | 60 | 63 | 37 |
| palm | 33 | 33 | 38 | 32 | 37 |
| peace | 64 | 60 | 84 | 93 | 64 |
| peace_inverted | 23 | 23 | 15 | 25 | 25 |
| rock | 49 | 35 | 39 | 29 | 29 |
| stop | 59 | 47 | 60 | 51 | 46 |
| stop_inverted | 25 | 25 | 16 | 11 | 17 |
| three | 48 | 59 | 61 | 61 | 52 |
| three2 | 19 | 14 | 24 | 23 | 31 |
| two_up | 42 | 42 | 33 | 39 | 42 |
| two_up_inverted | 24 | 27 | 25 | 21 | 12 |
| Total | 788 | 751 | 744 | 749 | 673 |
2 Likes
Since I already implemented the style transfer suggestion, I thought I’d see if I could use the same model from my style transfer notebook to colorize greyscale images.
Unfortunately, the more challenging task of colorizing images seemed too much for the little 393K parameter model. After some small-scale experiments, I decided to try bumping the number of inner res blocks from five to forty. That increased the parameter count to 3 million and gave some promising results.
Below are some samples from training on my pexels dataset for ten epochs at 296x296 with the VGG-16 model for perceptual loss. I also added the cross_convs discussed in this lesson. I probably should have left that for a separate experiment.



The subtle grid pattern in the output images does not appear in my style transfer outputs. I’m unsure if those are from adding the cross_convs or training for more epochs. Hopefully, it’s not the latter, as I need to train longer to get acceptable results.
Update: Well, it does not seem to be either the cross_convs or training for longer. Hmm, maybe I had it backwards, and it’s from not training long enough?
5 Likes
Your images are looking really great. Can you share your notebook please? I’m not seeing the grid pattern – can you paste a zoomed in section to show what you mean? In earlier courses we introduced some methods to deal with “checkerboard” artifacts so I might be able to help with this…
Hey Jeremy,
Here is a zoomed and interpolated example of the grid pattern.

I’ll upload my colorizing notebook to GitHub once the current training session finishes. I am currently testing with the convnext_nano model instead of the VGG-16 model for perceptual loss.
It is nearly identical to the notebook I shared for real-time style transfer in the “Share your work” thread. I only updated the dataset and loss classes for the colorizing task.
The PixelShuffle upscaling I currently use in the model typically resolves the checkerboard pattern issue. Although, I would love to test other upscaling methods as well. I picked the pixel shuffle method mainly for efficiency since the style transfer model is supposed to run in-game.
Looking at some of the checkpoint images from early in the training session for the style transfer task, it seems like the checkerboarding might be there. It’s harder to tell with those.
If they are present, it might just be that I need to train longer.
2 Likes
Using the convnext_nano model seems to have resolved the checkerboard artifact issue. So, that’s neat. I think it’s still technically there, but it’s so faint now I can barely perceive it, even at 5x zoom.



I’m unsure if I should try adding more layers to the model or training it for longer first. It seems to learn certain scenes faster than others.
Anyways, here is a link to the miniai version of the colorizing notebook.
Here is the non-miniai version used to generate the above sample images.
6 Likes
That’s an interesting discovery!
My only nit with the outputs at the moment is that they seem a little low on saturation. This is understandable, since the model will naturally tend towards predicting the mean, resulting in washed-out colors. Perhaps you can try some additional loss functions that might not have that tendency?
2 Likes
I was starting to wonder if it was the loss function. I added the weights and biases callback to get a better look at the loss progression. Here is a chart from a partial run.

These look great…!
I am unable to get the first model (The Basic section) to train at anywhere near the learning rate of 0.1. I tried varying a number of things to improve it but after about 5 epochs it was unstable and returning nan’s . To get it to work I had to reduce the learning rate to 0.005 at which value I obtained almost identical results.
Is anybody else having this problem or am I doing something wrong?
I had similar in the 24_imgnet_tiny notebook. I had to decrease the learning rate to 3e-2.
I’ve been experimenting with colourisation on the tiny imagenet dataset. I trained a tiny imagenet classifier model with greyscale versions of the images (to use as my pre-trained layers of the colourisation Unet). After 50 epochs the greyscale classifier model had 60.8% accuracy, which I thought was surprisingly good given the RGB original was 64.9% after 50 epochs.
These results are certainly not close to as impressive as those above that use large models pre-trained on other datasets as part of their loss function. I think it is interesting what can be achieved with a feature loss function using the classifier trained on tiny imagenet. I found using MAE (L1) for both pixel loss and feature loss gave slightly better results over MSE loss.
Predictions from the greyscale inputs on the top and the actuals/targets at the bottom:

2 Likes
Good to know it’s not just me. The later model with pre activation trained fine at the higher learning rate
Hey @jeremy hope your day is going well :). Quick question: what are the cadence of the lessons moving forward?
Each lesson now requires quite a bit of research, since it’s at or past the cutting edge of research. So we record lessons once we’ve reached a point we know what to say - we can’t really predict when that will be… ![]()
15 Likes
They’ve all been great so far…looking forward to them.