@jeremy I have been really enjoying this format. I am hoping they go on like this indefinitely.
1 Like
Thanks for the reply @jeremy ! The lectures have been fantastic, looking forward to the next one
Sounds like you need a new model? ![]()
Well, that lengthy experiment ended with less clear-cut results than I wanted. After iteratively cleaning the hand gesture dataset (I missed a bunch of bad samples when I first made the dataset), I retested the image augmentations by training on the full dataset (90% training, 10% validation) across different random seeds.
The TrivialAugmentWide transform had the highest validation accuracy across three of four random seeds, but the scores were too close to call.

Note: The custom-trivial-aug-1 randomly applies the rand-square-cp-1, rand-square-pixel-cp-1, or rand-pixel-cp-1, or no transform
I also ended each run by testing the models without augmentation on the entire dataset and only got a consistent winner across two seeds.
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 1 | rand-square-cp-1 | custom-trivial-aug-1 | baseline | rand-square-pixel-cp-1 | rand-pixel-cp-1 | trivial-aug-item-1 |
| 42 | custom-trivial-aug-1 | rand-square-cp-1 | baseline | rand-square-pixel-cp-1 | rand-pixel-cp-1 | trivial-aug-item-1 |
| 100 | rand-square-pixel-cp-1 | custom-trivial-aug-1 | baseline | rand-square-cp-1 | trivial-aug-item-1 | rand-pixel-cp-1 |
| 1234 | rand-square-pixel-cp-1 | baseline | rand-square-cp-1 | custom-trivial-aug-1 | trivial-aug-item-1 | rand-pixel-cp-1 |
However, that augmentation did not even have the best performance overall. The TrivialAugmentWide transform ended up performing the worst.
| custom-trivial-aug-1 | rand-square-cp-1 | rand-square-pixel-cp-1 | baseline | rand-pixel-cp-1 | trivial-aug-item-1 | |
|---|---|---|---|---|---|---|
| Mean | 235 | 238 | 247 | 255 | 312 | 313 |
- Mean: average number of incorrect predictions
Something I found interesting is that the trivial augmentation models initially performed far better during inference than the others. However, it lost that lead as I cleaned up the dataset. I wonder if the more extreme augmentations included with that transform help with a dirty dataset?
My takeaway from this experiment is that the square-copy transform delivers the best bang for the buck.
1 Like
Yes, same issue, resolved by lowering lr.
1 Like
I found that I needed to change one of the cells in notebook 25. Specifically the cell in the Cross-convs section where the model state dict is loaded I had to add an additional index as there seemed to be an additional nn.Sequential in the model that is being loaded. I used:
model.start.load_state_dict(pmodel[0].state_dict()) for i in range(5): model.dn[i].load_state_dict(pmodel[i+1][0].state_dict()) for o in model.dn.parameters(): o.requires_grad_(False)
Instead of:
model.start.load_state_dict(pmodel[0].state_dict()) for i in range(5): model.dn[i].load_state_dict(pmodel[i+1].state_dict()) for o in model.dn.parameters(): o.requires_grad_(False)
Which seemed to work
2 Likes
Thanks for another great lesson. I really enjoyed learning more about the UNET architecture in this lesson as well as the super-resolution technique. It was really great seeing the UNET example coded up in pytorch along side the diagram from the paper.
2 Likes
Continuing on from Colourisation on Tinyimagenet, using the TinyUnet model architecture with cross convs from the lesson. I’ve experimented with erasing half of the image and attempting to train the U-Net to reconstruct it. I trained a classification model taking inputs of the half-erased images to use as the starting weights of the encoder part of the U-Net. Then trained for 300 epochs using L1 loss on the pixels and the perceptual loss from the same classification model used for Super Resolution loss function. I had to reduce the factor of the perceptual loss. Although, the predicted image clearly isn’t as good as the target, it was better than I’d expected it to be.
Input:

Prediction:

Target:

To experiment further and with larger images and to do that relatively quickly, I decided to try out Jeremy’s Imagenette dataset. I trained a classifier model on 64x64 pixel images, then another classification model that took the half-erased images as inputs. Then I trained a U-Net model to reconstruct the images. I then used the U-Net model trained with 64x64 pixel inputs as the starting weights for the 128x128 pixel model and trained that.
Predicted images:

I tried colourisation on the imagenette dataset as well. Training a classifier model on 64x64 pixel images, then another classification model that took the greyscale images as inputs for the perceptual loss. Then I trained a U-Net model to colourise the images. As before, I then used the U-Net model trained with 64x64 pixel inputs as the starting weights for the 128x128 pixel model, then the U-Net model trained with 128x128 pixel inputs as the starting weights for the 256x256 pixel model.
Predicted colourised images:

I also tried (x2) Super Resolution on the imagenette dataset. Training initially on 64x64 pixel images as in the lesson’s notebook to enhance the images. Once again, I used the U-Net trained with 64x64 pixel inputs as the starting weights for the 128x128 pixel model, then the U-Net trained with 128x128 pixel inputs as the starting weights for the 256x256 pixel model.
Input left, predicted centre, target right:

Then I made it more challenging repeating the same with x4 super resolution from 64x64 inputs to 256x256 outputs. Again, input left, predicted centre, target right:

I find it really interesting what can be achieved with the TinyUnet models and a classifier model based perceptual loss pre-trained only on the same dataset.
6 Likes
One concept I’m not following is why the model loaded for perceptual loss, inettiny-custom-25 works. Conceptually, adding the feat_loss for a classifier trained on something not related is a mystery to me.
def comb_loss(inp, tgt):
with torch.autocast('cuda'):
with torch.no_grad(): tgt_feat = cmodel(tgt).float()
inp_feat = cmodel(inp).float()
feat_loss = F.mse_loss(inp_feat, tgt_feat)
return F.mse_loss(inp,tgt) + feat_loss/10
If anyone has a explanation, I would appreciate it.
Hi John,
i do not understand why this error appears…could you please explain? i see 3 times more layers than original model
Thank you!
Hi, I can’t remember of the top of my head but will have a look tomorrow and check. In essence I recall that there is one extra sequential model wrapped around, which means you have to index in further but I’ll check the details
thank you so much for your reply!
From what I can see the TinyUnet model is trying to load weights for the start part of the model, which is a ResBlock. The pmodel is a sequential model that starts of with a ResBlock, then has the other parts of the model. In order to access the indivisual parts of the classifier the pmodel[i] indexes into the part of the model that is needed for the relevant part of the new model (as you can see after the start block it then progresses through the dn blocks in the same fashion).
Hopefully that makes sense
1 Like
cool, thank you very much, John!
Hi Chris,
Could you please help me with an explanation? How do you give the trained super-resolution 64x64 model as input for the start of UNET for 124x124? they have different sizes…
i cannot do: model.start.load_state_dict(pmodel[0].state_dict())
Thank you!
Greetings
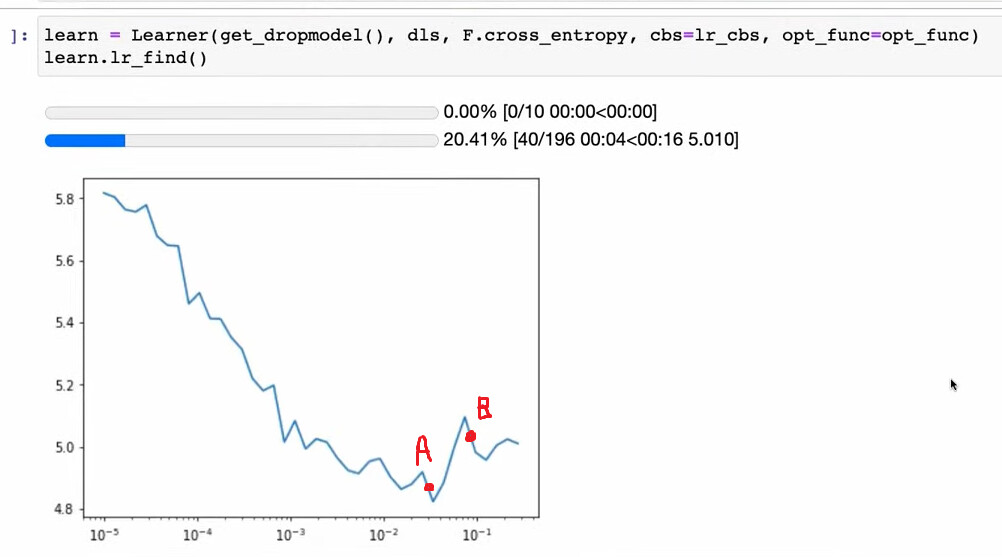
I have a question about the LR finder output in this lesson. Is the reason to pick point B not point A that it’s simply a higher learning rate with the same steepness on the LR finder output curve so you’d converge to a solution faster?
Or does it kind of not matter and 5e-2 is not that different from 1e-1?
1 Like
@jeremy Apologies, I hope it’s okay to tag you, please let me know if not.
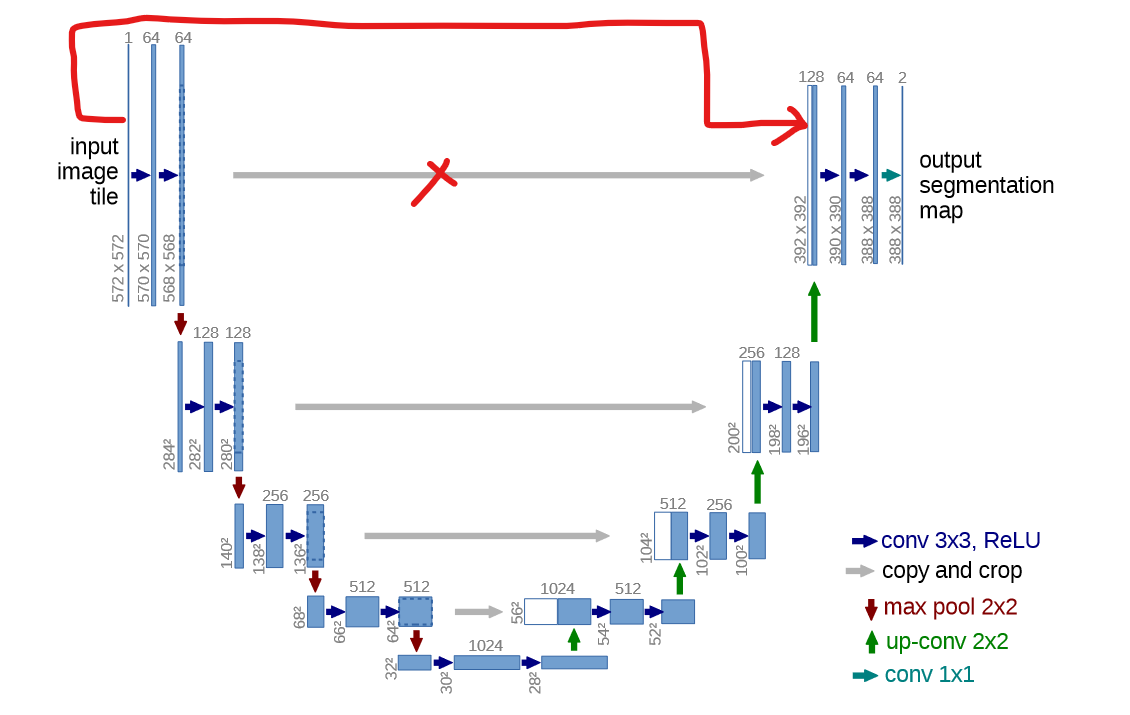
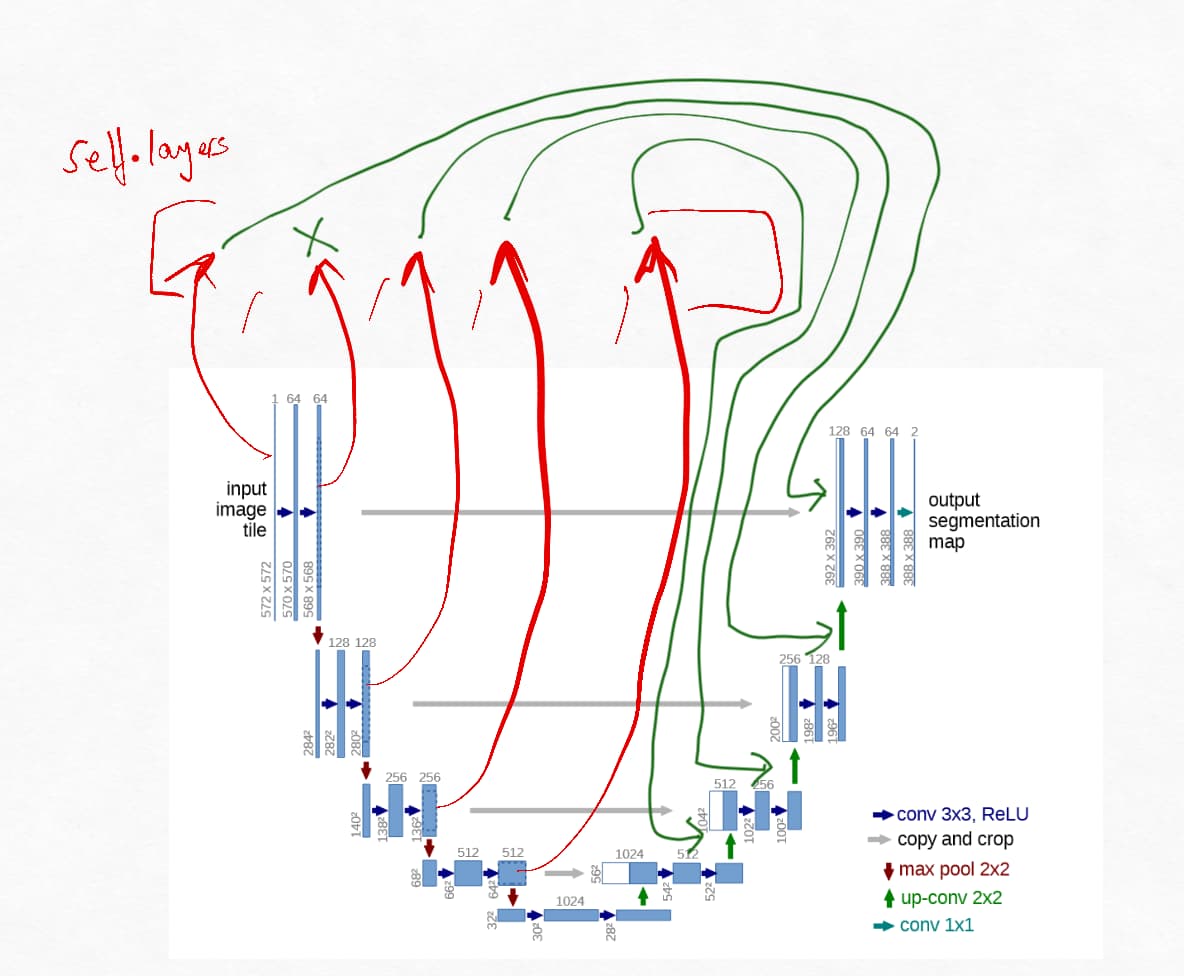
Is it just me or is what the Unet code in notebook 23 doing the skip connections a bit differently than the the paper? I’ve marked in red what I think is happening.
The thing is you also use this as a feature (therefore not a bug) when you’re trying to initialize weights and get the model to start with outputting the original input directly so I feel like this is intentional but I was wondering why this change from the original architecture?
Effectively here is the data stored in layers array
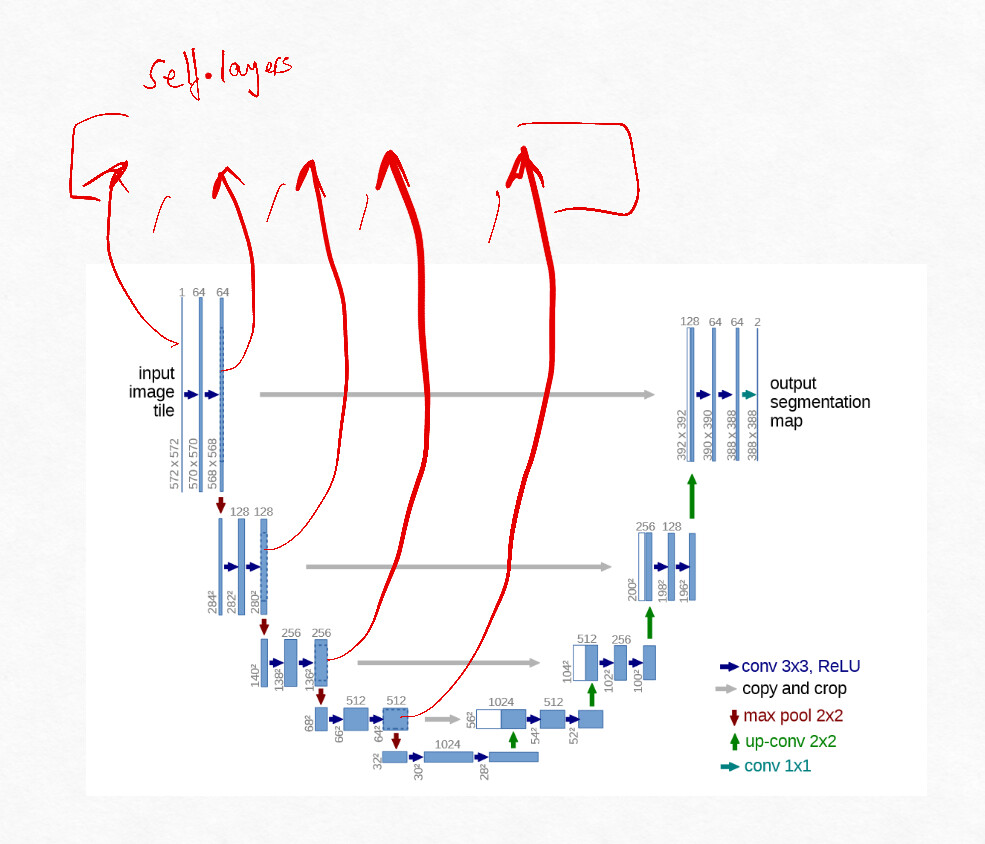
And this is how it’s used, interestingly the second entry will always go unused
I’d prefer you didn’t - thanks for checking.
1 Like
Of course, totally understandable. Apologies again!