Hi all,
I’ve been working on adapting lessons 8-9 (primarily pascal-multi) to work with a new dataset and object detection challenge, namely detecting food-producing trees (like coconuts) from an aerial view (drones in this case; would work with satellite imagery too).
I wanted to:
- change the image set and classes from PASCAL or COCO to something appreciably different (top-down detection of coconut trees for now, other tree types and building/road segmentation later),
- adapt raw aerial imagery data and annotations of a geospatial nature to the correct input formats for object detection,
- practice pre-processing generally messier data than the usual kaggle challenge or academic dataset
- most importantly, trying to achieve great performance with fastai!
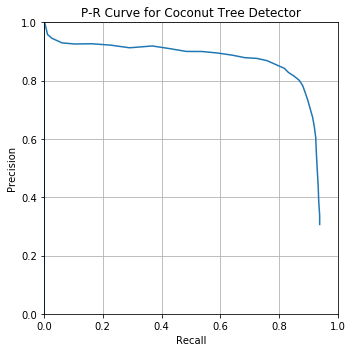
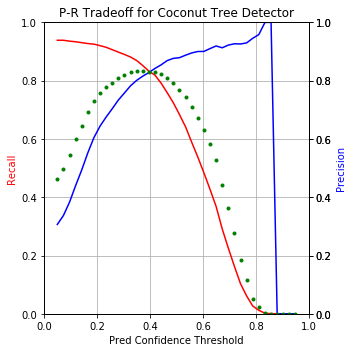
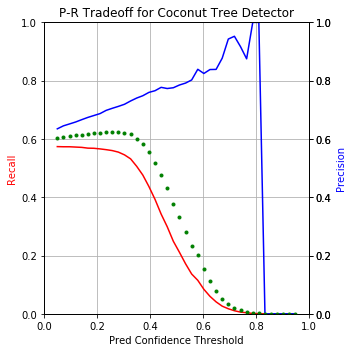
Here’s the performance punchline upfront:
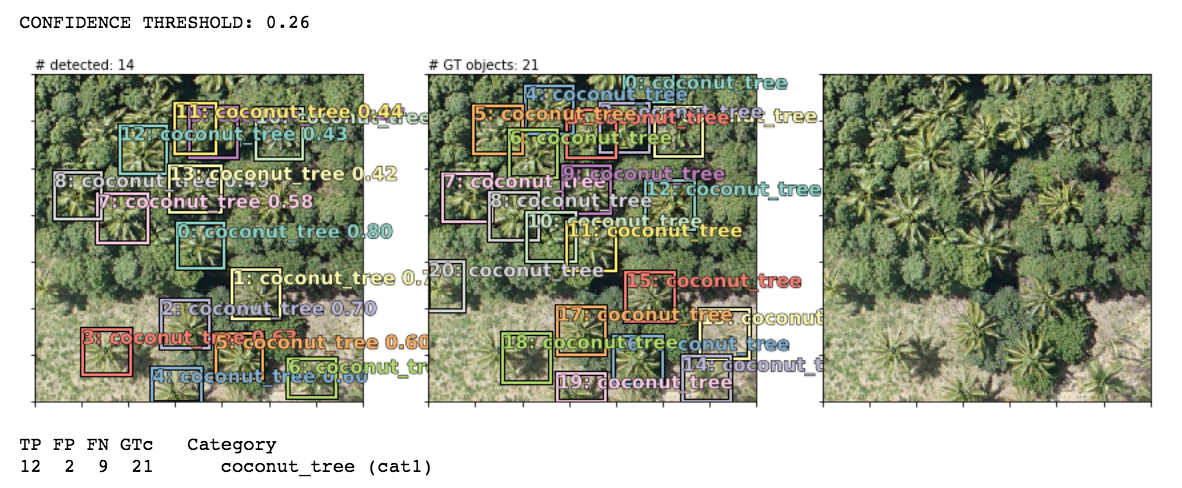
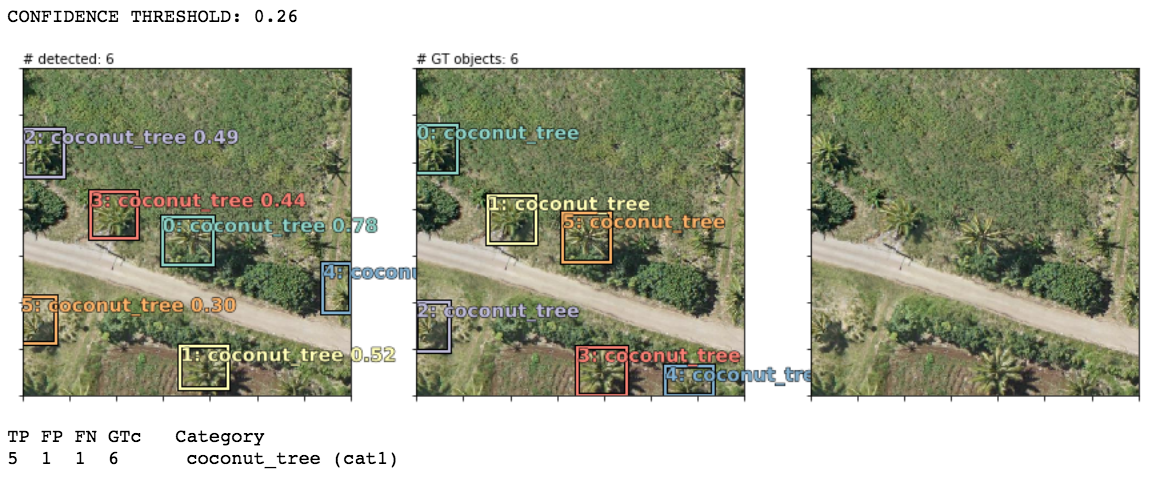
Using nearly default settings from the pascal-multi model, some predictions (column 1) compared to ground truth bboxes and the plain image (columns 2 and 3):

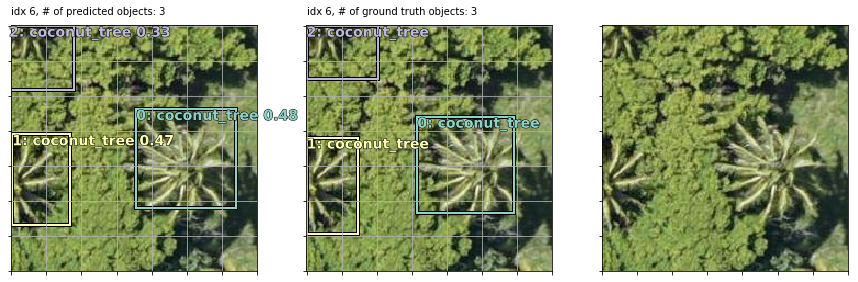
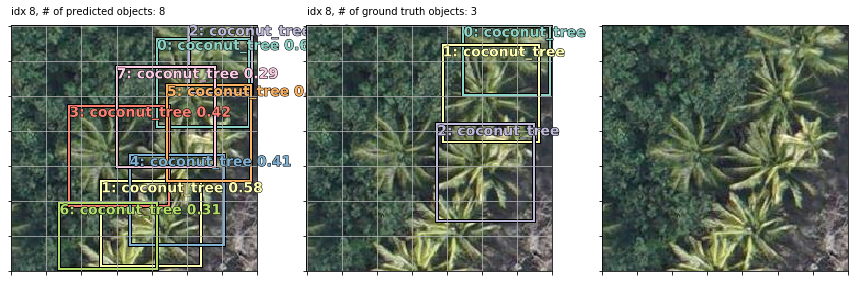

Note that in the last 2 examples, the model correctly detected coconut trees which were incorrectly unlabeled by human annotators in the supposed “ground truth”!
Also note that my bounding boxes labels are synthetic: I auto-created them as 90x90 squares (or rectangles at the borders if a coord <0 or >224) using the human-annotated point coordinate of each tree as the bbox center. This works well enough since most trees are roughly the same size but occasionally they are bigger or smaller than 90x90. In some examples, it seems like the model actually does a better job of finding the “real” bbox of each tree than my synthetic bboxes but that’s not correctly baked into the loss score optimization so perhaps they’re less “correct” (w.r.t. the loss function) predictions that happen to match up with the real-world tree sizes. OR maybe they are well-trained predictions because the vast majority of trees do size up to be ~90x90 so the occasional larger or smaller tree isn’t enough of a penalty to throw off the overall training objective.
I’ve put my latest model notebook, ready-to-train dataset, and preprocessing workflow docs in a github repo. More details and documentation available there for anyone who’d like to take this model and dataset for a spin or adapt it to their own work:
direct link to nb: coconuts/coconuts-model-fastaimulti-base-0329-public.ipynb at master · daveluo/coconuts · GitHub
direct link to dataset d/l (4036 jpeg images + mc and mbb label csv files, 50MB): Dropbox
download latest training weights (so far) to go straight to inference (93MB, put into your models/ folder and learn.load() in the final step before NMS): Dropbox - File Deleted - Simplify your life
Notebooks are early Works-In-Progress (in need of refactoring among other things) so I would appreciate any and all questions, suggestions, collaboration!
I plan to keep building on this dataset and improving models for more/better multi-object detection. The dataset is also applicable for later lessons like semantic segmentation of building and road footprints (those pixel-level annotations are also available as shp files so they need preprocessing).
cheers,
Dave
btw, for those interested in learning more about this work, from https://werobotics.org/blog/2018/01/10/open-ai-challenge/ :
Disasters in the South Pacific are a reality. In the past 10 years, major Cyclones have seriously affected hundreds of islands across Fiji, Tonga, Vanuatu and Samoa to name a few; disrupting millions of lives and causing millions of dollars of damage. Many of the countries in the Pacific region are also exposed to other high risk disasters including earthquakes, tsunami, storm surge, volcanic eruptions, landslides and droughts, not to mention the growing threat of Climate Change. What does all this have to do with Artificial Intelligence (AI)?
Aerial imagery is “Big Data” challenge. We’ve observed this challenge repeatedly over the years, and most recently again during our work with UNICEF in Malawi. It took hours to manually analyze just a few hundred high-resolution aerial images from the field. In 2015, following Cyclone Pam in Vanuatu, it took days to manually analyze thousands of aerial images, which is why we eventually resorted to crowdsourcing. But this too took days because we first had to upload all the imagery to the cloud. I started working on this Big (Aerial) Data problem back in 2014 and am thrilled to dive back into this space with friends at the World Bank and OpenAerialMap (OAM). By “this space” I mean the use of machine learning and computer vision to automatically identify features of interest in aerial imagery.
Full details about the challenge and dataset: World Bank: Automated Feature Detection of Aerial Imagery from South Pacific - LIVE - Google Docs