Thanks for the additional ideas! I’m definitely planning to implement more stuff from retinanet and yolov3 and learn about FPNs so will keep posting with updates.
Now that we have working P-R curves and APs to benchmark and do more in-depth diagnostics per class and per image, it’ll be easier to evaluate if and how these changes help performance.
For example, I’ve been testing custom heads like using 7x7 grid cell (for more smaller anchor boxes) and different k combos to get better bbox localization and reduce False Positive rate. Haven’t been able to break our baseline mAP of 30% yet but this helps us investigate the model performance more granularly with sample images:

Or as class APs compared to baseline:
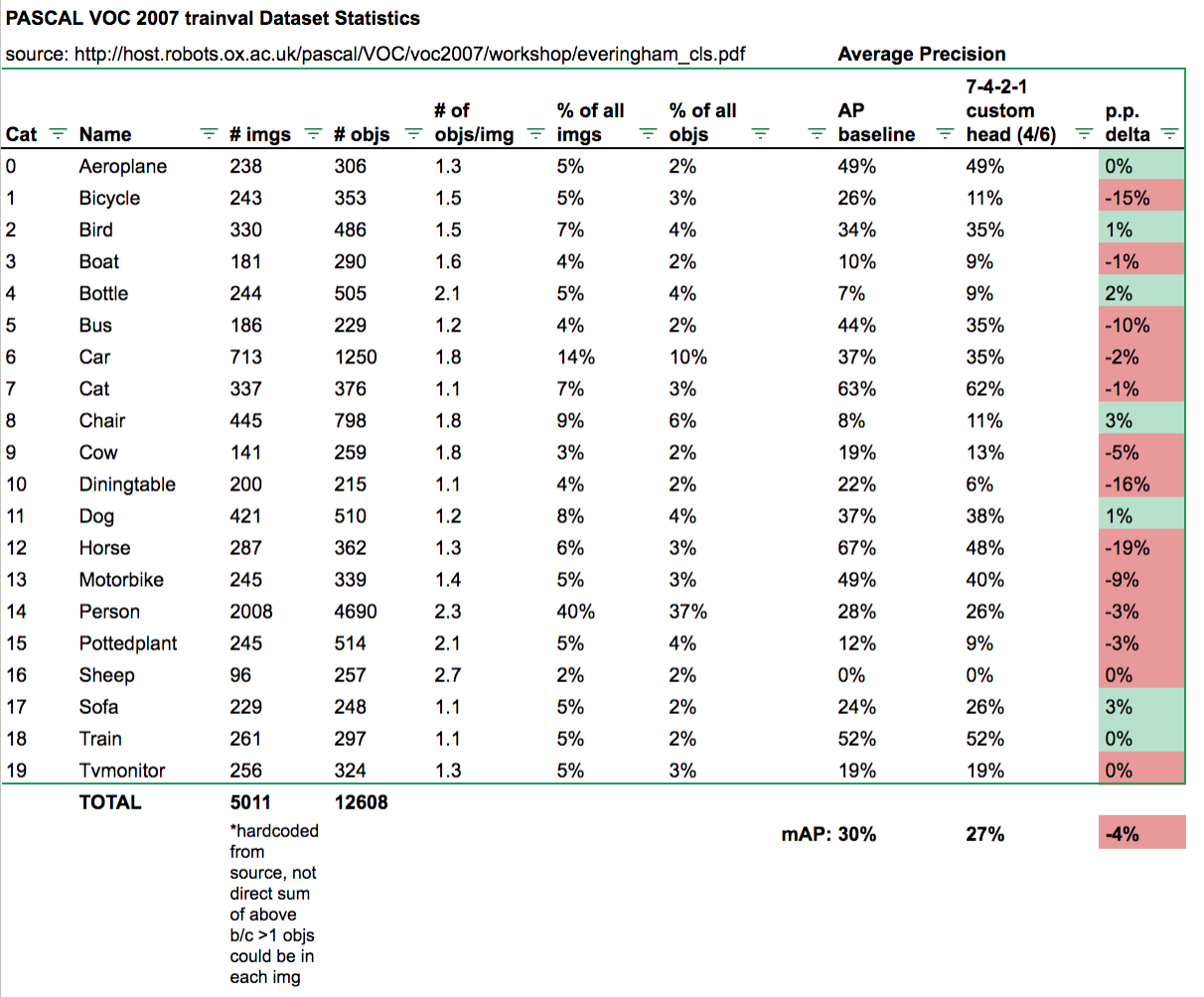
I’ve updated my gist with a lot of refactoring and computation speedup (much thanks to @sgugger for the prediction masking idea: got me from ~40mins -> 1-2mins to compute everything!). Also cleaned up the “model investigation” functions so they’re more obvious to view and use.
UPDATE:
I used these mAP metric functions to evaluate my coconut tree detector:
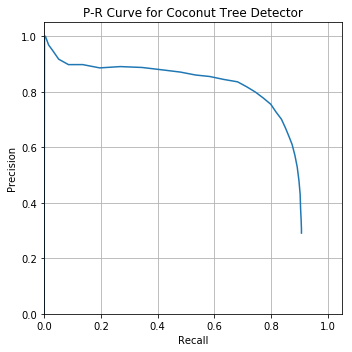
Looking pretty great! Average Precision of 74.9%
Out of curiosity, I plotted Precision and Recall on separate y-axes with the prediction confidence threshold on x-axis to visualize the P-R tradeoff as you move the confidence threshold up or down:
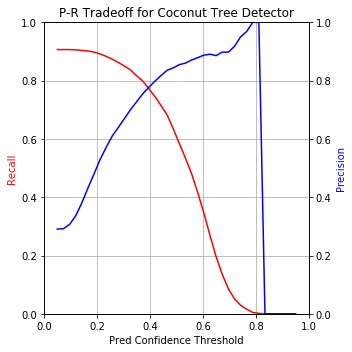
md_thres=0.4 seems like the best balance with ~80% on both precision and recall. Let’s visualize that performance on a few images:

Our detector caught every TP in these 3 images. In the last image, you could make a good argument (looking at the raw image) that the 1 FP is actually a TP that was missed by human annotators.