The Online Batch Selection for Faster Training of Neural Networks paper claims a 5x speedup on training. It’s super simple and should be easy to implement by just replacing the sampler object in DataLoader (like we do with SortSampler) for instance. Anyone want to try implementing this? Since it’s for our imagenet project, it would need to be done in the next day or two, so this is for someone that’s got a bit of free time.
An important part of the project would be confirming you can replicate the examples in the paper.
I can take a crack at it but i’m unlikely to have anything in a timely manner. I’m working on a tweak to language modelling right now, but I’m getting close to having something there that I can run an ablation on after which I could take a look.
It seems pretty straightforward, especially since there’s already a version in Lasagne that would just need to be ported.
I just read the paper, I still don’t really get what the Online piece means. Does that mean they vary the batch size during the training?
After rereading, they rank all the data and select it depending on whether or not a random number tells them to so the first batch would be larger and then they would get smaller and smaller if I’m reading it correctly. Is that how other people interpret their secret sauce?
Maybe for imagenet? I’m curious how this applies in general. It seems like the kind of thing that makes sense when your training, validation, and test set are very representative of each other.
Ok, so if there were 50 pictures, and a batch size of 5 (10 total batches), it could place the highest loss picture in multiple batches which would help the model learn that type of image because it would show up more frequently than one that was already training well on the model? So there is a chance that pictures that are already really well predicted with the model wouldn’t show up during that epoch at all. And then the last part of this is that once a picture is put into a batch, it reduces the chances that it will be put in another batch.
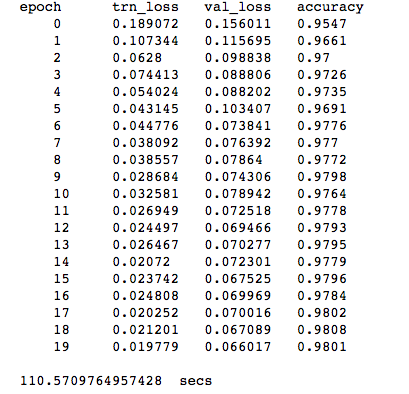
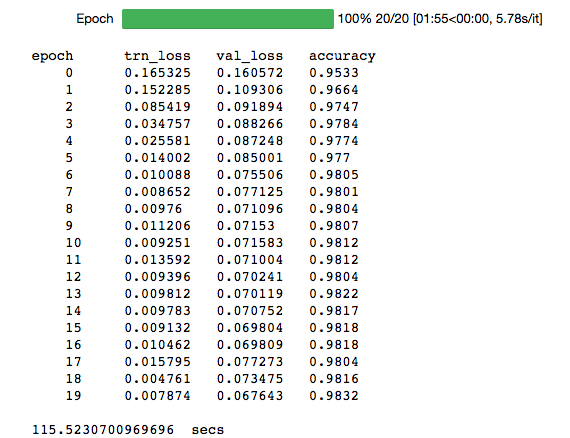
I’ve implemented a few naive versions of the weighted sampling idea yesterday and found the most success with mnist using multinomial with smoothing. Below is an example of a test run on mnist.
Before applying weighted sampling:
After applying weighted sampling:
I’ve uploaded the related code change into a gist, feel free to grab it and experiment on other datasets and diff params or perhaps someone can use it as a starter to implement the algorithm in the paper and compare.