I’ve written a few things for the fastai library while working on my project around Leslie Smith’s last article and I wanted to share them with you.
use_clr_beta : This is the implementation of Leslie Smith’s 1cycle policy as detailed here. He recommends to use a cycle like this one:
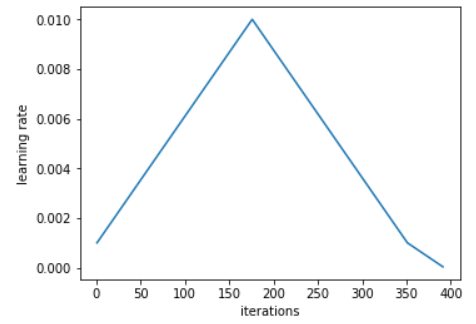
for the learning rates during the training: equal time growing and descending, and a bit of space left to get the learning rate really slow.
When used in fit, the value at the top (here 0.01) is the learning rate you pass. It should be the learning rate you pick with lr_find() and you can even choose values closer to the the minimum of the curve for super-convergence.
use_clr_beta takes two basic arguments, four if you want to add cyclical momentums. The first one is the ratio between the initial learning rate and the maximum one (typically 10 or 20). The second one is the percentage of the cycle you want to spend on the last part (on the picture 350 to 400), 10 seems to be a good pick once again.
Leslie Smith recommends to use cyclical momentums to complete this, which looks like this:
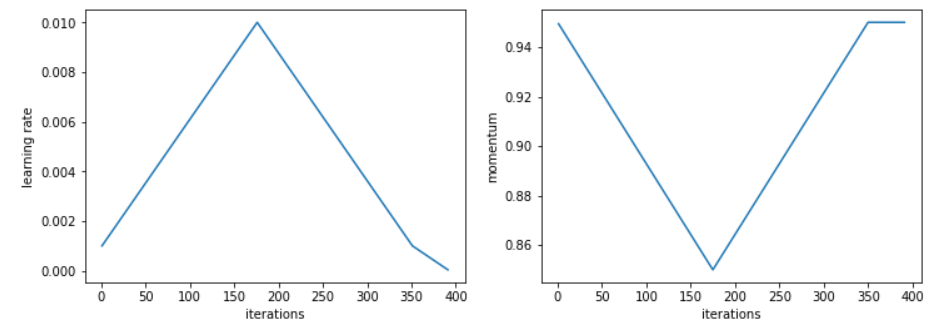
To use it, just pass two more arguments to use_clr_beta, the maximum value of momentum and the minimal value. All in all, a typical use would be:
use_clr_beta = (10,10,0.95,0.85)
I haven’t fully tested it with Adam yet, it’s originally intended for SGD with momentum.
plots: At the end of a very long cycle, if you want to do a plot with your validation accuracy or your metrics, you can find those in the variable learn.sched.val_losses and learn.sched.rec_metrics. They’re recorded at the end of each epoch.
lr_find2(): As I was trying to replicate some of the curves of Leslie Smith, I wrote a second version of lr_find(). It does roughly the same thing with two differences:
- it computes the validation loss and the metrics at the end of each batch, on the next batch of the validation set (so it’ll be a bit slower). At the end, you can find those in learn.sched.val_losses and learn.sched.rec_metrics once again.
- it doesn’t do a full batch but rather a certain number of iterations (100 by default). That’s enough for a plot, and it’ll loop again at the beginning of the training data if your dataset is small, or do less than a full batch if your dataset is large.
On top of the arguments of lr_find(), it has num_it (default 100), the number of iterations you want, and stop_dv (default True) that you can set to False if you don’t want the process to stop when the loss starts to go wild.
Once you’ve completed a learn.lr_find2(), you can plot the results with learn.sched.plot(), and on top of having the (training) loss vs the learning rate, you’ll also get the validation loss and the metrics. By default, it smoothes the data with a mean average (like fastai does for the training losses) but you can turn it down with smoothed=False.
Hope you find any of those functions helpful!
 ) and hope to give it a bit more time over the next couple of days.
) and hope to give it a bit more time over the next couple of days.