After implementing the mAP metric and ideas like more anchor boxes at smaller scales (28x28, 14x14, 7x7), fixing flatten_conv, and 1cycle training (use_clr_beta), here is the best model performance to date (& notebook link):
- Average Precision @ IoU of 50%: .81
- F1 score: .83
Visualized:
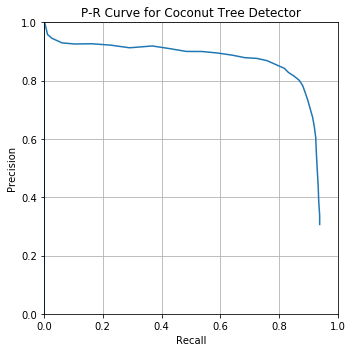
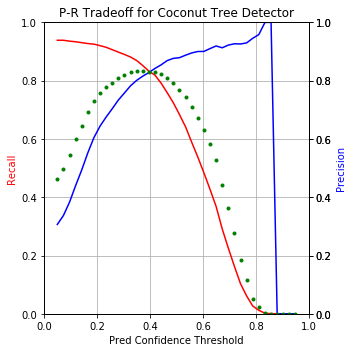
I find the below figure more intuitive to understand the balance between precision and recall at different confidence thresholds (F1 score = green dotted line):
The detector pretty much only misses trees at corners and edges of an image (where it’s only 25-50% view of a tree) or where there are clusters of multiple different-sized trees. Since these are tiled aerial images, we can likely further improve performance in post-process by stitching images and their predictions back together and removing repetitive predictions along the seams of tiles using another round of non-max suppression:

I’m testing out Feature Pyramid Network / RetinaNet-like implementations now but haven’t found performance improvement from them yet (perhaps because there’s not as big of a multi-scale problem with these top-down images taken from a consistent height - objects generally stay the same size). But FPNs will come in very handy when dealing with aerial imagery taken from different instruments with varying levels of spatial resolution.