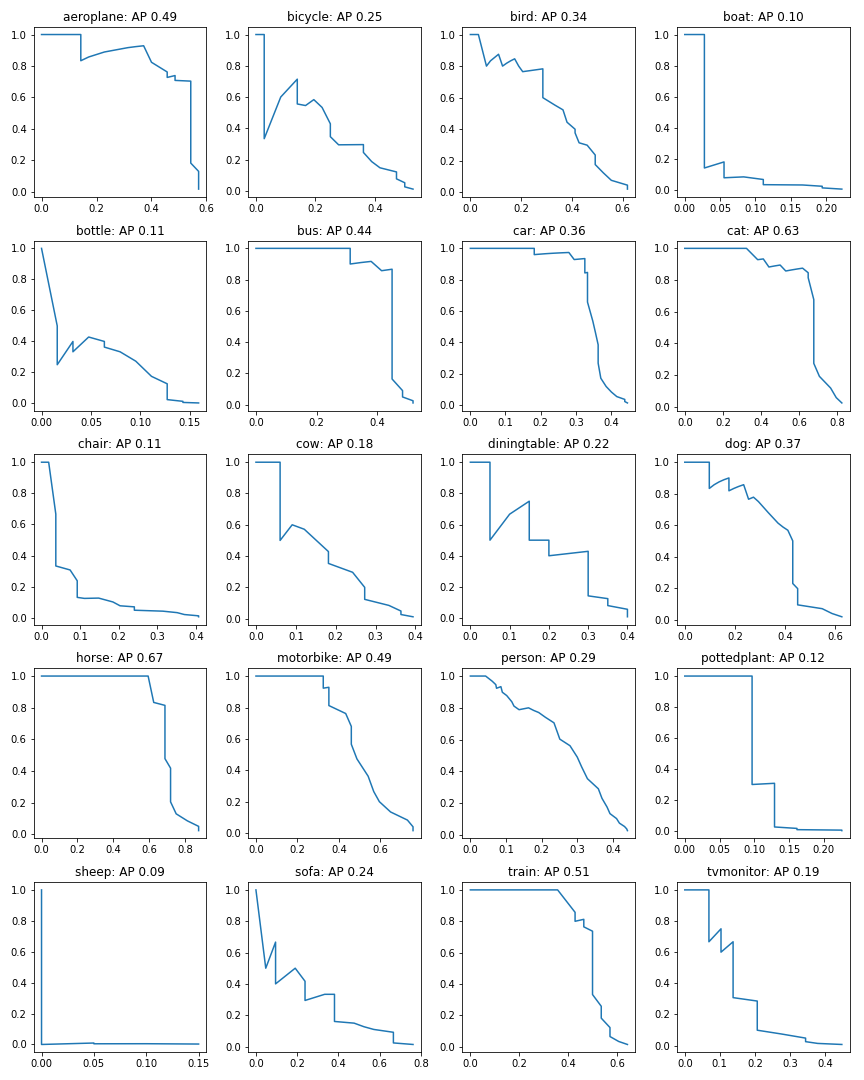
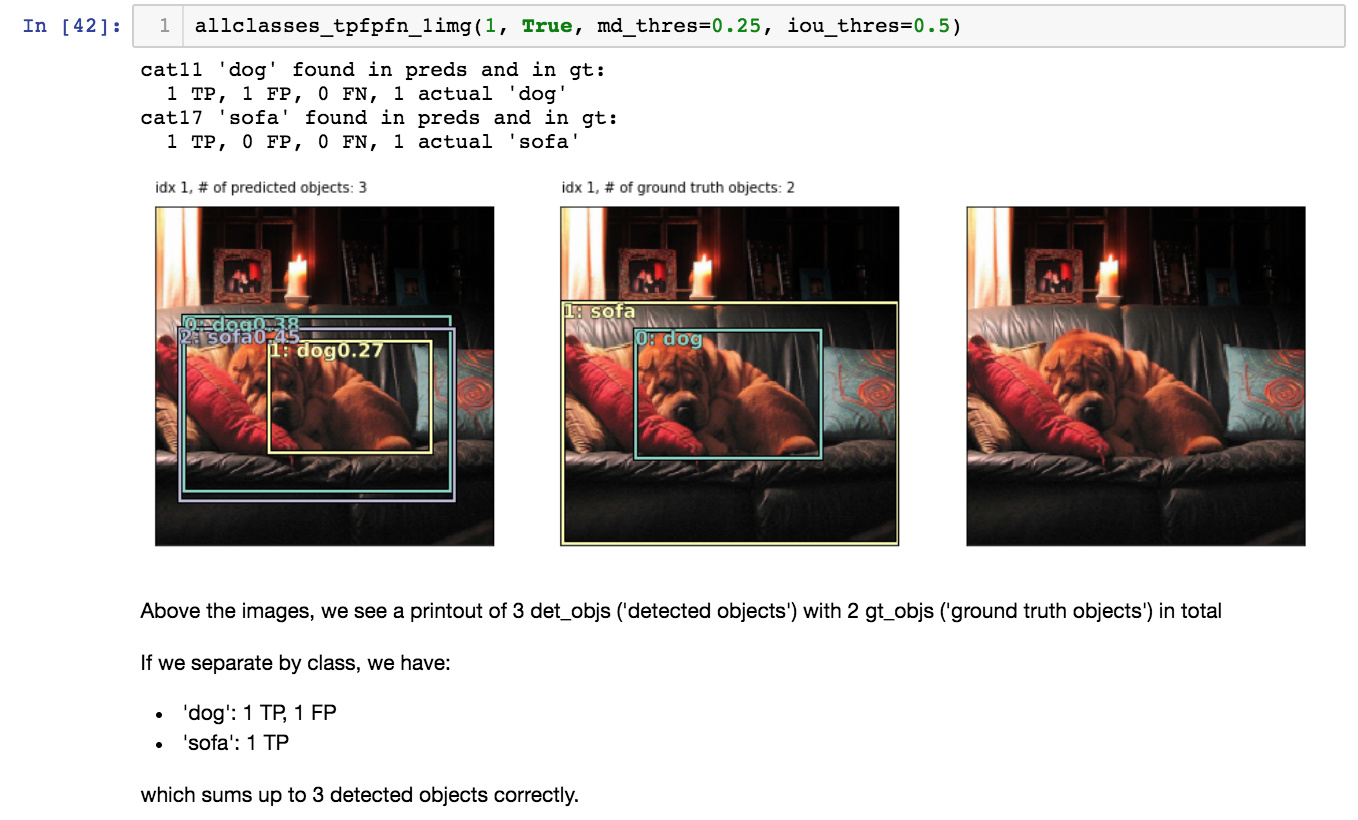
You take the calculation of precision separately for each class. So in your example:
- given 5 predictions (3 for class one, 2 for class two) and a ground truth of 1 object in class one (and assuming none in class two)
- for class one, you have 1 TP and 2 FP
- for class two, you have 0 TP and 2 FP
The calculation of precision (TP/(TP+FP)) would give:
- for class one: 1/3
- for class two: 0/2
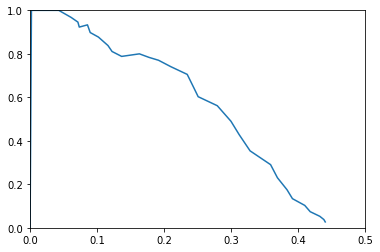
The gap in my understanding that I haven’t fully filled yet is that average precision is different than precision.
While precision is defined as TP/(TP+FP), average precision is related to the (approximate) area under the precision-recall curve for each class. Like this (fig from here):
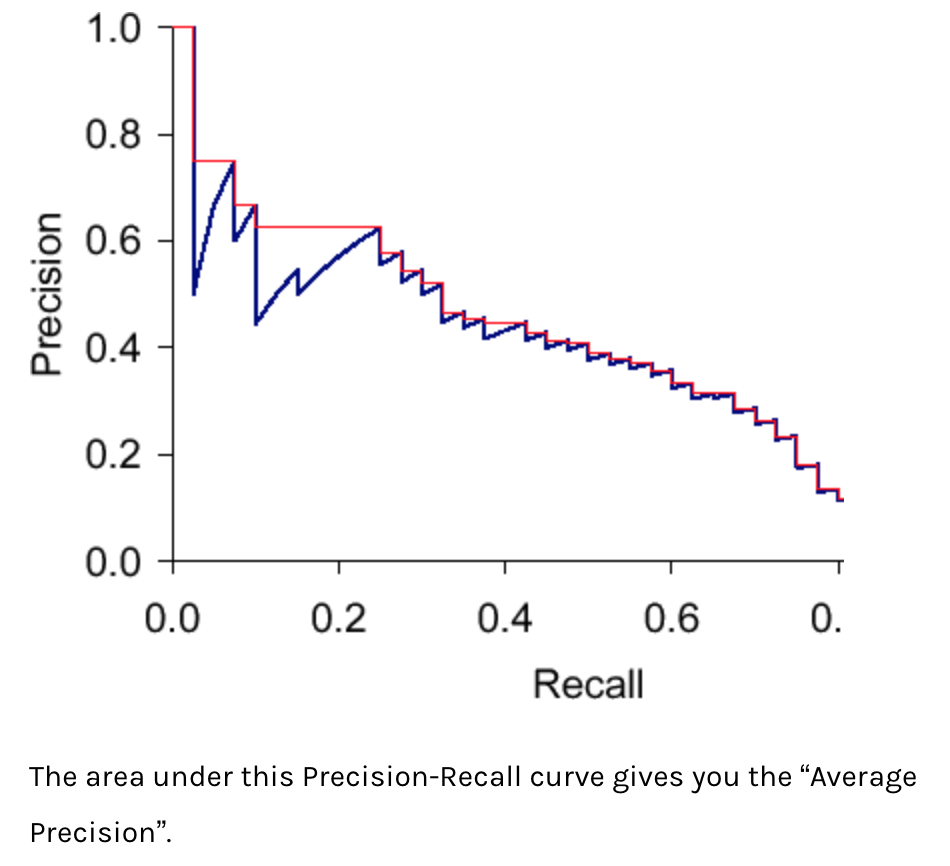
Found some good overviews of the difference here:
Best overview imo: https://medium.com/@timothycarlen/understanding-the-map-evaluation-metric-for-object-detection-a07fe6962cf3
https://sanchom.wordpress.com/tag/average-precision/
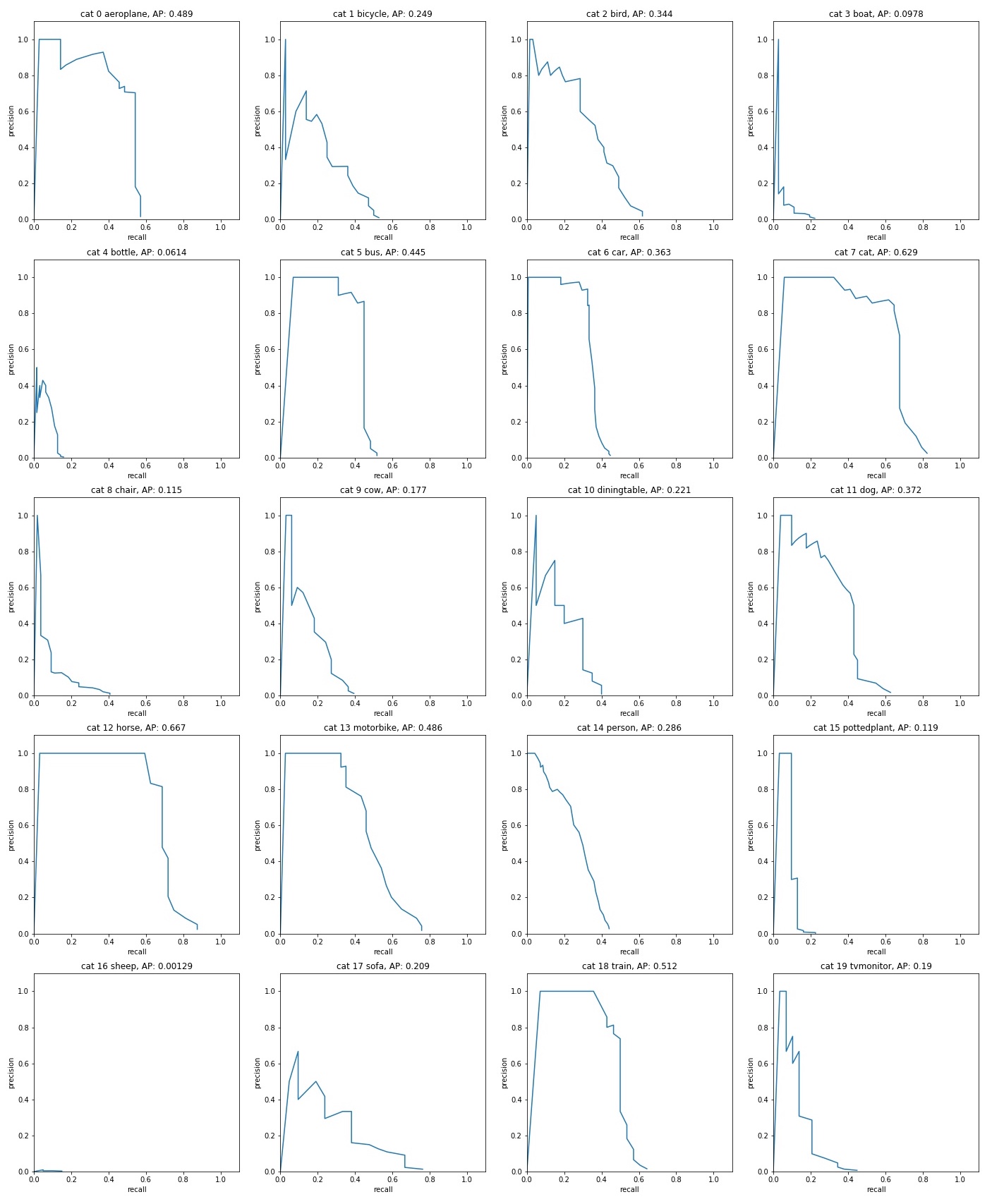
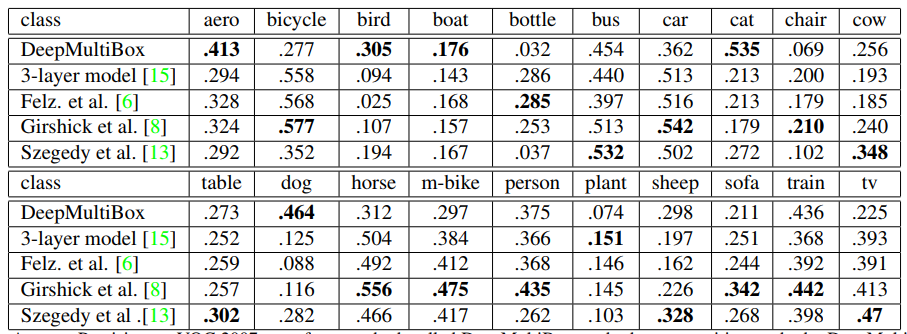
The mAP is then calculated as the mean of APs (quite a literal definition: the mean of the average precisions per class). You can also examine the AP for each class, like this (from here):
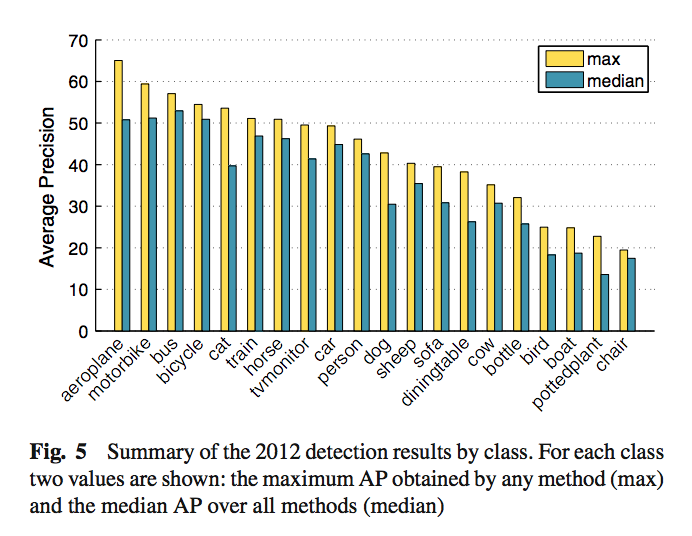
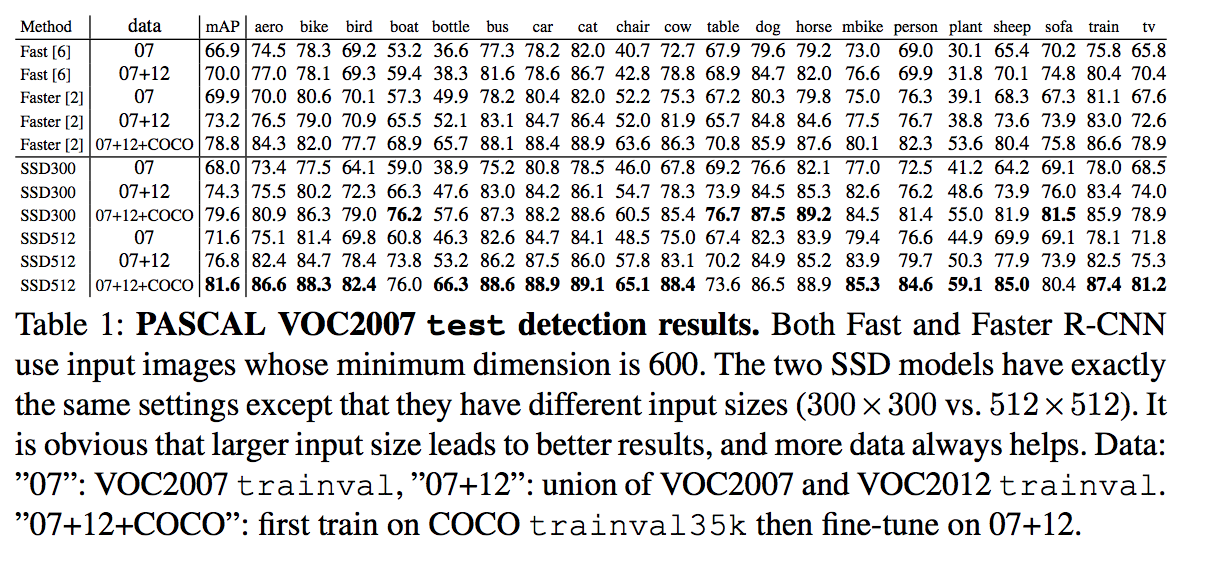
And in object detection papers, you often see something like mAP@[.5:.95] which denotes an average of the mAPs across different IoU thresholds for considering if a prediction counts as a TP. More on this here: computer vision - What does the notation mAP@[.5:.95] mean? - Data Science Stack Exchange
What a confusing phrase to say out loud: “average of the mean average precisions” ![]()
I’ve been working on fully understanding and implementing mAP as well. It’s more complex and ambiguous than I expected. Perhaps we should start a new thread on this?
Btw, here are some github references I’ve been using to check my implementation:
https://gist.github.com/tarlen5/008809c3decf19313de216b9208f3734
https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocotools/cocoeval.py
https://github.com/amdegroot/ssd.pytorch/blob/master/eval.py





 Maybe a pretrained model for one of the archs exists and we could run it to output predictions and calculate the mAP?
Maybe a pretrained model for one of the archs exists and we could run it to output predictions and calculate the mAP?